Jailbreaking Attacks vs. Content Safety Filters: How Far Are We in the LLM Safety Arms Race?
作者: Yuan Xin, Dingfan Chen, Linyi Yang, Michael Backes, Xiao Zhang
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-12-30
备注: 26 pages,11 tables, 7 figures
💡 一句话要点
系统评估LLM安全:关注越狱攻击在完整推理流程中的绕过情况
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 安全过滤器 内容安全 对抗性攻击
📋 核心要点
- 现有越狱攻击研究主要关注模型本身,忽略了实际部署中内容过滤器的作用,可能高估了攻击的成功率。
- 该论文系统评估了越狱攻击在包含输入和输出过滤的完整LLM推理流程中的有效性,更贴近实际应用场景。
- 实验表明,大多数越狱攻击可被安全过滤器检测,但过滤器在召回率和精确度方面仍有提升空间。
📝 摘要(中文)
随着大型语言模型(LLMs)的日益普及,确保其安全使用至关重要。越狱攻击,即通过对抗性提示绕过模型对齐以触发有害输出,带来了重大风险。现有研究表明,这些攻击在规避常见LLM方面具有很高的成功率。然而,之前的评估仅关注模型本身,忽略了完整的部署流程,该流程通常包含内容审核过滤器等额外的安全机制。为了弥补这一差距,我们首次对针对LLM安全对齐的越狱攻击进行了系统评估,评估了它们在完整推理流程(包括输入和输出过滤阶段)中的成功率。我们的研究结果揭示了两个关键见解:首先,几乎所有评估的越狱技术都可以被至少一个安全过滤器检测到,这表明先前的评估可能高估了这些攻击的实际成功率;其次,虽然安全过滤器在检测方面有效,但仍有改进召回率和精确度以进一步优化保护和用户体验的空间。我们强调了关键差距,并呼吁进一步完善LLM安全系统中的检测准确性和可用性。
🔬 方法详解
问题定义:该论文旨在解决现有LLM安全评估中忽略内容安全过滤器的问题。现有研究通常只关注越狱攻击绕过LLM本身的能力,而忽略了实际部署中通常会部署的输入和输出安全过滤器。这导致对越狱攻击实际威胁的评估可能存在偏差,高估了攻击的成功率。
核心思路:论文的核心思路是构建一个更全面的评估框架,该框架不仅考虑LLM本身,还包括输入和输出安全过滤器。通过在这个完整的推理流程中评估越狱攻击的成功率,可以更准确地了解攻击的实际威胁,并识别安全系统的薄弱环节。
技术框架:该论文的评估框架包含以下几个主要阶段:1) 越狱攻击生成:使用各种已知的越狱攻击技术生成对抗性提示。2) 输入过滤:将生成的提示输入到输入安全过滤器中进行检测。3) LLM推理:如果提示通过输入过滤器,则将其输入到LLM中进行推理。4) 输出过滤:将LLM生成的输出输入到输出安全过滤器中进行检测。5) 成功率评估:根据提示是否成功绕过所有安全机制(输入过滤器、LLM、输出过滤器)来评估越狱攻击的成功率。
关键创新:该论文最重要的技术创新点在于其评估框架的全面性。与以往只关注LLM本身的研究不同,该论文首次将输入和输出安全过滤器纳入评估范围,从而更准确地反映了实际部署场景中的安全状况。
关键设计:论文的关键设计包括:1) 多样化的越狱攻击集合:使用了多种不同的越狱攻击技术,以确保评估的全面性。2) 多种安全过滤器:评估了多种不同的输入和输出安全过滤器,以了解不同过滤器的性能。3) 细粒度的成功率评估:不仅评估了整体的越狱成功率,还评估了每个阶段的成功率,以便更深入地了解安全系统的薄弱环节。
🖼️ 关键图片
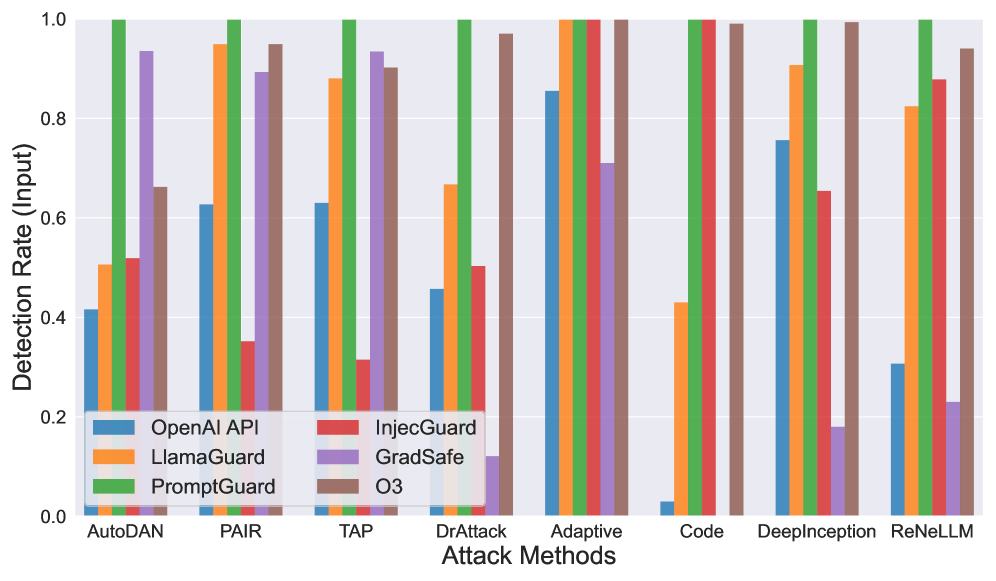
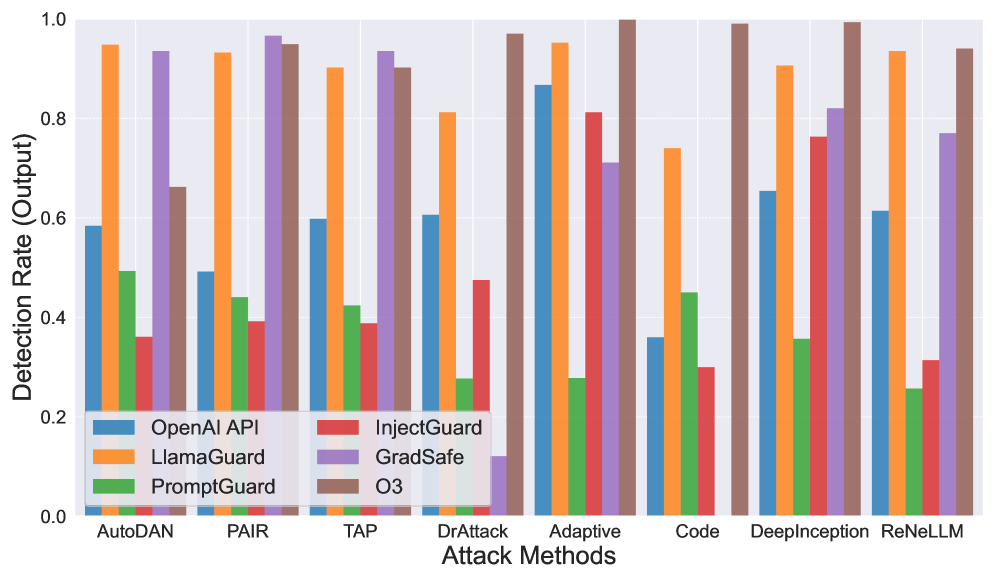

📊 实验亮点
实验结果表明,几乎所有评估的越狱攻击都可以被至少一个安全过滤器检测到,这表明先前的评估可能高估了这些攻击的实际成功率。同时,研究也发现安全过滤器在召回率和精确度方面仍有提升空间,为后续研究指明了方向。
🎯 应用场景
该研究成果可应用于提升LLM安全系统的鲁棒性。通过更全面地评估越狱攻击的威胁,可以帮助开发者更好地设计和部署安全过滤器,从而提高LLM在实际应用中的安全性,减少有害内容传播的风险。该研究对构建更安全、更可靠的AI系统具有重要意义。
📄 摘要(原文)
As large language models (LLMs) are increasingly deployed, ensuring their safe use is paramount. Jailbreaking, adversarial prompts that bypass model alignment to trigger harmful outputs, present significant risks, with existing studies reporting high success rates in evading common LLMs. However, previous evaluations have focused solely on the models, neglecting the full deployment pipeline, which typically incorporates additional safety mechanisms like content moderation filters. To address this gap, we present the first systematic evaluation of jailbreak attacks targeting LLM safety alignment, assessing their success across the full inference pipeline, including both input and output filtering stages. Our findings yield two key insights: first, nearly all evaluated jailbreak techniques can be detected by at least one safety filter, suggesting that prior assessments may have overestimated the practical success of these attacks; second, while safety filters are effective in detection, there remains room to better balance recall and precision to further optimize protection and user experience. We highlight critical gaps and call for further refinement of detection accuracy and usability in LLM safety systems.