PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
作者: Tianxin Xie, Wentao Lei, Guanjie Huang, Pengfei Zhang, Kai Jiang, Chunhui Zhang, Fengji Ma, Haoyu He, Han Zhang, Jiangshan He, Jinting Wang, Linghan Fang, Lufei Gao, Orkesh Ablet, Peihua Zhang, Ruolin Hu, Shengyu Li, Weilin Lin, Xiaoyang Feng, Xinyue Yang, Yan Rong, Yanyun Wang, Zihang Shao, Zelin Zhao, Chenxing Li, Shan Yang, Wenfu Wang, Meng Yu, Dong Yu, Li Liu
分类: cs.SD, cs.AI
发布日期: 2025-12-30
备注: 6 major physical dimensions, 50 fine-grained test points, 1,000 groups of variable-controlled test samples
💡 一句话要点
提出PhyAVBench基准,评估文本到音视频生成模型对物理规律的理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 文本到音视频生成 音频物理 基准测试 物理规律 音频生成 多模态学习 人工智能 音视频同步
📋 核心要点
- 现有文本到音视频生成模型缺乏对物理原理的理解,导致生成的声音不符合物理规律。
- 提出PhyAVBench基准,通过控制物理变量的文本提示,评估模型对音频物理变化的敏感性。
- PhyAVBench包含多种物理维度和日常场景,并使用真实世界视频,保证了评估的全面性和可靠性。
📝 摘要(中文)
本文提出了PhyAVBench,一个具有挑战性的音频物理敏感性基准,旨在系统地评估现有文本到音视频(T2AV)生成模型在音频物理基础方面的能力。由于现有T2AV模型对物理原理的理解有限,难以生成符合物理规律的声音。PhyAVBench包含1000组配对的文本提示,这些提示控制了物理变量,从而隐式地引起声音变化,从而能够细粒度地评估模型对潜在声学条件变化的敏感性。这种评估范式被称为音频物理敏感性测试(APST)。PhyAVBench不同于以往主要关注音视频同步的基准,它显式地评估模型对声音生成物理机制的理解,涵盖6个主要的音频物理维度、4个日常场景(音乐、音效、语音及其混合)和50个细粒度的测试点,范围从声音衍射等基本方面到亥姆霍兹共振等更复杂的现象。每个测试点由多组配对提示组成,每个提示都以至少20个新录制或收集的真实世界视频为基础,从而最大限度地降低了模型预训练期间数据泄露的风险。提示和视频都经过迭代,通过严格的人工参与的错误纠正和质量控制,以确保高质量。我们认为,只有真正掌握音频相关物理原理的模型才能生成物理上一致的音视频内容。我们希望PhyAVBench能够促进这个关键但很大程度上未被探索的领域的未来发展。
🔬 方法详解
问题定义:现有文本到音视频生成模型在生成音频时,往往忽略了声音产生的物理机制,导致生成的声音不真实、不自然。这些模型缺乏对物理规律的理解,无法根据场景中的物理变量(如物体大小、材质、距离等)生成相应的声音。因此,需要一个基准来评估模型对音频物理规律的理解能力,并推动相关研究的发展。
核心思路:PhyAVBench的核心思路是通过构建一系列包含物理变量的文本提示,并配以相应的真实世界视频,来测试模型生成音频的物理合理性。通过控制文本提示中的物理变量,可以隐式地改变声音的特性,从而评估模型是否能够捕捉到这些变化。这种方法能够细粒度地评估模型对不同物理维度和场景的理解能力。
技术框架:PhyAVBench的技术框架主要包括以下几个部分:1) 构建包含物理变量的文本提示;2) 收集或录制与文本提示对应的真实世界视频;3) 设计评估指标,用于衡量生成音频的物理合理性;4) 进行人工错误纠正和质量控制,确保数据的质量。整个流程旨在创建一个高质量、具有挑战性的基准,用于评估文本到音视频生成模型。
关键创新:PhyAVBench的关键创新在于其显式地关注音频生成的物理机制,并设计了一套细粒度的评估方法。与以往主要关注音视频同步的基准不同,PhyAVBench旨在评估模型对声音产生的物理原理的理解。此外,PhyAVBench还采用了真实世界视频,并进行了严格的人工质量控制,从而保证了数据的可靠性。
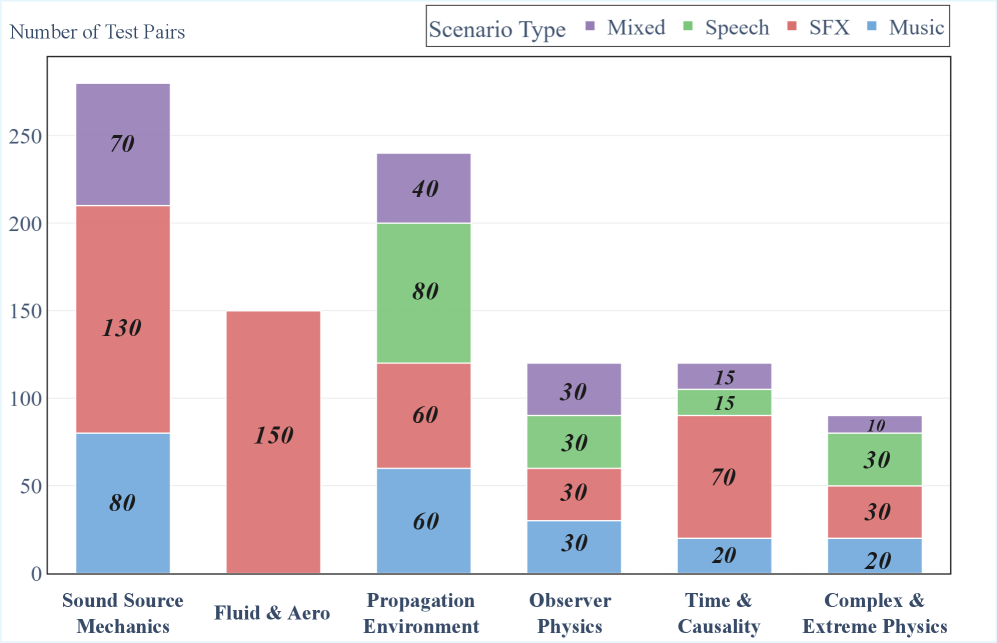
关键设计:PhyAVBench的关键设计包括:1) 涵盖6个主要的音频物理维度(如声音衍射、亥姆霍兹共振等);2) 包含4个日常场景(音乐、音效、语音及其混合);3) 包含50个细粒度的测试点;4) 每个测试点由多组配对提示组成,每个提示都以至少20个真实世界视频为基础;5) 采用人工参与的错误纠正和质量控制流程。
🖼️ 关键图片


📊 实验亮点
PhyAVBench基准包含1000组配对的文本提示,涵盖6个音频物理维度、4个日常场景和50个细粒度测试点。每个提示都以至少20个真实世界视频为基础,并通过人工质量控制保证数据质量。该基准能够细粒度地评估模型对音频物理变化的敏感性,为未来的研究提供了有力的工具。
🎯 应用场景
PhyAVBench的研究成果可应用于虚拟现实、世界建模、游戏和电影制作等领域。通过提高文本到音视频生成模型对物理规律的理解,可以生成更真实、更沉浸式的音视频内容,从而提升用户体验。此外,该研究还可以促进人工智能在音频领域的应用,例如智能音效设计、语音合成等。
📄 摘要(原文)
Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.