How Large Language Models Systematically Misrepresent American Climate Opinions
作者: Sola Kim, Jieshu Wang, Marco A. Janssen, John M. Anderies
分类: cs.CY, cs.AI
发布日期: 2025-12-29
💡 一句话要点
揭示大型语言模型在美国气候观点上的系统性偏差,尤其是在交叉身份群体中。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 气候观点 交叉身份 公平性 偏差分析
📋 核心要点
- 现有方法在利用大型语言模型分析公众意见时,未能充分考虑交叉身份群体,导致群体层面估计不准确。
- 该研究通过对比LLM生成的气候观点与真实人类回答,揭示了LLM在美国气候观点上的系统性偏差。
- 实验表明,LLM压缩了美国气候观点的多样性,且在不同种族和性别群体中存在不一致的偏差模式。
📝 摘要(中文)
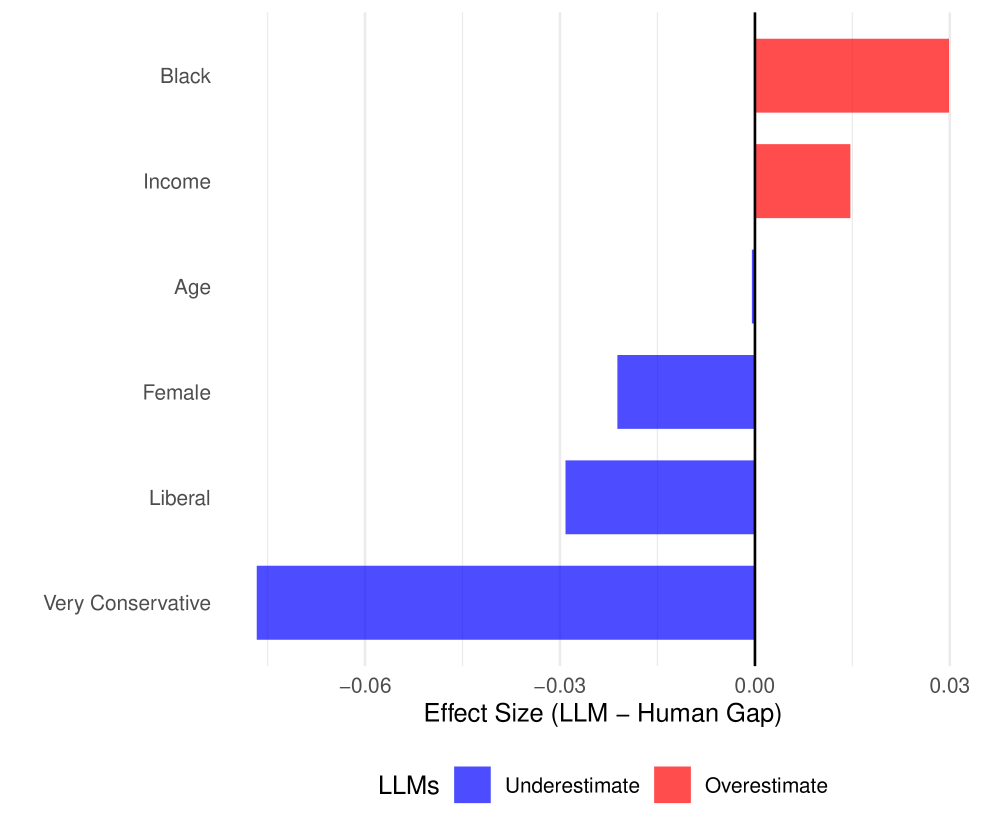
联邦机构和研究人员越来越多地使用大型语言模型来分析和模拟公众舆论。当AI介于公众和政策制定者之间时,跨交叉身份的准确性变得至关重要;不准确的群体层面估计可能会误导宣传、咨询和政策设计。虽然研究考察了LLM输出中的交叉性,但没有研究将这些输出与跨交叉身份的真实人类反应进行比较。气候政策就是这样一个领域,对于气候变化尤其紧迫,因为气候变化的观点存在争议且多样化。我们调查了LLM如何代表美国气候观点中的交叉模式。我们用来自一项具有全国代表性的美国气候观点调查的978名受访者的个人资料提示了六个LLM,并将AI生成的回答与20个问题的实际人类回答进行了比较。我们发现LLM似乎压缩了美国气候观点的多样性,预测不太关心的群体更关心,反之亦然。这种压缩是交叉的:LLM应用统一的性别假设,这与白人和西班牙裔美国人的现实相符,但错误地代表了黑人美国人,因为实际的性别模式不同。这些模式可能对标准审计方法不可见,可能会破坏公平的气候治理。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在模拟和分析公众气候观点时,对不同交叉身份群体(如种族、性别等)的观点存在系统性偏差的问题。现有方法未能充分考虑这些交叉身份的影响,导致LLM的输出结果与真实人类的观点存在显著差异,从而可能误导政策制定。
核心思路:论文的核心思路是通过将LLM的输出与真实人类的回答进行对比,从而揭示LLM在不同交叉身份群体中的偏差模式。通过分析这些偏差,可以更好地理解LLM的局限性,并为改进LLM的公平性和准确性提供指导。
技术框架:论文的技术框架主要包括以下几个步骤:1) 从一项具有全国代表性的美国气候观点调查中选取978名受访者;2) 使用这些受访者的个人资料作为提示,输入到六个不同的LLM中;3) 让LLM回答20个关于气候观点的问题;4) 将LLM的回答与真实人类的回答进行对比,分析不同交叉身份群体中的偏差模式。
关键创新:论文最重要的技术创新点在于,它首次将LLM的输出与真实人类的回答在交叉身份层面进行了对比,从而揭示了LLM在模拟公众气候观点时存在的系统性偏差。这种对比分析方法可以为评估LLM的公平性和准确性提供一种新的视角。
关键设计:论文的关键设计包括:1) 选取具有全国代表性的气候观点调查数据,保证了研究结果的可靠性;2) 使用多个不同的LLM,从而可以评估不同LLM的偏差模式;3) 关注交叉身份群体,从而可以揭示LLM在不同群体中的差异化表现;4) 使用20个关于气候观点的问题,从而可以全面评估LLM在气候观点方面的表现。
🖼️ 关键图片


📊 实验亮点
研究发现,LLM普遍压缩了美国气候观点的多样性,将不太关心的群体预测为更关心,反之亦然。更重要的是,这种压缩是交叉的,例如,LLM对白人和西班牙裔美国人应用了与现实相符的性别假设,但错误地代表了黑人美国人,因为实际的性别模式不同。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型在公共政策领域的应用,尤其是在涉及公众意见分析和模拟的场景中。通过识别和纠正LLM的偏差,可以提高政策制定的公平性和有效性,避免因不准确的群体层面估计而导致的误导。
📄 摘要(原文)
Federal agencies and researchers increasingly use large language models to analyze and simulate public opinion. When AI mediates between the public and policymakers, accuracy across intersecting identities becomes consequential; inaccurate group-level estimates can mislead outreach, consultation, and policy design. While research examines intersectionality in LLM outputs, no study has compared these outputs against real human responses across intersecting identities. Climate policy is one such domain, and this is particularly urgent for climate change, where opinion is contested and diverse. We investigate how LLMs represent intersectional patterns in U.S. climate opinions. We prompted six LLMs with profiles of 978 respondents from a nationally representative U.S. climate opinion survey and compared AI-generated responses to actual human answers across 20 questions. We find that LLMs appear to compress the diversity of American climate opinions, predicting less-concerned groups as more concerned and vice versa. This compression is intersectional: LLMs apply uniform gender assumptions that match reality for White and Hispanic Americans but misrepresent Black Americans, where actual gender patterns differ. These patterns, which may be invisible to standard auditing approaches, could undermine equitable climate governance.