Breaking Audio Large Language Models by Attacking Only the Encoder: A Universal Targeted Latent-Space Audio Attack
作者: Roee Ziv, Raz Lapid, Moshe Sipper
分类: cs.SD, cs.AI, cs.CR
发布日期: 2025-12-29
💡 一句话要点
提出一种通用目标潜在空间音频攻击,打破音频大语言模型编码器。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频大语言模型 对抗攻击 潜在空间攻击 编码器攻击 多模态安全
📋 核心要点
- 现有的音频大语言模型存在安全漏洞,容易受到对抗攻击,尤其是编码器层面的攻击。
- 该论文提出一种通用的潜在空间攻击方法,通过操纵音频的潜在表示来控制下游语言模型的输出。
- 实验表明,该方法在保持较低感知失真的同时,能够成功地诱导目标语言输出,揭示了编码器层面的安全风险。
📝 摘要(中文)
音频-语言模型结合了音频编码器和大语言模型,实现了多模态推理,但也引入了新的安全漏洞。我们提出了一种通用的目标潜在空间攻击,这是一种编码器级别的对抗性攻击,它操纵音频潜在表示,以在下游语言生成中诱导攻击者指定的输出。与先前的波形级别或输入特定的攻击不同,我们的方法学习一种通用的扰动,该扰动可以泛化到不同的输入和说话者,并且不需要访问语言模型。在Qwen2-Audio-7B-Instruct上的实验表明,该方法具有持续较高的攻击成功率和最小的感知失真,揭示了多模态系统编码器级别上一个关键且先前未被探索的攻击面。
🔬 方法详解
问题定义:现有的音频大语言模型容易受到对抗攻击,但以往的研究主要集中在波形层面的攻击,或者需要针对特定输入进行设计。这些方法泛化能力差,且可能需要访问下游的语言模型。因此,需要一种通用的、针对编码器层面的攻击方法,能够在不访问语言模型的情况下,诱导模型产生攻击者指定的目标输出。
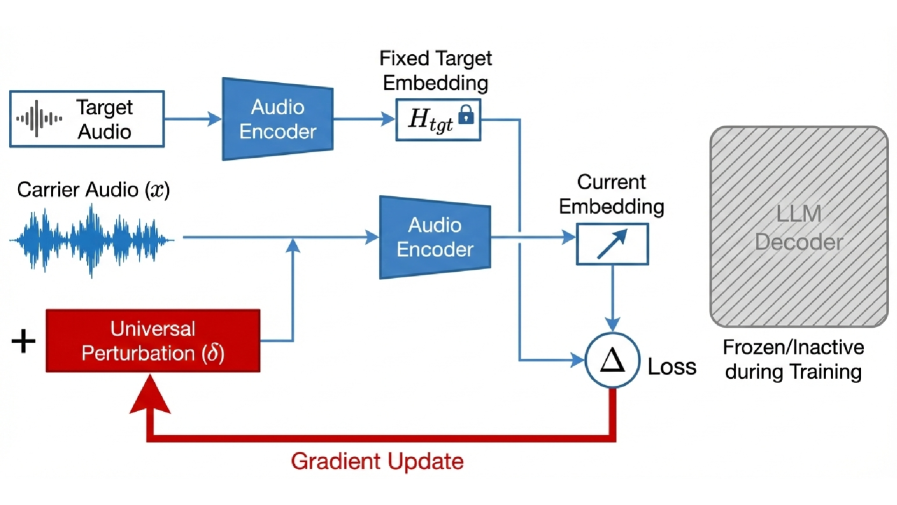
核心思路:该论文的核心思路是在音频编码器的潜在空间中引入一种通用的扰动,使得经过扰动后的音频潜在表示能够被下游的语言模型解码为攻击者指定的目标文本。这种扰动是通用的,意味着它可以应用于不同的音频输入和说话者,而不需要针对每个输入进行单独设计。
技术框架:该攻击框架主要包含以下几个步骤:1) 选择一个目标音频-语言模型,包括音频编码器和语言模型;2) 定义一个目标文本,即攻击者希望模型生成的文本;3) 在音频编码器的潜在空间中学习一个通用的扰动,该扰动能够使得经过扰动后的音频潜在表示被语言模型解码为目标文本;4) 将该通用扰动应用于新的音频输入,验证攻击的有效性。
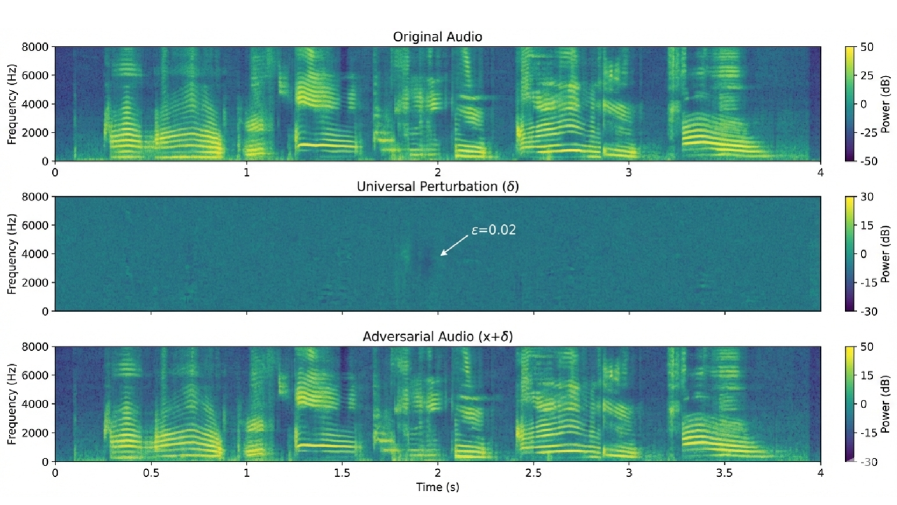
关键创新:该论文的关键创新在于提出了一种通用的、针对音频编码器潜在空间的攻击方法。与以往的攻击方法相比,该方法具有以下优势:1) 通用性:该扰动可以应用于不同的音频输入和说话者;2) 无需访问语言模型:攻击的训练过程不需要访问下游的语言模型;3) 隐蔽性:该扰动在音频波形层面不易察觉,能够保持较低的感知失真。
关键设计:在学习通用扰动时,使用了对抗训练的思想。具体来说,定义了一个损失函数,该损失函数包含两部分:一部分是使得经过扰动后的音频潜在表示被语言模型解码为目标文本的损失,另一部分是约束扰动大小的正则化项。通过优化该损失函数,可以学习到一个既能够诱导目标输出,又能够保持较低感知失真的通用扰动。具体参数设置和网络结构细节在论文中有详细描述,包括损失函数的权重系数、优化器的选择、以及扰动的约束范围等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Qwen2-Audio-7B-Instruct模型上取得了持续较高的攻击成功率,同时保持了最小的感知失真。这意味着攻击者可以在不引起用户注意的情况下,诱导模型生成攻击者指定的目标文本。该研究揭示了音频大语言模型编码器层面的一个关键且先前未被探索的攻击面。
🎯 应用场景
该研究成果可应用于评估和提升音频大语言模型的安全性。通过发现和理解编码器层面的攻击面,可以设计更鲁棒的音频编码器,提高模型抵抗对抗攻击的能力。此外,该研究也提醒开发者在构建多模态系统时,需要关注不同模态之间的安全边界,防止恶意攻击者利用编码器漏洞进行攻击。
📄 摘要(原文)
Audio-language models combine audio encoders with large language models to enable multimodal reasoning, but they also introduce new security vulnerabilities. We propose a universal targeted latent space attack, an encoder-level adversarial attack that manipulates audio latent representations to induce attacker-specified outputs in downstream language generation. Unlike prior waveform-level or input-specific attacks, our approach learns a universal perturbation that generalizes across inputs and speakers and does not require access to the language model. Experiments on Qwen2-Audio-7B-Instruct demonstrate consistently high attack success rates with minimal perceptual distortion, revealing a critical and previously underexplored attack surface at the encoder level of multimodal systems.