Prompt-Induced Over-Generation as Denial-of-Service: A Black-Box Attack-Side Benchmark
作者: Manu, Yi Guo, Kanchana Thilakarathna, Nirhoshan Sivaroopan, Jo Plested, Tim Lynar, Jack Yang, Wangli Yang
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-12-29 (更新: 2026-01-17)
备注: 17 pages, 5 figures
💡 一句话要点
提出黑盒攻击基准,研究提示诱导的大语言模型过度生成漏洞,可用于拒绝服务攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 拒绝服务攻击 提示攻击 黑盒攻击 过度生成
📋 核心要点
- 现有研究缺乏在黑盒场景下评估提示攻击诱导大模型过度生成,从而造成拒绝服务攻击的基准。
- 提出两种仅基于提示的攻击方法:EOGen通过进化搜索抑制EOS的token前缀,RL-GOAL使用强化学习生成目标长度的前缀。
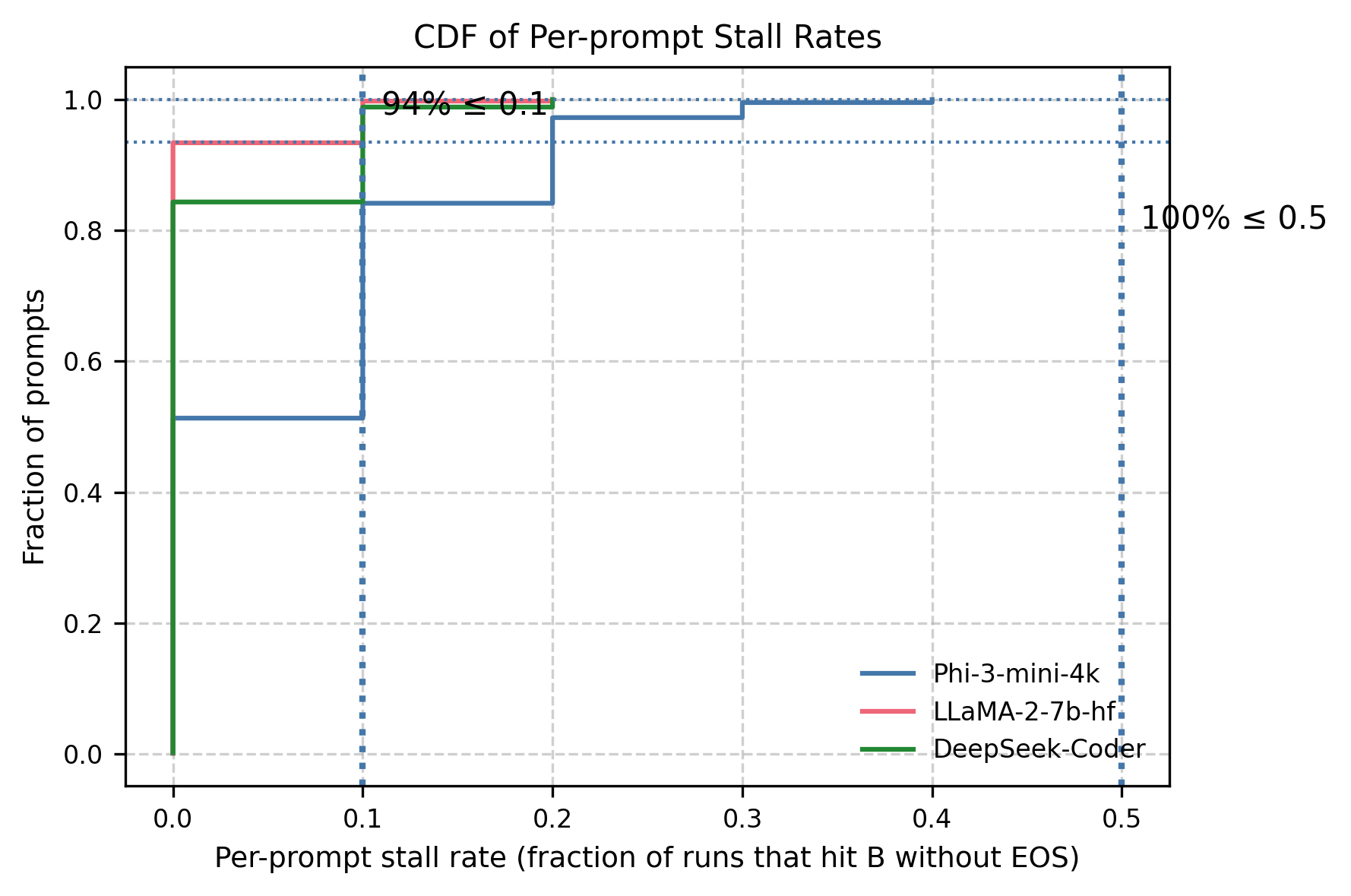
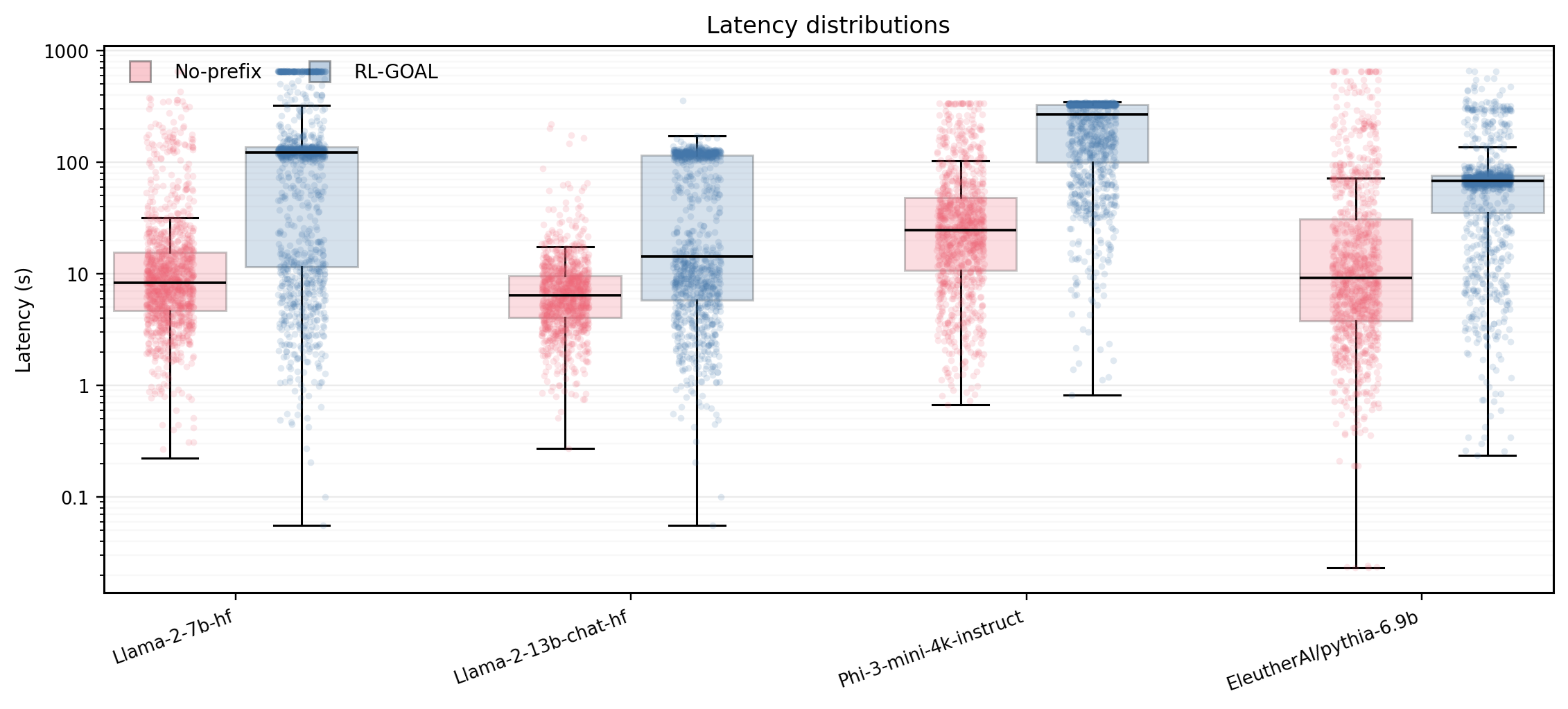
- 实验表明,EOGen和RL-GOAL均能有效诱导大模型过度生成,RL-GOAL的攻击效果更显著,成功率更高。
📝 摘要(中文)
大型语言模型(LLMs)可能被诱导进入过度生成状态,在产生序列结束(EOS)token之前输出数千个token。这会降低答案质量,增加延迟和成本,并可能被武器化为拒绝服务(DoS)攻击。最近的工作已经开始研究DoS风格的提示攻击,但通常侧重于单一攻击算法或假设白盒访问,缺乏一个攻击侧基准,用于在黑盒、仅查询模式下比较基于提示的攻击者,并具有已知的tokenizer。我们引入了这样一个基准,并研究了两个仅提示攻击者。第一个是进化过度生成提示搜索(EOGen),它在token空间中搜索抑制EOS并诱导长延续的前缀。第二个是目标条件强化学习攻击者(RL-GOAL),它训练一个网络来生成以目标长度为条件的前缀。为了描述行为,我们引入了过度生成因子(OGF):生成token与模型上下文窗口的比率,以及stall和延迟摘要。EOGen发现了短前缀攻击,使Phi-3的OGF达到1.39 +/- 1.14 (Success@>=2: 25.2%);RL-GOAL几乎使严重程度翻倍至OGF = 2.70 +/- 1.43 (Success@>=2: 64.3%),并在46%的试验中导致预算耗尽的非终止。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)容易受到提示攻击,导致过度生成token,从而造成拒绝服务(DoS)的问题。现有方法通常假设白盒访问或仅关注单一攻击算法,缺乏一个黑盒攻击基准来系统地评估和比较不同的提示攻击方法。
核心思路:论文的核心思路是构建一个黑盒攻击基准,并提出两种仅基于提示的攻击方法,通过精心设计的提示诱导LLM过度生成,从而评估LLM的脆弱性和攻击方法的有效性。这样设计可以模拟真实的攻击场景,并为防御提供参考。
技术框架:整体框架包含以下几个关键部分:1) 黑盒攻击基准:定义了评估指标,如过度生成因子(OGF)和成功率,以及实验设置。2) EOGen攻击方法:使用进化算法在token空间中搜索能够抑制EOS token并诱导长延续的前缀。3) RL-GOAL攻击方法:使用强化学习训练一个网络,生成以目标长度为条件的前缀。4) 评估与分析:在不同的LLM上评估两种攻击方法的性能,并分析其行为。
关键创新:论文的关键创新在于:1) 提出了一个黑盒攻击基准,用于系统地评估和比较提示攻击对LLM过度生成的影响。2) 提出了两种有效的仅基于提示的攻击方法:EOGen和RL-GOAL,能够在黑盒场景下诱导LLM过度生成。3) 引入了过度生成因子(OGF)作为评估LLM过度生成程度的指标。与现有方法相比,该研究更关注黑盒攻击场景,并提供了更全面的评估和分析。
关键设计:EOGen使用进化算法,目标是最大化生成token的数量,同时最小化EOS token的出现。RL-GOAL使用强化学习,奖励函数设计为鼓励生成接近目标长度的序列,并惩罚过早终止。具体来说,RL-GOAL使用Transformer作为策略网络,输入是当前生成的token序列,输出是下一个token的概率分布。训练过程中,使用策略梯度算法优化策略网络。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EOGen能够发现短前缀攻击,使Phi-3的OGF达到1.39 +/- 1.14 (Success@>=2: 25.2%)。RL-GOAL的攻击效果更显著,OGF达到2.70 +/- 1.43 (Success@>=2: 64.3%),并在46%的试验中导致预算耗尽的非终止。这些结果表明,即使在黑盒场景下,LLM也容易受到提示攻击,导致过度生成。
🎯 应用场景
该研究成果可应用于评估和提高大型语言模型的安全性,防御提示注入攻击和拒绝服务攻击。通过构建更鲁棒的LLM,可以减少恶意用户利用提示诱导模型过度生成,从而保证服务的可用性和稳定性。此外,该研究还可以促进对LLM脆弱性的更深入理解,为开发更有效的防御机制提供指导。
📄 摘要(原文)
Large Language Models (LLMs) can be driven into over-generation, emitting thousands of tokens before producing an end-of-sequence (EOS) token. This degrades answer quality, inflates latency and cost, and can be weaponized as a denial-of-service (DoS) attack. Recent work has begun to study DoS-style prompt attacks, but typically focuses on a single attack algorithm or assumes white-box access, without an attack-side benchmark that compares prompt-based attackers in a black-box, query-only regime with a known tokenizer. We introduce such a benchmark and study two prompt-only attackers. The first is an Evolutionary Over-Generation Prompt Search (EOGen) that searches the token space for prefixes that suppress EOS and induce long continuations. The second is a goal-conditioned reinforcement learning attacker (RL-GOAL) that trains a network to generate prefixes conditioned on a target length. To characterize behavior, we introduce Over-Generation Factor (OGF): the ratio of produced tokens to a model's context window, along with stall and latency summaries. EOGen discovers short-prefix attacks that raise Phi-3 to OGF = 1.39 +/- 1.14 (Success@>=2: 25.2%); RL-GOAL nearly doubles severity to OGF = 2.70 +/- 1.43 (Success@>=2: 64.3%) and drives budget-hit non-termination in 46% of trials.