MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
作者: Jiawei Chen, Xintian Shen, Lihao Zheng, Zhenwei Shao, Handong Cui, Chaoqun Du, Li Gong, Feng Gu, Xuefeng Hao, Wei He, Jiabang He, Yi Hu, Bin Huang, Shanshan Li, Qizhen Li, Jing Luo, Zide Liu, Xiaobo Liu, Ning Mao, Lifu Mu, Xuhao Pan, Zhiheng Qu, Chang Ren, Xudong Rao, Haoyi Sun, Qian Wang, Shuai Wang, Zhichao Wang, Wei Wang, Lian Wen, Jiqing Zhan, Hongfu Yang, Sheng Yang, Jiajun Yang, Pengfei Yu, Hongyuan Zhang, Bin Zhang, Chunpeng Zhou, Zheng Zhou, Shucheng Zhou, Shuo Xie, Yun Zhu, Hao Ma, Tao Wei, Pan Zhou, Wei Chen
分类: cs.AI
发布日期: 2025-12-29 (更新: 2026-01-07)
备注: Technique Report
💡 一句话要点
提出MindWatcher,一种集成多模态工具的智能推理Agent,用于解决复杂决策任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具集成推理 多模态学习 链式思考 智能Agent 图像检索
📋 核心要点
- 传统基于工作流的Agent在解决需要工具调用的实际问题时智能有限,面临复杂决策任务的挑战。
- MindWatcher采用交错思考和多模态CoT推理,自主决定工具调用,无需人工干预,提升了决策能力。
- 实验表明MindWatcher通过优异的工具调用,性能匹配或超过更大模型,并揭示了Agent训练的关键见解。
📝 摘要(中文)
本文介绍了一种名为MindWatcher的工具集成推理(TIR)Agent,它集成了交错思考和多模态链式思考(CoT)推理。MindWatcher能够自主决定是否以及如何调用各种工具,并协调它们的使用,无需人工提示或工作流程。交错思考范式使模型能够在任何中间阶段在思考和工具调用之间切换,而其多模态CoT能力允许在推理过程中处理图像,从而产生更精确的搜索结果。我们实现了自动数据审计和评估流程,并辅以手动策划的高质量数据集进行训练,构建了一个名为MindWatcher-Evaluate Bench(MWE-Bench)的基准来评估其性能。MindWatcher配备了一套全面的辅助推理工具,使其能够解决广泛领域的多模态问题。一个大规模、高质量的本地图像检索数据库,涵盖汽车、动物和植物等八个类别,使模型即使在规模较小的情况下也能实现强大的对象识别能力。最后,我们为MindWatcher设计了一个更高效的训练基础设施,提高了训练速度和硬件利用率。实验表明,MindWatcher通过卓越的工具调用,能够匹配甚至超过更大或更新模型的性能,并且揭示了Agent训练的关键见解,例如Agent强化学习中的遗传继承现象。
🔬 方法详解
问题定义:现有基于工作流的Agent在处理需要复杂工具调用的现实世界问题时,表现出明显的智能局限性。它们通常依赖于预定义的流程,无法灵活地根据环境变化和任务需求自主选择和调用合适的工具。这导致了在多步骤交互和复杂决策任务中的效率低下和性能瓶颈。
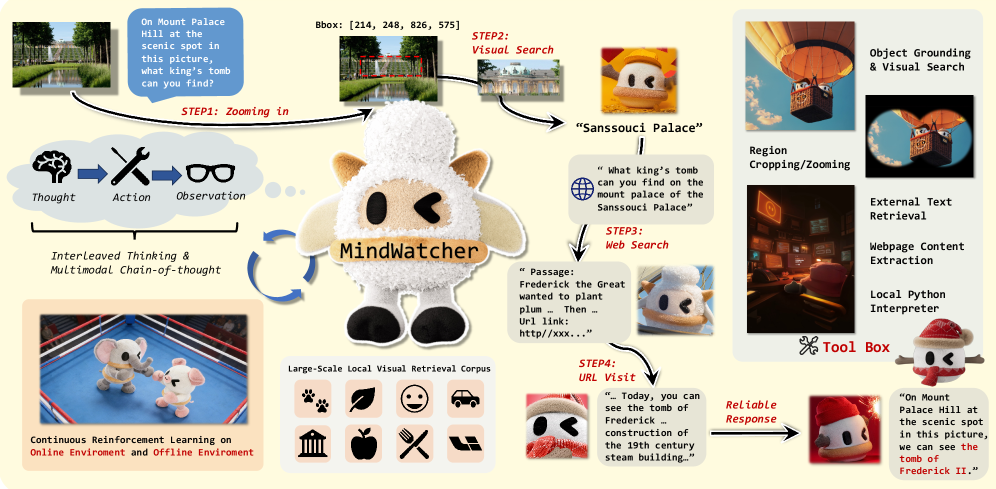
核心思路:MindWatcher的核心思路是赋予Agent自主推理和工具调用的能力,使其能够像人类一样,在思考过程中根据需要灵活地使用各种工具。通过集成交错思考和多模态链式思考(CoT)推理,Agent可以在思考和工具调用之间自由切换,并利用图像信息进行更精确的推理和搜索。这种设计旨在模拟人类解决问题的过程,提高Agent的适应性和效率。
技术框架:MindWatcher的整体框架包含以下几个主要模块:1) 交错思考模块:允许Agent在思考和工具调用之间灵活切换,根据当前状态和任务需求决定下一步行动。2) 多模态CoT推理模块:利用链式思考的方式进行推理,并在推理过程中处理图像信息,以获得更准确的上下文理解。3) 工具集成模块:集成了各种辅助推理工具,例如图像检索、搜索引擎等,为Agent提供解决问题的必要资源。4) 本地图像检索数据库:提供大规模、高质量的图像数据,支持Agent进行对象识别和图像理解。
关键创新:MindWatcher的关键创新在于其交错思考的范式和多模态CoT推理能力。传统的Agent通常采用固定的工作流程,无法在思考过程中灵活地调用工具。MindWatcher通过交错思考,打破了这种限制,使Agent能够根据需要随时调用工具,从而提高了解决问题的效率和灵活性。此外,多模态CoT推理能力使Agent能够利用图像信息进行更精确的推理,进一步提升了性能。
关键设计:MindWatcher的关键设计包括:1) 交错思考的实现方式:具体如何设计Agent的决策机制,使其能够在思考和工具调用之间自由切换,例如使用强化学习或策略网络。2) 多模态CoT推理的实现方式:如何将图像信息融入到链式思考的过程中,例如使用视觉编码器提取图像特征,并将其与文本信息进行融合。3) 本地图像检索数据库的构建:如何构建大规模、高质量的图像数据库,并设计高效的检索算法,以支持Agent进行对象识别和图像理解。4) 训练基础设施的优化:如何设计高效的训练流程,提高训练速度和硬件利用率。
🖼️ 关键图片
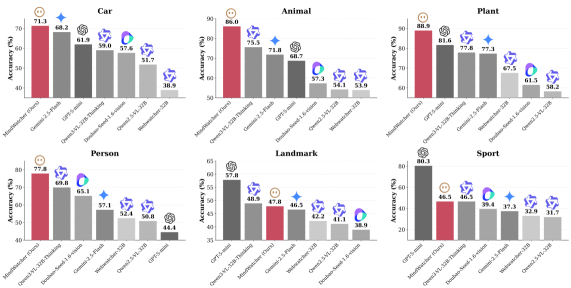

📊 实验亮点
实验结果表明,MindWatcher在MWE-Bench基准测试中表现出色,通过卓越的工具调用,能够匹配甚至超过更大或更新模型的性能。此外,研究还揭示了Agent强化学习中的遗传继承现象,为Agent训练提供了新的思路。具体性能数据和对比基线信息未知。
🎯 应用场景
MindWatcher具有广泛的应用前景,例如智能客服、自动驾驶、医疗诊断、工业自动化等领域。它可以帮助人们更高效地解决复杂问题,提高工作效率,并降低成本。未来,随着技术的不断发展,MindWatcher有望成为各行各业的重要工具,推动人工智能的普及和应用。
📄 摘要(原文)
Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.