InSPO: Unlocking Intrinsic Self-Reflection for LLM Preference Optimization
作者: Yu Li, Tian Lan, Zhengling Qi
分类: cs.AI, cs.LG
发布日期: 2025-12-29 (更新: 2025-12-30)
💡 一句话要点
InSPO:通过内省自反优化提升LLM偏好对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 偏好优化 直接偏好优化 自反学习 全局最优策略
📋 核心要点
- 现有DPO方法依赖任意建模选择,导致模型行为受参数化伪影影响,未能反映真实偏好。
- InSPO通过推导全局最优策略,同时考虑上下文和替代响应,实现更准确的偏好对齐。
- 实验结果表明,InSPO在胜率和长度控制指标上均优于DPO,验证了其有效性。
📝 摘要(中文)
直接偏好优化(DPO)及其变体因其简单性和离线稳定性已成为对齐大型语言模型的标准方法。然而,我们发现了两个根本限制。首先,最优策略依赖于任意建模选择(标量化函数、参考策略),导致行为反映参数化伪影而非真实偏好。其次,孤立地处理响应生成未能利用成对数据中的比较信息,从而未能挖掘模型内在的自反能力。为了解决这些问题,我们提出了内在自反偏好优化(InSPO),推导出一种全局最优策略,该策略同时以上下文和替代响应为条件。我们证明了这种公式优于DPO/RLHF,同时保证了对标量化和参考选择的不变性。InSPO作为一种即插即用的增强方法,无需架构更改或推理开销。实验表明,在胜率和长度控制指标方面均有持续改进,验证了解锁自反能力可以产生更稳健、更符合人类偏好的LLM。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在对齐大型语言模型时存在两个主要问题。一是最优策略依赖于人为设定的标量化函数和参考策略,导致模型行为受到这些参数选择的影响,而非真实的人类偏好。二是DPO孤立地处理响应生成,忽略了成对数据中蕴含的比较信息,未能充分利用模型的自反能力。
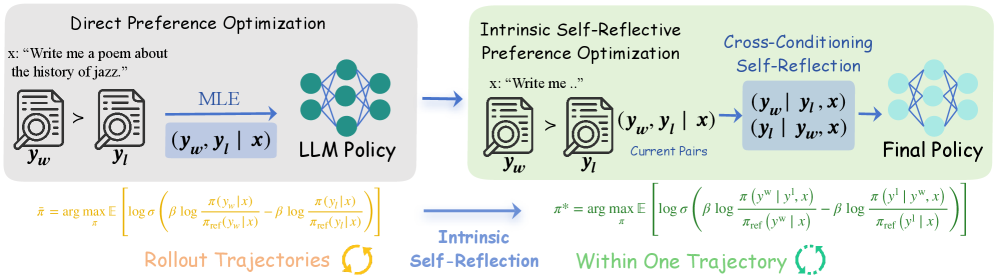
核心思路:InSPO的核心思路是通过引入“内在自反”机制,让模型在生成响应时,不仅考虑上下文信息,还要同时考虑其他可能的替代响应。通过比较不同响应的优劣,模型可以更好地理解人类的偏好,从而生成更符合人类期望的输出。这种方法旨在消除对任意建模选择的依赖,并充分利用成对数据中的比较信息。
技术框架:InSPO的整体框架是在DPO的基础上进行改进。它仍然采用离线数据进行训练,但优化目标函数不同。InSPO推导出一个全局最优策略,该策略以上下文和替代响应为条件。具体来说,InSPO的目标是最大化模型生成更符合人类偏好的响应的概率,同时最小化生成不符合人类偏好的响应的概率。
关键创新:InSPO最重要的创新在于其“内在自反”机制。与DPO只关注单个响应的生成不同,InSPO同时考虑多个响应,并通过比较这些响应来学习人类偏好。这种方法可以更好地利用成对数据中的比较信息,从而提高模型的对齐效果。此外,InSPO的公式保证了对标量化函数和参考策略的不变性,从而消除了对任意建模选择的依赖。
关键设计:InSPO的关键设计在于其优化目标函数。该目标函数基于一个理论推导,旨在找到一个全局最优策略,该策略以上下文和替代响应为条件。具体来说,该目标函数包含两项:一项是最大化模型生成更符合人类偏好的响应的概率,另一项是最小化模型生成不符合人类偏好的响应的概率。通过优化这个目标函数,InSPO可以学习到更准确的人类偏好模型。
🖼️ 关键图片
📊 实验亮点
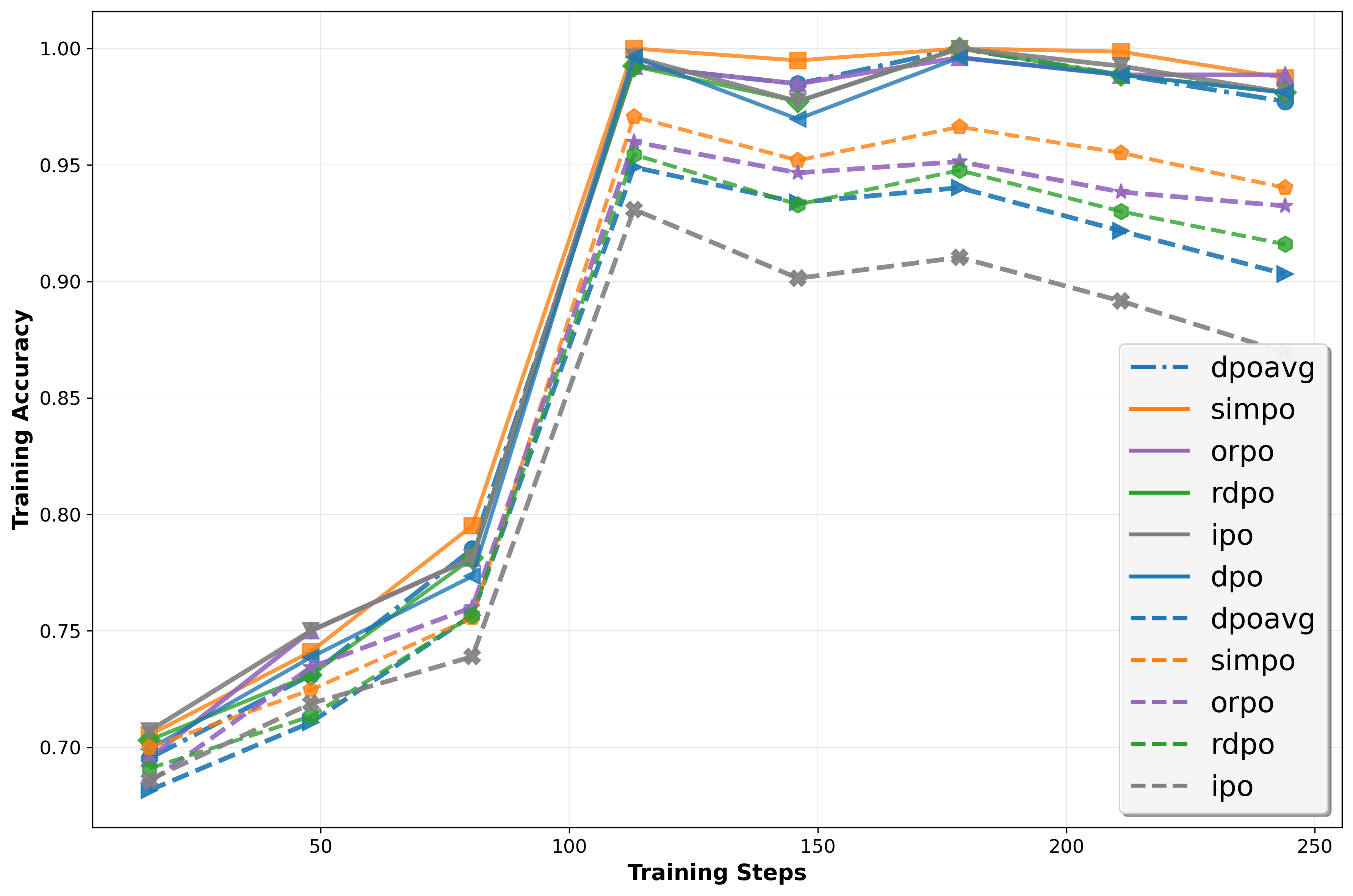
实验结果表明,InSPO在多个数据集上均优于DPO和RLHF等基线方法。在胜率方面,InSPO取得了显著提升,表明其生成的响应更符合人类偏好。此外,InSPO在长度控制指标方面也表现出色,表明其可以更好地控制生成文本的长度,从而满足不同应用场景的需求。
🎯 应用场景
InSPO可广泛应用于各种需要对齐大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过提升模型对人类偏好的理解和遵循能力,InSPO可以帮助构建更安全、更可靠、更符合人类价值观的AI系统。未来,InSPO有望成为LLM对齐的标准方法之一。
📄 摘要(原文)
Direct Preference Optimization (DPO) and its variants have become standard for aligning Large Language Models due to their simplicity and offline stability. However, we identify two fundamental limitations. First, the optimal policy depends on arbitrary modeling choices (scalarization function, reference policy), yielding behavior reflecting parameterization artifacts rather than true preferences. Second, treating response generation in isolation fails to leverage comparative information in pairwise data, leaving the model's capacity for intrinsic self-reflection untapped. To address it, we propose Intrinsic Self-reflective Preference Optimization (InSPO), deriving a globally optimal policy conditioning on both context and alternative responses. We prove this formulation superior to DPO/RLHF while guaranteeing invariance to scalarization and reference choices. InSPO serves as a plug-and-play enhancement without architectural changes or inference overhead. Experiments demonstrate consistent improvements in win rates and length-controlled metrics, validating that unlocking self-reflection yields more robust, human-aligned LLMs.