Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
作者: Armin Berger, Manuela Bergau, Helen Schneider, Saad Ahmad, Tom Anglim Lagones, Gianluca Brugnara, Martha Foltyn-Dumitru, Kai Schlamp, Philipp Vollmuth, Rafet Sifa
分类: cs.AI, cs.LG
发布日期: 2025-12-28 (更新: 2026-01-02)
💡 一句话要点
ChexReason揭示强化学习在医学影像中优化基准测试而非患者的困境
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 医学影像 视觉-语言模型 泛化能力 监督微调
📋 核心要点
- 现有医学影像的强化学习方法在资源受限情况下表现不足,难以兼顾性能与泛化性。
- ChexReason模型采用R1风格训练,通过少量样本和单GPU,探索强化学习在医学影像中的应用。
- 实验表明,强化学习虽提升了在分布性能,但牺牲了跨数据集的泛化能力,凸显了临床应用的挑战。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)的强化学习(RL)进展在医学影像中资源受限应用的情况。研究者提出了ChexReason,一个通过R1风格方法(SFT后接GRPO)训练的视觉-语言模型,仅使用2000个SFT样本、1000个RL样本和一个A100 GPU。在CheXpert和NIH基准测试上的评估揭示了一个根本矛盾:GRPO恢复了在分布性能(CheXpert上提升23%,macro-F1 = 0.346),但降低了跨数据集的泛化能力(NIH上降低19%)。这与NV-Reason-CXR-3B等高资源模型类似,表明问题源于RL范式而非规模。研究发现了一个泛化悖论,即SFT检查点在优化前独特地改进了NIH,表明教师指导的推理捕获了更多机构无关的特征。此外,跨模型比较表明,结构化推理支架有利于通用VLM,但对医学预训练模型提供的增益最小。因此,对于需要跨不同人群的鲁棒性的临床部署,精心策划的监督微调可能优于激进的RL。
🔬 方法详解
问题定义:论文旨在解决医学影像领域中,利用强化学习训练的视觉-语言模型在临床应用中泛化能力不足的问题。现有方法往往针对特定数据集进行优化,导致在其他数据集上的性能显著下降,无法满足实际临床需求。
核心思路:论文的核心思路是分析强化学习范式在医学影像任务中可能存在的偏差,并探究其对模型泛化能力的影响。通过对比监督微调和强化学习两种训练方式,揭示强化学习可能过度拟合特定数据集的特征,从而损害模型的泛化能力。
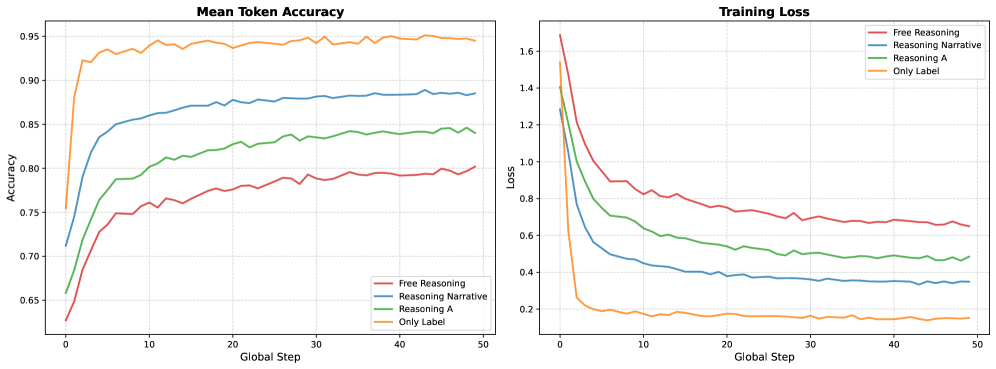
技术框架:ChexReason模型采用R1风格的训练流程,包括两个主要阶段:首先是监督微调(SFT),使用少量标注数据对模型进行初步训练,使其具备基本的视觉-语言理解能力;然后是基于GRPO(未知)的强化学习阶段,进一步优化模型的推理能力。整个训练过程在单个A100 GPU上完成,以模拟资源受限的实际应用场景。
关键创新:论文的关键创新在于揭示了强化学习在医学影像任务中存在的“泛化悖论”,即强化学习虽然可以提升模型在特定基准测试上的性能,但会损害其在其他数据集上的泛化能力。这表明,针对基准测试的优化可能导致模型过度拟合特定数据集的特征,从而降低其在实际临床应用中的价值。
关键设计:论文的关键设计包括:1) 使用少量样本进行训练,以模拟资源受限的场景;2) 采用R1风格的训练流程,结合监督微调和强化学习;3) 对比不同训练方式(监督微调 vs. 强化学习)对模型泛化能力的影响;4) 在多个数据集上进行评估,以全面评估模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ChexReason模型在CheXpert数据集上取得了23%的性能提升(macro-F1 = 0.346),但在NIH数据集上的性能下降了19%。这一结果与高资源模型NV-Reason-CXR-3B的表现类似,表明强化学习范式是导致泛化能力下降的主要原因。此外,SFT检查点在优化前在NIH数据集上表现更好,突显了监督微调在捕获机构无关特征方面的优势。
🎯 应用场景
该研究成果对医学影像分析领域具有重要意义,有助于开发更可靠、更具泛化能力的AI辅助诊断系统。通过深入理解强化学习在医学影像中的局限性,可以指导研究者设计更有效的训练策略,从而提升AI模型在临床实践中的应用价值,辅助医生进行更准确的诊断和治疗。
📄 摘要(原文)
Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors high-resource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institution-agnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised fine-tuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.