Problems With Large Language Models for Learner Modelling: Why LLMs Alone Fall Short for Responsible Tutoring in K--12 Education
作者: Danial Hooshyar, Yeongwook Yang, Gustav Šíř, Tommi Kärkkäinen, Raija Hämäläinen, Mutlu Cukurova, Roger Azevedo
分类: cs.AI
发布日期: 2025-12-28
💡 一句话要点
揭示大语言模型在K-12教育学习者建模中的局限性,强调混合框架的重要性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 学习者建模 深度知识追踪 K-12教育 智能辅导系统
📋 核心要点
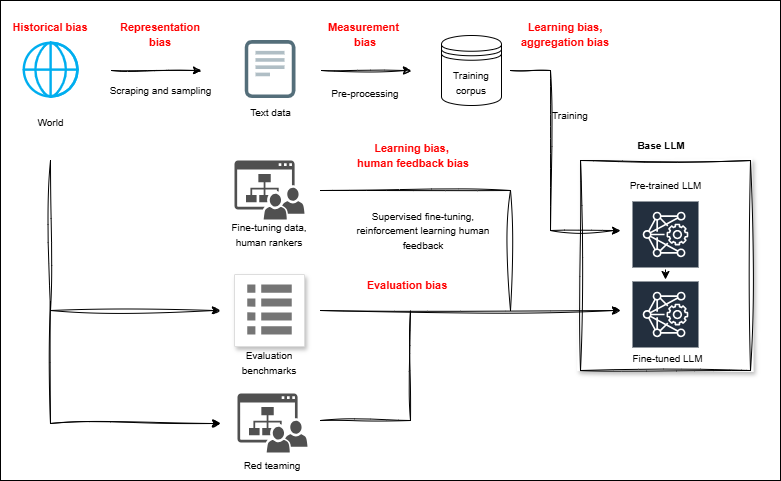
- 现有基于LLM的辅导系统在K-12教育中被认为可以替代传统的学习者建模,但其有效性和可靠性存在挑战。
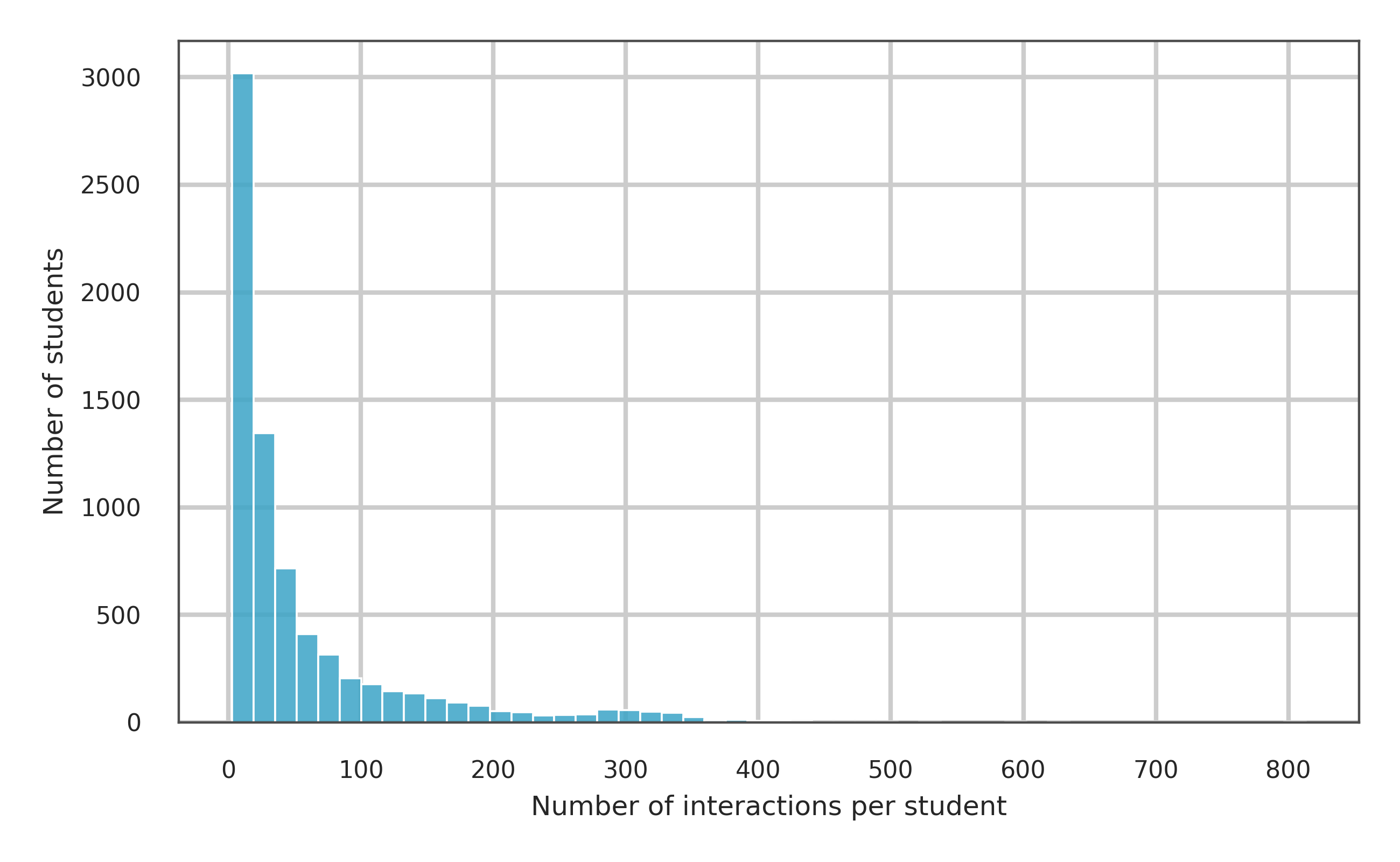
- 本研究提出采用深度知识追踪(DKT)模型与LLM进行对比,评估它们在预测学生知识掌握程度上的准确性和时间一致性。
- 实验结果表明,DKT模型在预测准确性和时间一致性方面优于LLM,强调了混合框架在负责任辅导中的重要性。
📝 摘要(中文)
本研究旨在探讨基于大语言模型(LLM)的辅导系统在K-12教育中替代传统学习者建模的误解。鉴于欧盟AI法案将K-12教育列为高风险领域,需要负责任的设计,本研究综合分析了LLM辅导系统的局限性,并实证研究了一个关键问题:评估学习者随时间演变的知识的准确性、可靠性和时间一致性。通过大型开放数据集,比较了深度知识追踪(DKT)模型与广泛使用的LLM(零样本和微调)。结果表明,DKT在下一步正确性预测方面实现了最高的区分性能(AUC = 0.83),并且在各种设置中始终优于LLM。尽管微调使LLM的AUC比零样本基线提高了约8%,但仍比DKT低6%,并且产生更高的早期序列错误,这对自适应支持最有害。时间分析进一步表明,DKT保持稳定且方向正确的掌握度更新,而LLM变体表现出显着的时间弱点,包括不一致和错误方向的更新。这些限制仍然存在,即使经过微调的LLM需要近198小时的高计算训练,远远超过DKT的计算需求。定性分析表明,即使经过微调,LLM也产生了不一致的掌握度轨迹,而DKT保持了平滑和连贯的更新。总体而言,研究结果表明,仅靠LLM不太可能与已建立的智能辅导系统相媲美,负责任的辅导需要结合学习者建模的混合框架。
🔬 方法详解
问题定义:论文旨在解决K-12教育中,使用大型语言模型(LLM)进行学习者建模时,其准确性、可靠性和时间一致性不足的问题。现有方法,即直接使用LLM进行知识追踪和预测,无法保证对学生知识状态的准确评估,尤其是在早期学习阶段,错误的预测会严重影响自适应辅导的效果。
核心思路:论文的核心思路是对比LLM和深度知识追踪(DKT)模型在学习者建模任务上的表现,揭示LLM的局限性,并强调结合传统学习者建模方法(如DKT)的混合框架的重要性。通过实证研究,证明DKT在知识追踪的准确性和时间一致性方面优于LLM。
技术框架:论文采用对比实验的方法,比较了DKT模型和LLM在预测学生知识掌握程度上的性能。整体流程包括:1) 数据集准备:使用大型开放数据集;2) 模型训练:训练DKT模型和LLM(包括零样本和微调);3) 性能评估:使用AUC等指标评估模型在下一步正确性预测上的性能;4) 时间分析:分析模型在时间维度上对学生知识状态的更新情况;5) 定性分析:分析模型在多技能掌握度估计上的表现。
关键创新:论文的关键创新在于实证揭示了LLM在学习者建模中的局限性,尤其是在时间一致性方面。通过与DKT模型的对比,强调了LLM无法完全替代传统的学习者建模方法,并提出了构建混合框架的必要性。
关键设计:论文的关键设计包括:1) 使用AUC作为评估指标,衡量模型预测学生答案正确性的能力;2) 进行时间分析,评估模型在时间维度上对学生知识状态更新的稳定性和方向性;3) 对LLM进行微调,以提高其在特定任务上的性能;4) 对比LLM和DKT的计算资源消耗,发现LLM需要更高的计算成本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DKT模型在下一步正确性预测方面实现了最高的区分性能(AUC = 0.83),并且在各种设置中始终优于LLM。即使经过微调,LLM的AUC仍比DKT低6%,并且产生更高的早期序列错误。时间分析表明,DKT保持稳定且方向正确的掌握度更新,而LLM变体表现出显著的时间弱点。
🎯 应用场景
该研究成果可应用于智能辅导系统、在线教育平台和个性化学习工具的设计与开发。通过结合传统的学习者建模方法(如DKT)和LLM,可以构建更准确、可靠和个性化的学习体验,从而提高学生的学习效果和满意度。未来的研究可以探索更有效的混合框架,充分利用LLM的生成能力和传统模型的知识追踪能力。
📄 摘要(原文)
The rapid rise of large language model (LLM)-based tutors in K--12 education has fostered a misconception that generative models can replace traditional learner modelling for adaptive instruction. This is especially problematic in K--12 settings, which the EU AI Act classifies as high-risk domain requiring responsible design. Motivated by these concerns, this study synthesises evidence on limitations of LLM-based tutors and empirically investigates one critical issue: the accuracy, reliability, and temporal coherence of assessing learners' evolving knowledge over time. We compare a deep knowledge tracing (DKT) model with a widely used LLM, evaluated zero-shot and fine-tuned, using a large open-access dataset. Results show that DKT achieves the highest discrimination performance (AUC = 0.83) on next-step correctness prediction and consistently outperforms the LLM across settings. Although fine-tuning improves the LLM's AUC by approximately 8\% over the zero-shot baseline, it remains 6\% below DKT and produces higher early-sequence errors, where incorrect predictions are most harmful for adaptive support. Temporal analyses further reveal that DKT maintains stable, directionally correct mastery updates, whereas LLM variants exhibit substantial temporal weaknesses, including inconsistent and wrong-direction updates. These limitations persist despite the fine-tuned LLM requiring nearly 198 hours of high-compute training, far exceeding the computational demands of DKT. Our qualitative analysis of multi-skill mastery estimation further shows that, even after fine-tuning, the LLM produced inconsistent mastery trajectories, while DKT maintained smooth and coherent updates. Overall, the findings suggest that LLMs alone are unlikely to match the effectiveness of established intelligent tutoring systems, and that responsible tutoring requires hybrid frameworks that incorporate learner modelling.