Viability and Performance of a Private LLM Server for SMBs: A Benchmark Analysis of Qwen3-30B on Consumer-Grade Hardware
作者: Alex Khalil, Guillaume Heilles, Maria Parraga, Simon Heilles
分类: cs.DC, cs.AI
发布日期: 2025-12-28
💡 一句话要点
在消费级硬件上部署私有Qwen3-30B LLM服务器,为中小企业提供高性能低成本方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 私有部署 消费级硬件 模型量化 Qwen3 中小企业 推理服务器 性能评估
📋 核心要点
- 现有LLM服务依赖云端,存在数据隐私风险、运营受限以及成本高等问题,中小企业难以负担。
- 论文提出在消费级硬件上部署私有LLM服务器,使用量化的开源模型,降低成本并保障数据安全。
- 实验表明,该方案在性能上可与云端服务媲美,为中小企业部署LLM提供了一条经济可行的路径。
📝 摘要(中文)
大型语言模型(LLM)的普及伴随着对云端专有系统的依赖,引发了对数据隐私、运营自主性和成本上升的担忧。本文研究了以中小企业(SMB)可承受的成本部署高性能私有LLM推理服务器的可行性。我们对基于Qwen3的量化300亿参数混合专家(MoE)模型进行了全面的基准分析,该模型在配备下一代NVIDIA GPU的消费级服务器上本地运行。与昂贵且难以集成的云端产品不同,我们的方法为中小企业提供了一种经济实惠且私密的解决方案。我们评估了两个维度:模型的内在能力和服务器在负载下的性能。模型性能根据学术界和工业界标准进行基准测试,以量化相对于云服务的推理和知识。同时,我们通过延迟、每秒token数和首个token时间来衡量服务器效率,分析并发用户增加时的可扩展性。我们的研究结果表明,通过精心配置的本地部署,结合新兴的消费级硬件和量化的开源模型,可以实现与云端服务相当的性能,为中小企业提供了一条可行的途径,以部署强大的LLM,而无需承担过高的成本或牺牲隐私。
🔬 方法详解
问题定义:论文旨在解决中小企业(SMBs)因成本和隐私问题难以部署大型语言模型(LLMs)的问题。现有云端LLM服务虽然强大,但价格昂贵,且数据存储在第三方服务器上,存在潜在的安全风险。SMBs需要一种经济实惠且能保障数据隐私的LLM解决方案。
核心思路:论文的核心思路是利用消费级硬件(如配备NVIDIA GPU的服务器)和量化的开源LLM模型(Qwen3-30B)构建私有LLM推理服务器。通过量化降低模型大小,减少计算资源需求,从而降低硬件成本。同时,本地部署保证了数据隐私和运营自主性。
技术框架:该方案的技术框架主要包括以下几个部分:1)选择合适的消费级服务器硬件,配备高性能GPU;2)选择开源LLM模型,如Qwen3-30B;3)对LLM模型进行量化,降低模型大小和计算复杂度;4)部署LLM推理服务,并进行性能优化;5)进行基准测试,评估模型性能和服务器效率。
关键创新:论文的关键创新在于探索了在消费级硬件上部署高性能LLM的可行性,并验证了通过量化开源模型可以实现与云端服务相当的性能。这种方法降低了LLM部署的门槛,使中小企业也能受益于LLM技术。
关键设计:论文的关键设计包括:1)选择Qwen3-30B作为基础模型,因为它是一个开源且性能良好的LLM;2)采用模型量化技术,例如int8量化,以减少模型大小和计算需求;3)使用适当的推理框架(具体框架未知)来优化推理性能,例如通过批处理请求来提高吞吐量;4)通过基准测试来评估不同配置下的性能,并选择最佳配置。
🖼️ 关键图片
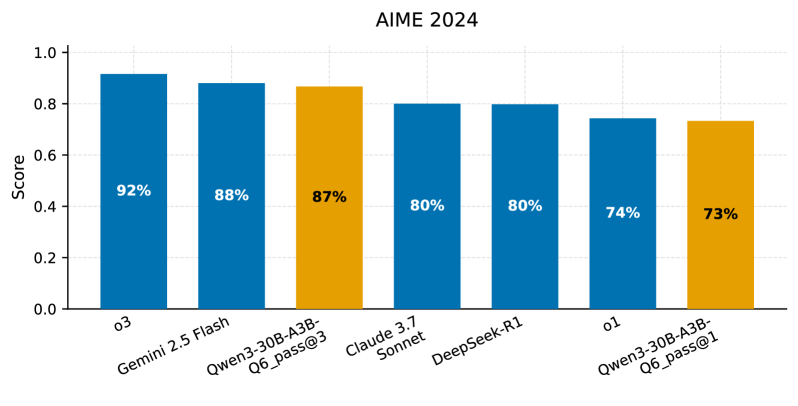
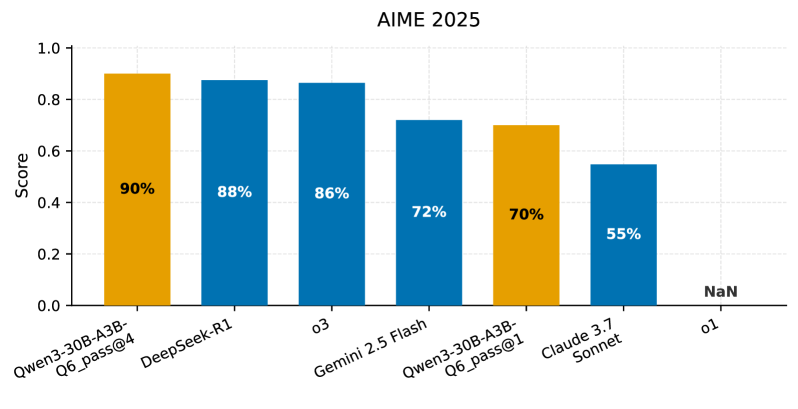
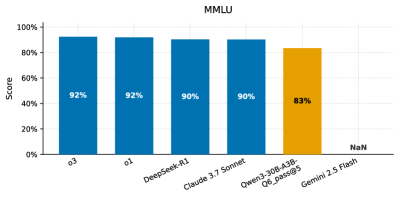
📊 实验亮点
论文通过实验证明,在消费级硬件上部署量化的Qwen3-30B模型,可以实现与云端服务相当的性能。具体性能数据包括延迟、每秒token数和首个token时间,并分析了并发用户增加时的可扩展性。虽然具体的性能指标和对比基线没有在摘要中给出,但结论表明该方案为中小企业提供了一条经济可行的LLM部署路径。
🎯 应用场景
该研究成果可应用于各种需要本地化、私有化LLM服务的场景,例如:金融行业的风险评估、医疗行业的病历分析、法律行业的合同审查等。中小企业可以利用该方案构建自己的智能客服、内容生成、数据分析等应用,提升运营效率和竞争力。未来,随着硬件性能的提升和模型压缩技术的进步,私有LLM服务器的应用前景将更加广阔。
📄 摘要(原文)
The proliferation of Large Language Models (LLMs) has been accompanied by a reliance on cloud-based, proprietary systems, raising significant concerns regarding data privacy, operational sovereignty, and escalating costs. This paper investigates the feasibility of deploying a high-performance, private LLM inference server at a cost accessible to Small and Medium Businesses (SMBs). We present a comprehensive benchmarking analysis of a locally hosted, quantized 30-billion parameter Mixture-of-Experts (MoE) model based on Qwen3, running on a consumer-grade server equipped with a next-generation NVIDIA GPU. Unlike cloud-based offerings, which are expensive and complex to integrate, our approach provides an affordable and private solution for SMBs. We evaluate two dimensions: the model's intrinsic capabilities and the server's performance under load. Model performance is benchmarked against academic and industry standards to quantify reasoning and knowledge relative to cloud services. Concurrently, we measure server efficiency through latency, tokens per second, and time to first token, analyzing scalability under increasing concurrent users. Our findings demonstrate that a carefully configured on-premises setup with emerging consumer hardware and a quantized open-source model can achieve performance comparable to cloud-based services, offering SMBs a viable pathway to deploy powerful LLMs without prohibitive costs or privacy compromises.