Robust LLM-based Column Type Annotation via Prompt Augmentation with LoRA Tuning
作者: Hanze Meng, Jianhao Cao, Rachel Pottinger
分类: cs.DB, cs.AI
发布日期: 2025-12-28
备注: 13 pages, 8 figures
💡 一句话要点
提出基于Prompt增强和LoRA调优的鲁棒LLM列类型标注方法,提升跨数据集和模板的泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 列类型标注 大型语言模型 Prompt工程 低秩适应 参数高效微调
📋 核心要点
- 现有列类型标注方法在领域外数据上泛化能力差,需要大量重新训练。
- 提出基于Prompt增强和LoRA微调的框架,降低模型对Prompt的敏感性,提高泛化能力。
- 实验表明,该方法在不同数据集和Prompt模板上表现稳定,F1分数优于现有方法。
📝 摘要(中文)
列类型标注(CTA)是实现模式对齐和表格数据语义理解的关键步骤。现有的encoder-only语言模型在标注列上进行微调时能达到高精度,但其适用性受限于领域内设置,因为表格或标签空间中的分布偏移需要从头开始进行昂贵的重新训练。最近的工作探索了通过将CTA构建为多项选择题来提示生成式大型语言模型(LLM),但这些方法面临两个关键挑战:(1)模型性能对提示语措辞和结构的细微变化高度敏感,以及(2)标注F1分数仍然不高。一个自然的扩展是微调大型语言模型。然而,由于其规模,完全微调这些模型会产生过高的计算成本,并且对提示的敏感性并未消除。在本文中,我们提出了一个用于CTA的参数高效框架,该框架通过低秩适应(LoRA)训练提示增强数据上的模型。我们的方法减轻了对提示变化的敏感性,同时大大减少了必要的训练参数数量,从而在数据集和模板上实现了鲁棒的性能。在最新基准上的实验结果表明,使用我们的提示增强策略微调的模型在推理过程中保持了跨不同提示模式的稳定性能,并产生了比在单个提示模板上微调的模型更高的加权F1分数。这些结果突出了参数高效训练和增强策略在开发实用且适应性强的CTA系统中的有效性。
🔬 方法详解
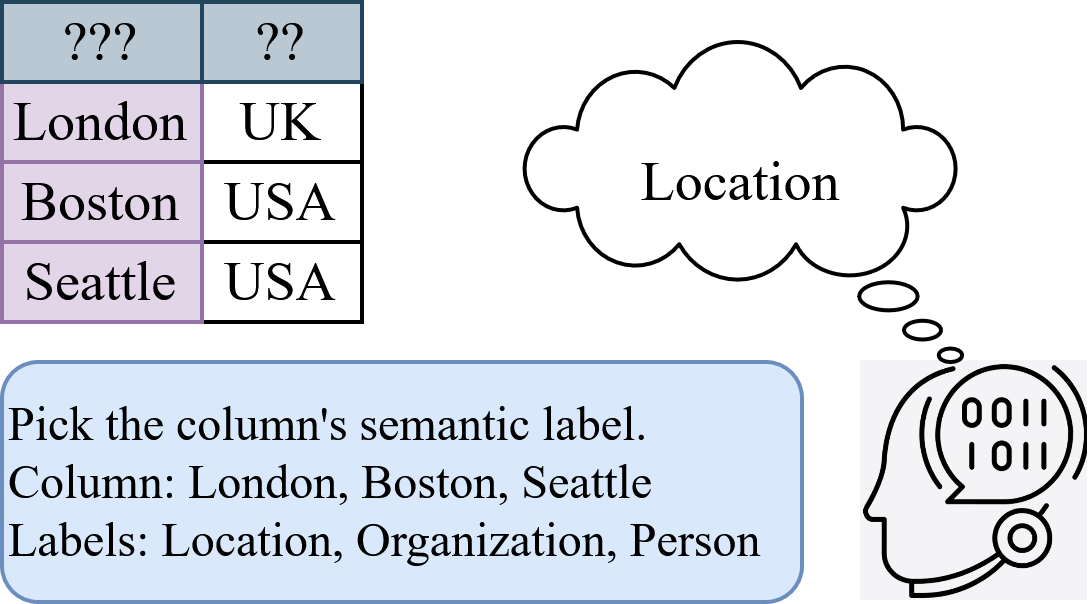
问题定义:列类型标注(CTA)旨在自动确定表格列的数据类型。现有方法,特别是基于encoder-only语言模型的微调方法,在领域内表现良好,但当表格数据或标签空间发生分布偏移时,需要从头开始重新训练,成本高昂。使用LLM进行Prompting的方法虽然避免了重新训练,但对Prompt的措辞和结构非常敏感,导致性能不稳定。
核心思路:该论文的核心思路是通过Prompt增强和低秩适应(LoRA)微调来提高LLM在CTA任务中的鲁棒性和泛化能力。Prompt增强旨在通过生成多种不同的Prompt模板来训练模型,使其对Prompt的变化不敏感。LoRA微调则通过只训练少量参数来降低计算成本,同时保持LLM的强大能力。
技术框架:该框架主要包含两个阶段:Prompt增强阶段和LoRA微调阶段。在Prompt增强阶段,生成多个不同的Prompt模板,用于构建训练数据。在LoRA微调阶段,使用Prompt增强后的数据对LLM进行微调,只训练LoRA模块的参数。推理阶段,可以使用不同的Prompt模板进行预测,模型能够保持稳定的性能。
关键创新:该论文的关键创新在于结合了Prompt增强和LoRA微调,解决了LLM在CTA任务中对Prompt敏感和计算成本高的问题。Prompt增强通过增加训练数据的多样性来提高模型的鲁棒性,LoRA微调则通过减少训练参数来降低计算成本。
关键设计:Prompt增强策略包括人工设计和自动生成Prompt模板。LoRA微调使用预训练的LLM作为基础模型,并在模型的Transformer层中插入LoRA模块。损失函数采用交叉熵损失,优化器采用AdamW。关键参数包括LoRA的秩(rank)和学习率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个CTA基准数据集上取得了显著的性能提升。与在单个Prompt模板上微调的模型相比,使用Prompt增强策略微调的模型在不同Prompt模式下保持了稳定的性能,并且加权F1分数更高。具体数据未知,但论文强调了该方法在跨数据集和模板上的鲁棒性。
🎯 应用场景
该研究成果可应用于数据集成、数据清洗、知识图谱构建等领域。通过自动识别表格列的数据类型,可以提高数据处理的效率和准确性,降低人工标注的成本。未来,该方法可以扩展到更复杂的表格数据理解任务,例如表格关系抽取、表格问答等。
📄 摘要(原文)
Column Type Annotation (CTA) is a fundamental step towards enabling schema alignment and semantic understanding of tabular data. Existing encoder-only language models achieve high accuracy when fine-tuned on labeled columns, but their applicability is limited to in-domain settings, as distribution shifts in tables or label spaces require costly re-training from scratch. Recent work has explored prompting generative large language models (LLMs) by framing CTA as a multiple-choice task, but these approaches face two key challenges: (1) model performance is highly sensitive to subtle changes in prompt wording and structure, and (2) annotation F1 scores remain modest. A natural extension is to fine-tune large language models. However, fully fine-tuning these models incurs prohibitive computational costs due to their scale, and the sensitivity to prompts is not eliminated. In this paper, we present a parameter-efficient framework for CTA that trains models over prompt-augmented data via Low-Rank Adaptation (LoRA). Our approach mitigates sensitivity to prompt variations while drastically reducing the number of necessary trainable parameters, achieving robust performance across datasets and templates. Experimental results on recent benchmarks demonstrate that models fine-tuned with our prompt augmentation strategy maintain stable performance across diverse prompt patterns during inference and yield higher weighted F1 scores than those fine-tuned on a single prompt template. These results highlight the effectiveness of parameter-efficient training and augmentation strategies in developing practical and adaptable CTA systems.