TravelBench: A Broader Real-World Benchmark for Multi-Turn and Tool-Using Travel Planning
作者: Xiang Cheng, Yulan Hu, Xiangwen Zhang, Lu Xu, Zheng Pan, Xin Li, Yong Liu
分类: cs.AI
发布日期: 2025-12-27 (更新: 2026-01-05)
备注: In progress
💡 一句话要点
提出TravelBench:一个更广泛的真实世界旅行规划多轮对话与工具使用基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 旅行规划 大型语言模型 多轮对话 工具使用 基准测试
📋 核心要点
- 现有旅行规划LLM研究在领域覆盖、用户偏好建模和能力边界评估方面存在不足,与真实世界需求存在差距。
- TravelBench通过收集真实场景数据,构建单轮、多轮和不可解三个子任务,全面评估LLM在旅行规划中的能力。
- 该基准提供沙盒环境和缓存工具调用结果,保证工具调用稳定性和评估可复现性,并进行了系统验证。
📝 摘要(中文)
本文提出了TravelBench,一个用于全面真实世界旅行规划的基准。该基准从真实场景中收集用户查询、用户画像和工具,并构建了三个子任务——单轮、多轮和不可解——以评估智能体在真实环境中的三个核心能力:(1)自主解决问题的能力,(2)在多轮对话中与用户交互以完善需求的能力,以及(3)识别自身能力边界的能力。为了实现稳定的工具调用和可复现的评估,我们缓存了真实的工具调用结果,并构建了一个集成了十个旅行相关工具的沙盒环境。智能体可以结合这些工具来解决大多数实际的旅行规划问题,并且我们的系统验证证明了所提出的基准的稳定性。我们进一步在TravelBench上评估了多个LLM,并对其行为和性能进行了深入分析。TravelBench提供了一个实用且可复现的评估基准,以推进LLM智能体在旅行规划方面的研究。
🔬 方法详解
问题定义:现有旅行规划LLM研究存在以下痛点:领域覆盖有限,未能充分建模多轮对话中用户的隐式偏好,缺乏对智能体能力边界的清晰评估。这些局限性导致现有方法难以满足真实世界旅行规划的需求。
核心思路:TravelBench的核心思路是构建一个更贴近真实世界的旅行规划基准,通过使用真实场景数据、模拟多轮对话交互以及包含不可解任务,来全面评估LLM在旅行规划中的能力。这样设计的目的是为了更准确地反映LLM在实际应用中的表现,并促进相关研究的发展。
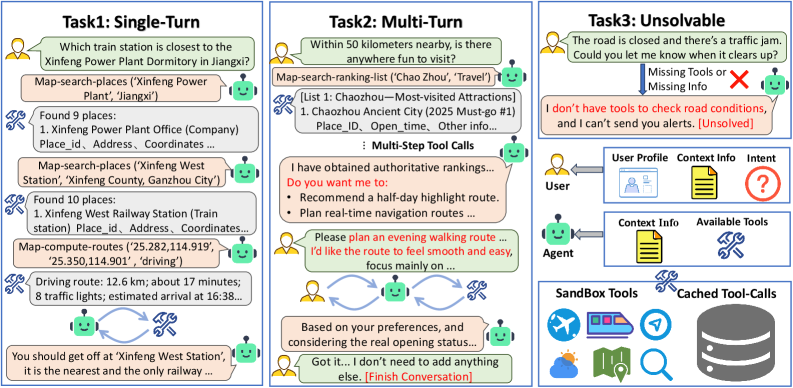
技术框架:TravelBench包含以下主要组成部分:1)真实世界数据收集:从真实场景中收集用户查询、用户画像和旅行相关工具。2)子任务构建:构建单轮、多轮和不可解三个子任务,分别评估LLM的自主解决问题能力、多轮交互能力和能力边界识别能力。3)沙盒环境构建:构建一个集成了十个旅行相关工具的沙盒环境,用于模拟真实世界的工具调用。4)工具调用结果缓存:缓存真实的工具调用结果,以保证工具调用的稳定性和评估的可复现性。
关键创新:TravelBench的关键创新在于其全面性和真实性。它不仅考虑了单轮旅行规划,还模拟了多轮对话交互,并包含了不可解任务,从而更全面地评估LLM在旅行规划中的能力。此外,通过使用真实场景数据和构建沙盒环境,TravelBench更贴近真实世界的应用场景。
关键设计:TravelBench的关键设计包括:1)用户画像的构建:通过分析真实用户数据,构建具有代表性的用户画像,用于模拟用户的隐式偏好。2)不可解任务的设计:设计一些无法通过现有工具解决的旅行规划任务,用于评估LLM的能力边界识别能力。3)沙盒环境的配置:配置沙盒环境,确保工具调用的稳定性和安全性。
🖼️ 关键图片

📊 实验亮点
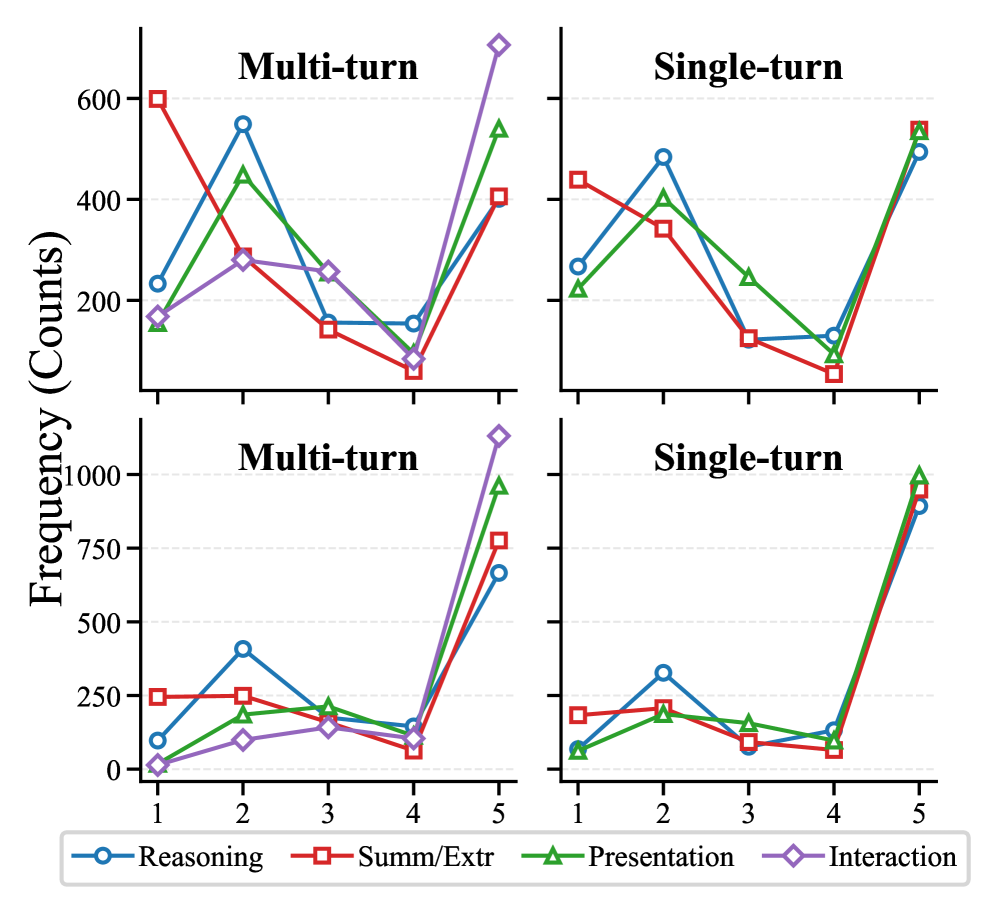
TravelBench基准的系统验证表明其具有良好的稳定性和可复现性。在TravelBench上评估多个LLM后,发现它们在多轮对话和能力边界识别方面仍存在不足。例如,部分LLM在面对不可解任务时,无法正确识别并拒绝回答,而是尝试给出错误的解决方案。这些发现为未来LLM智能体的研究提供了重要的指导。
🎯 应用场景
TravelBench的研究成果可应用于开发更智能、更实用的旅行规划助手,帮助用户更高效地制定旅行计划。此外,该基准也可用于评估和改进其他领域的LLM智能体,例如智能客服、智能家居等。未来,该研究有望推动人机交互和人工智能技术的进一步发展。
📄 摘要(原文)
Travel planning is a natural real-world task to test large language models (LLMs) planning and tool-use abilities. Although prior work has studied LLM performance on travel planning, existing settings still differ from real-world needs, mainly due to limited domain coverage, insufficient modeling of users' implicit preferences in multi-turn conversations, and a lack of clear evaluation of agents' capability boundaries. To mitigate these gaps, we propose \textbf{TravelBench}, a benchmark for fully real-world travel planning. We collect user queries, user profile and tools from real scenarios, and construct three subtasks-Single-Turn, Multi-Turn, and Unsolvable-to evaluate agent's three core capabilities in real settings: (1) solving problems autonomously, (2) interacting with users over multiple turns to refine requirements, and (3) recognizing the limits of own abilities. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment that integrates ten travel-related tools. Agents can combine these tools to solve most practical travel planning problems, and our systematic verification demonstrates the stability of the proposed benchmark. We further evaluate multiple LLMs on TravelBench and conduct an in-depth analysis of their behaviors and performance. TravelBench provides a practical and reproducible evaluation benchmark to advance research on LLM agents for travel planning.\footnote{Our code and data will be available after internal review.