The Wisdom of Deliberating AI Crowds: Does Deliberation Improve LLM-Based Forecasting?
作者: Paul Schneider, Amalie Schramm
分类: cs.AI, cs.MA
发布日期: 2025-12-27
备注: 13 pages, 2 figures, 5 tables, for source code and data see https://github.com/priorb-source/delib-ai-wisdom
💡 一句话要点
通过群体审议提升LLM预测能力:一种基于LLM间互相审查的改进方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预测 群体智慧 审议 信息共享
📋 核心要点
- 现有LLM预测方法缺乏有效的群体智慧融合机制,限制了预测准确性。
- 论文提出一种基于LLM间互相审查的审议方法,旨在提升LLM预测的准确性。
- 实验表明,在具有共享信息的多样化模型情景下,该方法显著提升了预测准确性。
📝 摘要(中文)
本研究探讨了结构化审议是否能提升大型语言模型(LLM)的预测准确性,类似于其在人类预测中的作用。具体而言,研究考察了让LLM在更新预测前互相审查对方预测的效果。实验使用了Metaculus Q2 2025 AI预测竞赛中202个已解决的二元问题,并在四种情景下评估了准确性:(1)具有分布式信息的多样化模型;(2)具有共享信息的多样化模型;(3)具有分布式信息的同质模型;(4)具有共享信息的同质模型。结果表明,该干预显著提高了情景(2)的准确性,Log Loss降低了0.020,相对降低约4%(p = 0.017)。然而,当同质群体(同一模型的三个实例)进行相同的过程时,没有观察到益处。出乎意料的是,向LLM提供额外的上下文信息并没有提高预测准确性,限制了我们研究信息池化机制的能力。研究结果表明,审议可能是提高LLM预测能力的可行策略。
🔬 方法详解
问题定义:论文旨在解决如何提升LLM在预测任务中的准确性问题。现有方法,如直接使用单个LLM进行预测,缺乏有效的群体智慧融合机制,可能导致预测结果不够准确和鲁棒。特别是在复杂和不确定性高的预测场景下,单个LLM的能力可能受到限制。
核心思路:论文的核心思路是借鉴人类预测中的“审议”机制,让多个LLM互相审查彼此的预测结果,从而实现信息共享和观点碰撞,最终提升整体的预测准确性。这种方法模拟了人类专家团队通过讨论和辩论来达成共识的过程。
技术框架:整体流程包括以下几个阶段:1) 多个LLM独立生成初始预测;2) 每个LLM审查其他LLM的预测结果,并给出反馈;3) LLM基于收到的反馈更新自己的预测;4) 对所有LLM的最终预测进行聚合,得到最终的预测结果。实验中使用了GPT-5, Claude Sonnet 4.5, Gemini Pro 2.5等多种LLM,并设计了不同的信息共享模式(分布式信息和共享信息)和模型同质性(同质模型和异质模型)来评估审议机制的效果。
关键创新:最重要的技术创新点在于将人类的“审议”过程引入到LLM的预测流程中,通过LLM之间的互相审查和反馈,模拟了群体智慧的形成过程。与传统的集成学习方法不同,该方法更加注重LLM之间的互动和信息交换,而不是简单地对多个模型的预测结果进行加权平均。
关键设计:实验中使用了Log Loss作为评估预测准确性的指标。针对不同的实验场景,设计了不同的信息共享模式和模型同质性。例如,在共享信息的情景下,所有LLM都获得了相同的上下文信息;而在分布式信息的情景下,每个LLM只获得了部分上下文信息。此外,论文还尝试了向LLM提供额外的上下文信息,但结果表明并没有提高预测准确性。具体的参数设置和网络结构取决于所使用的LLM模型本身,论文主要关注的是审议机制对预测结果的影响。
🖼️ 关键图片

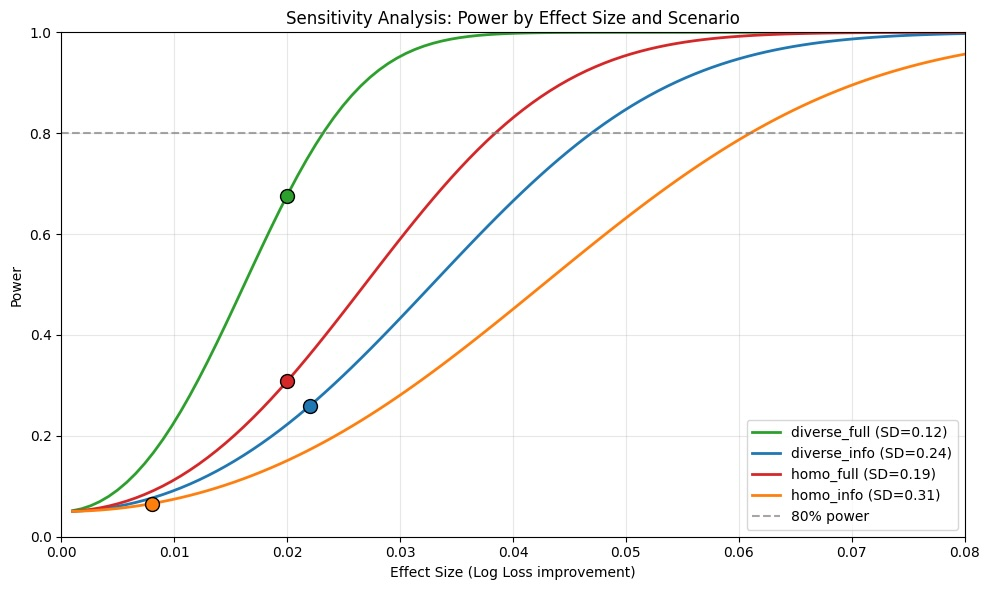
📊 实验亮点
实验结果表明,在具有共享信息的多样化模型情景下,审议机制显著提高了预测准确性,Log Loss降低了0.020,相对降低约4%(p = 0.017)。这一结果表明,LLM之间的互相审查和反馈可以有效地提升预测性能。然而,当使用同质模型时,审议机制并没有带来明显的益处,这表明模型的多样性是审议机制发挥作用的关键因素之一。
🎯 应用场景
该研究成果可应用于各种需要准确预测的领域,如金融市场预测、政治事件预测、科技趋势预测等。通过构建基于LLM的预测系统,并引入审议机制,可以显著提高预测的准确性和可靠性,为决策者提供更有价值的参考信息。未来,该方法还可以扩展到其他类型的AI模型,例如图像识别模型和自然语言处理模型。
📄 摘要(原文)
Structured deliberation has been found to improve the performance of human forecasters. This study investigates whether a similar intervention, i.e. allowing LLMs to review each other's forecasts before updating, can improve accuracy in large language models (GPT-5, Claude Sonnet 4.5, Gemini Pro 2.5). Using 202 resolved binary questions from the Metaculus Q2 2025 AI Forecasting Tournament, accuracy was assessed across four scenarios: (1) diverse models with distributed information, (2) diverse models with shared information, (3) homogeneous models with distributed information, and (4) homogeneous models with shared information. Results show that the intervention significantly improves accuracy in scenario (2), reducing Log Loss by 0.020 or about 4 percent in relative terms (p = 0.017). However, when homogeneous groups (three instances of the same model) engaged in the same process, no benefit was observed. Unexpectedly, providing LLMs with additional contextual information did not improve forecast accuracy, limiting our ability to study information pooling as a mechanism. Our findings suggest that deliberation may be a viable strategy for improving LLM forecasting.