RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure
作者: Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, Ju Huang, Siran Yang, Yongbin Li, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, Wei Wang
分类: cs.DC, cs.AI, cs.LG
发布日期: 2025-12-27
备注: 17 pages, 17 figures
🔗 代码/项目: GITHUB
💡 一句话要点
RollArc:通过分离式基础设施扩展Agentic RL训练,提升训练吞吐量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic RL 强化学习 分布式训练 分离式基础设施 异步执行
📋 核心要点
- Agentic RL训练负载异构,传统方法在资源利用和同步开销上存在挑战。
- RollArc通过硬件亲和性映射、细粒度异步和状态感知计算,优化资源分配。
- RollArc在实际集群上显著提升了训练吞吐量,并成功训练了大规模MoE模型。
📝 摘要(中文)
Agentic强化学习(RL)使大型语言模型(LLM)能够执行自主决策和长期规划。与标准的LLM后训练不同,agentic RL工作负载是高度异构的,结合了计算密集型预填充阶段、带宽受限的解码以及有状态的、CPU密集的模拟环境。我们认为,高效的agentic RL训练需要分离式基础设施来利用专门的、最合适的硬件。然而,由于各阶段之间复杂的依赖关系,简单的分离会引入大量的同步开销和资源利用不足。我们提出了RollArc,一个分布式系统,旨在最大限度地提高分离式基础设施上多任务agentic RL的吞吐量。RollArc建立在三个核心原则之上:(1)硬件亲和性工作负载映射,将计算密集型和带宽密集型任务路由到最合适的GPU设备,(2)细粒度异步,在轨迹级别管理执行以减少资源气泡,以及(3)状态感知计算,将无状态组件(例如,奖励模型)卸载到无服务器基础设施以实现弹性扩展。结果表明,与单片和同步基线相比,RollArc有效地提高了训练吞吐量,并实现了1.35-2.05倍的端到端训练时间缩短。我们还在一个拥有超过3000个GPU的阿里巴巴集群上,通过训练一个数千亿参数的MoE模型用于Qoder产品来评估RollArc,进一步证明了RollArc的可扩展性和鲁棒性。代码可在https://github.com/alibaba/ROLL获取。
🔬 方法详解
问题定义:论文旨在解决Agentic RL训练中,由于工作负载异构性导致在传统基础设施上资源利用率低和同步开销大的问题。现有方法,如单片训练或简单的同步分布式训练,无法充分利用不同硬件的优势,并且容易产生资源瓶颈。
核心思路:RollArc的核心思路是利用分离式基础设施,将Agentic RL训练的不同阶段(如预填充、解码、环境模拟)分配到最适合的硬件上执行。通过细粒度的异步执行和状态感知计算,减少同步开销,提高整体训练吞吐量。
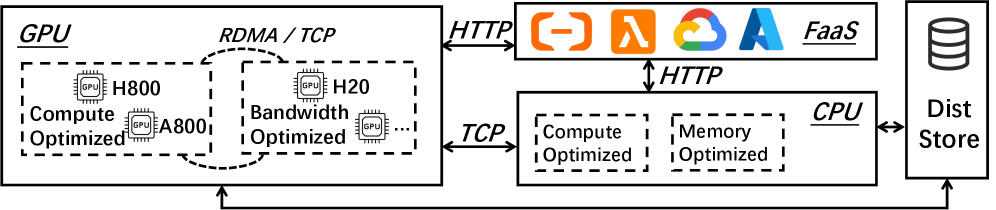
技术框架:RollArc的整体架构包含以下几个主要模块:1) 硬件亲和性工作负载映射:根据任务的计算或带宽需求,将任务分配到最合适的GPU设备上。2) 细粒度异步执行:在轨迹级别管理执行,允许不同阶段的任务异步执行,从而减少资源空闲时间。3) 状态感知计算:将无状态的组件(如奖励模型)卸载到serverless基础设施上,实现弹性扩展。
关键创新:RollArc的关键创新在于其综合考虑了Agentic RL训练的异构性、硬件特性和任务依赖关系,提出了一个整体的分布式系统解决方案。与传统的同步分布式训练相比,RollArc的异步执行和硬件亲和性映射能够更有效地利用资源,减少同步开销。
关键设计:RollArc的关键设计包括:1) 硬件亲和性映射策略:根据任务的profile信息(如计算量、内存占用、带宽需求)选择合适的GPU设备。2) 细粒度异步调度算法:在轨迹级别进行调度,保证任务之间的依赖关系,同时允许异步执行。3) 状态感知计算的实现:利用serverless平台提供的弹性扩展能力,动态分配资源给无状态组件。
🖼️ 关键图片

📊 实验亮点
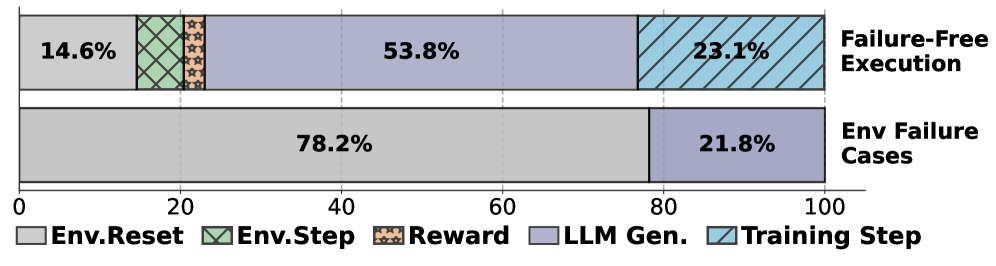
实验结果表明,RollArc相比于单片和同步基线,实现了1.35-2.05倍的端到端训练时间缩短。此外,RollArc还在一个拥有超过3000个GPU的阿里巴巴集群上成功训练了一个数千亿参数的MoE模型,验证了其在大规模场景下的可扩展性和鲁棒性。
🎯 应用场景
RollArc可应用于各种需要Agentic RL训练的场景,例如机器人控制、游戏AI、自动驾驶、推荐系统等。通过提高训练效率和降低训练成本,RollArc能够加速Agentic RL技术在实际应用中的落地,并促进相关领域的发展。
📄 摘要(原文)
Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05(\times) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.