Efficient Multi-Model Orchestration for Self-Hosted Large Language Models
作者: Bhanu Prakash Vangala, Tanu Malik
分类: cs.DC, cs.AI
发布日期: 2025-12-26
💡 一句话要点
Pick and Spin:高效自托管大语言模型的多模型编排框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自托管 模型编排 Kubernetes 资源优化
📋 核心要点
- 现有自托管LLM方案在GPU利用率、请求路由和系统可靠性方面存在挑战,导致资源浪费和效率低下。
- Pick and Spin框架通过统一部署、自适应伸缩和混合路由,实现了自托管LLM编排的可扩展性和经济性。
- 实验结果表明,Pick and Spin相比静态部署,显著提升了成功率、降低了延迟和GPU成本。
📝 摘要(中文)
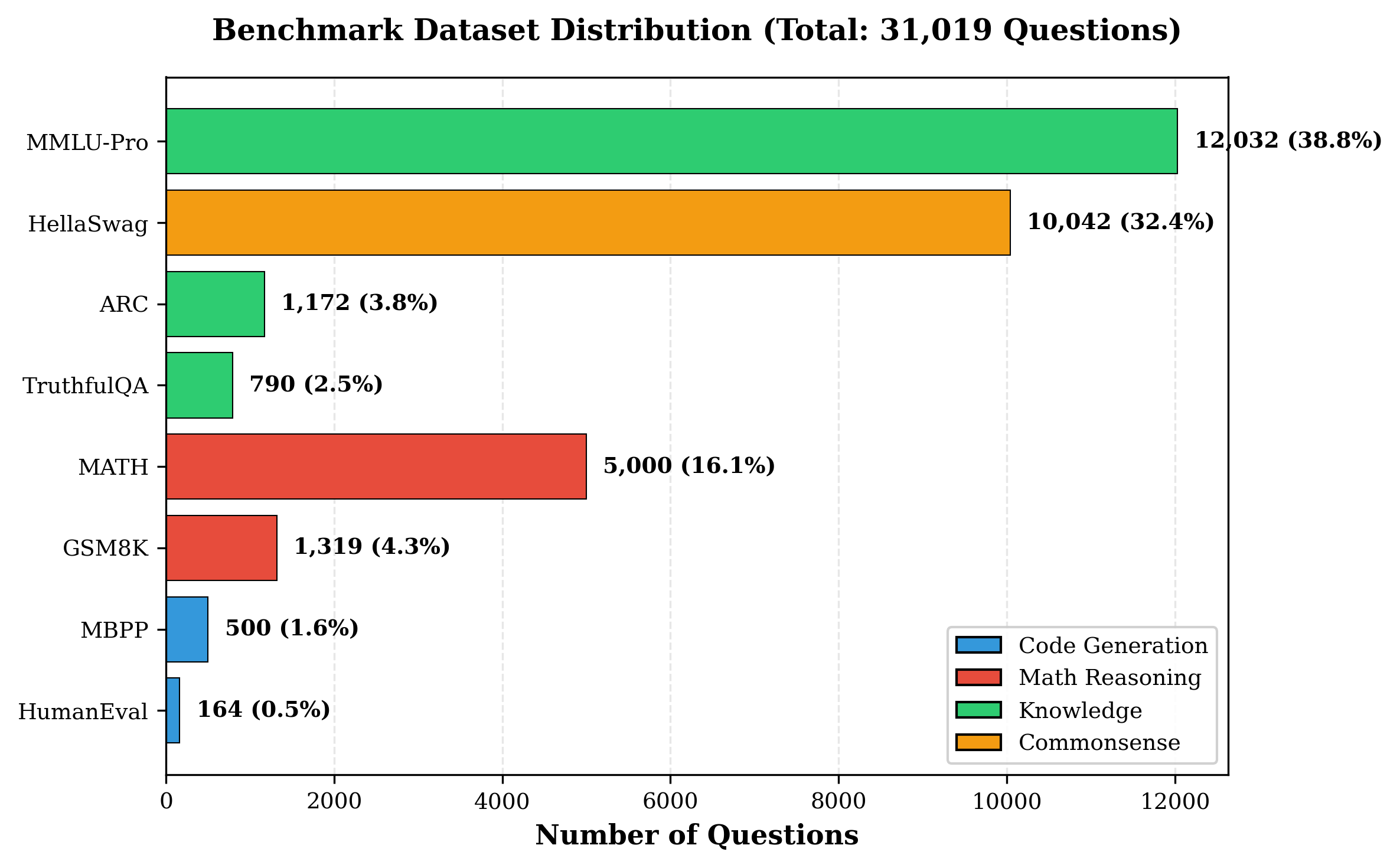
自托管大型语言模型(LLM)对于寻求隐私、成本控制和定制的组织越来越有吸引力。然而,内部模型的部署和维护在GPU利用率、工作负载路由和可靠性方面提出了挑战。我们介绍Pick and Spin,一个实用的框架,使自托管LLM编排具有可扩展性和经济性。它构建在Kubernetes之上,集成了统一的基于Helm的部署系统、自适应的scale-to-zero自动化以及混合路由模块,该模块使用关键字启发式方法和轻量级DistilBERT分类器来平衡成本、延迟和准确性。我们评估了四个模型,Llama-3 (90B)、Gemma-3 (27B)、Qwen-3 (235B)和DeepSeek-R1 (685B),跨越八个公共基准数据集,具有五种推理策略和两种路由变体,包含31,019个提示和163,720次推理运行。与相同模型的静态部署相比,Pick and Spin实现了高达21.6%的更高成功率、30%的更低延迟和33%的更低GPU成本。
🔬 方法详解
问题定义:论文旨在解决自托管大型语言模型(LLM)时面临的资源利用率低、请求路由策略不佳以及系统可靠性不足的问题。现有方法通常采用静态部署,无法根据实际负载动态调整资源,导致GPU资源浪费。同时,简单的路由策略难以在成本、延迟和准确性之间取得平衡。
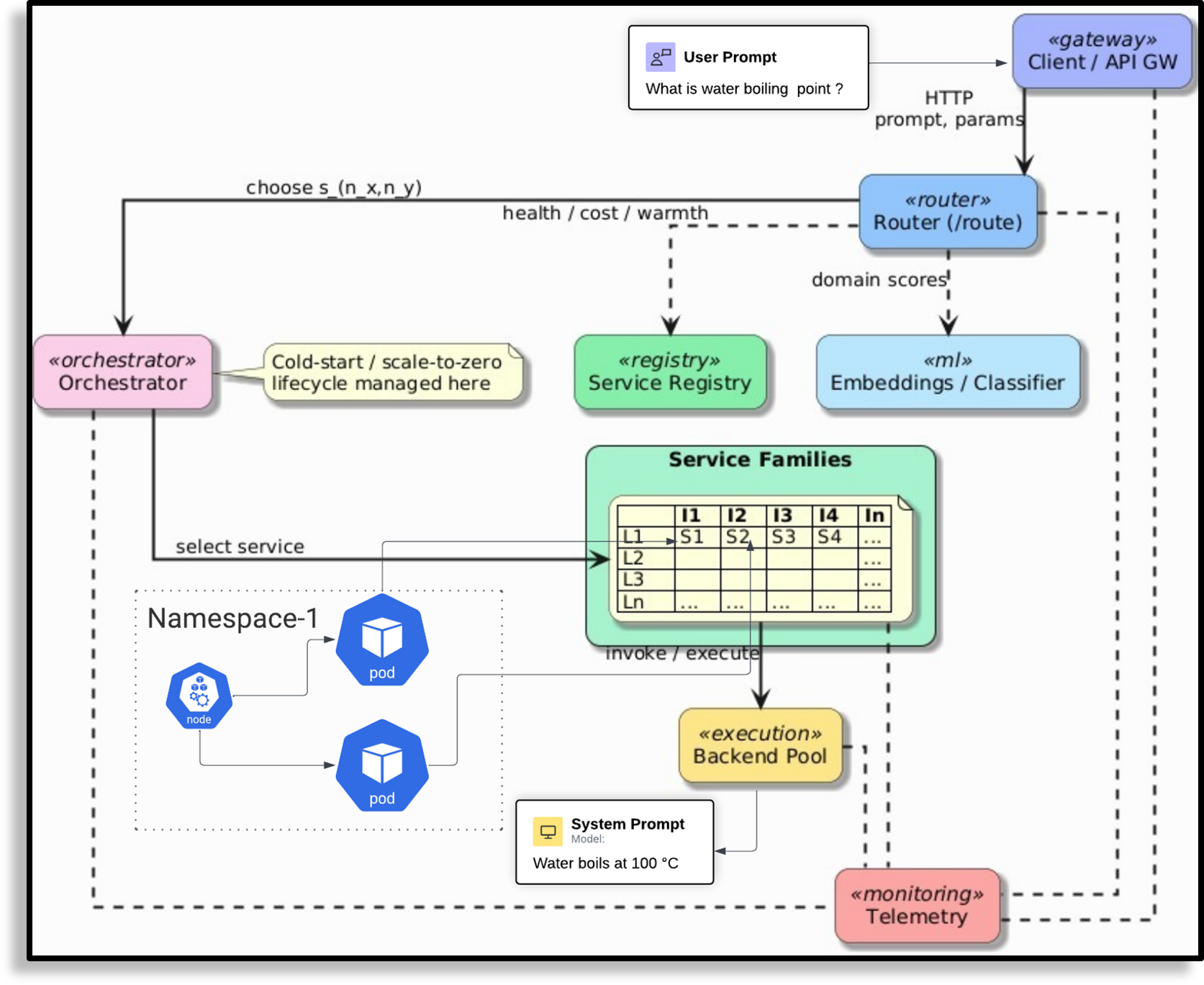
核心思路:论文的核心思路是构建一个基于Kubernetes的LLM编排框架,该框架能够动态地管理和调度多个LLM模型,并根据请求的特性智能地选择最优模型进行推理。通过自适应的scale-to-zero机制降低空闲模型的资源占用,并采用混合路由策略优化请求的响应时间和成本。
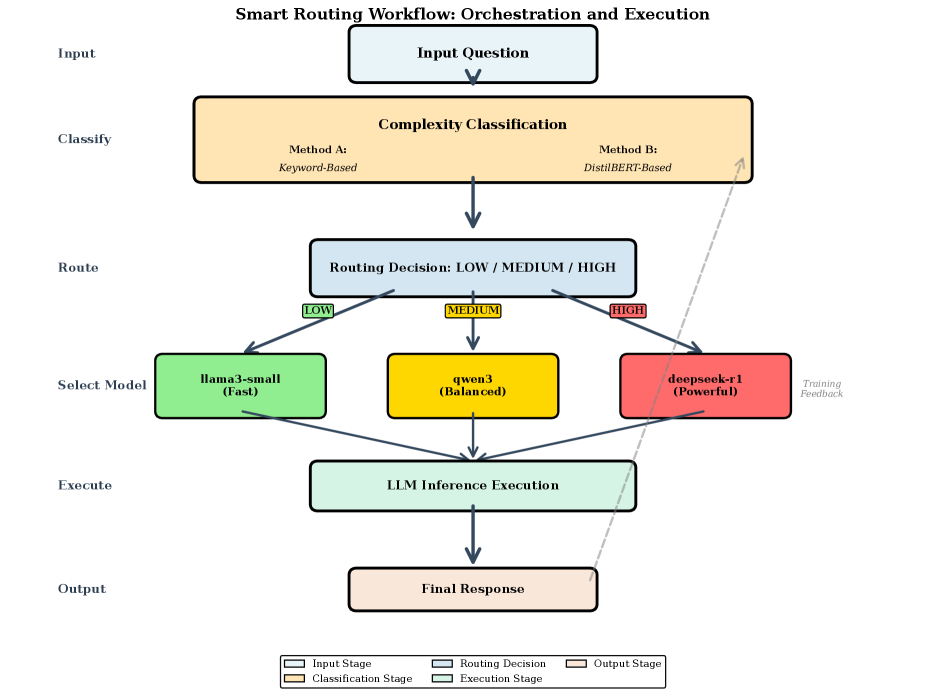
技术框架:Pick and Spin框架主要包含三个核心模块:1) 统一的基于Helm的部署系统,简化了LLM模型的部署和管理;2) 自适应的scale-to-zero自动化,根据负载动态调整模型的副本数量,降低资源消耗;3) 混合路由模块,结合关键字启发式方法和轻量级DistilBERT分类器,根据请求的特性选择最优模型进行推理。整体流程为:用户发起请求,路由模块根据请求内容选择合适的模型,如果模型未启动,则自动启动,进行推理,推理完成后,根据负载情况决定是否缩减模型副本数量。
关键创新:该论文的关键创新在于混合路由策略,它结合了简单的关键字启发式方法和轻量级的DistilBERT分类器。关键字启发式方法可以快速过滤掉明显不适合的模型,而DistilBERT分类器则可以更准确地评估请求与模型之间的匹配程度。这种混合策略在保证准确性的同时,降低了路由决策的计算成本。
关键设计:在混合路由模块中,关键字启发式方法基于预定义的关键词列表,快速排除不相关的模型。DistilBERT分类器使用少量数据进行微调,以适应不同LLM模型的特性。Scale-to-zero自动化模块通过监控GPU利用率和请求队列长度,动态调整模型的副本数量。具体的参数设置和损失函数等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Pick and Spin框架在多个基准数据集上显著优于静态部署方案。具体而言,Pick and Spin实现了高达21.6%的更高成功率,30%的更低延迟,以及33%的更低GPU成本。这些结果验证了Pick and Spin框架在提高资源利用率、降低延迟和成本方面的有效性。
🎯 应用场景
Pick and Spin框架可应用于需要自托管LLM的各种场景,例如金融、医疗和法律等对数据隐私和安全有严格要求的行业。该框架能够帮助企业更经济高效地利用GPU资源,并根据实际需求定制LLM服务,从而提高生产效率和降低运营成本。未来,该框架可以进一步扩展到支持更多类型的LLM模型和推理策略,并集成更高级的资源管理和调度算法。
📄 摘要(原文)
Self-hosting large language models (LLMs) is increasingly appealing for organizations seeking privacy, cost control, and customization. Yet deploying and maintaining in-house models poses challenges in GPU utilization, workload routing, and reliability. We introduce Pick and Spin, a practical framework that makes self-hosted LLM orchestration scalable and economical. Built on Kubernetes, it integrates a unified Helm-based deployment system, adaptive scale-to-zero automation, and a hybrid routing module that balances cost, latency, and accuracy using both keyword heuristics and a lightweight DistilBERT classifier. We evaluate four models, Llama-3 (90B), Gemma-3 (27B), Qwen-3 (235B), and DeepSeek-R1 (685B) across eight public benchmark datasets, with five inference strategies, and two routing variants encompassing 31,019 prompts and 163,720 inference runs. Pick and Spin achieves up to 21.6% higher success rates, 30% lower latency, and 33% lower GPU cost per query compared with static deployments of the same models.