HalluMat: Detecting Hallucinations in LLM-Generated Materials Science Content Through Multi-Stage Verification
作者: Bhanu Prakash Vangala, Sajid Mahmud, Pawan Neupane, Joel Selvaraj, Jianlin Cheng
分类: cs.AI, cond-mat.mtrl-sci, cs.IR
发布日期: 2025-12-26
💡 一句话要点
提出HalluMatDetector,通过多阶段验证检测LLM在材料科学内容生成中的幻觉问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 材料科学 多阶段验证 知识检索
📋 核心要点
- 大型语言模型在材料科学领域的应用面临幻觉问题,即生成不准确或误导性信息,影响研究可靠性。
- HalluMatDetector通过多阶段验证,包括内在验证、多源检索和矛盾图分析,来检测和减轻LLM的幻觉。
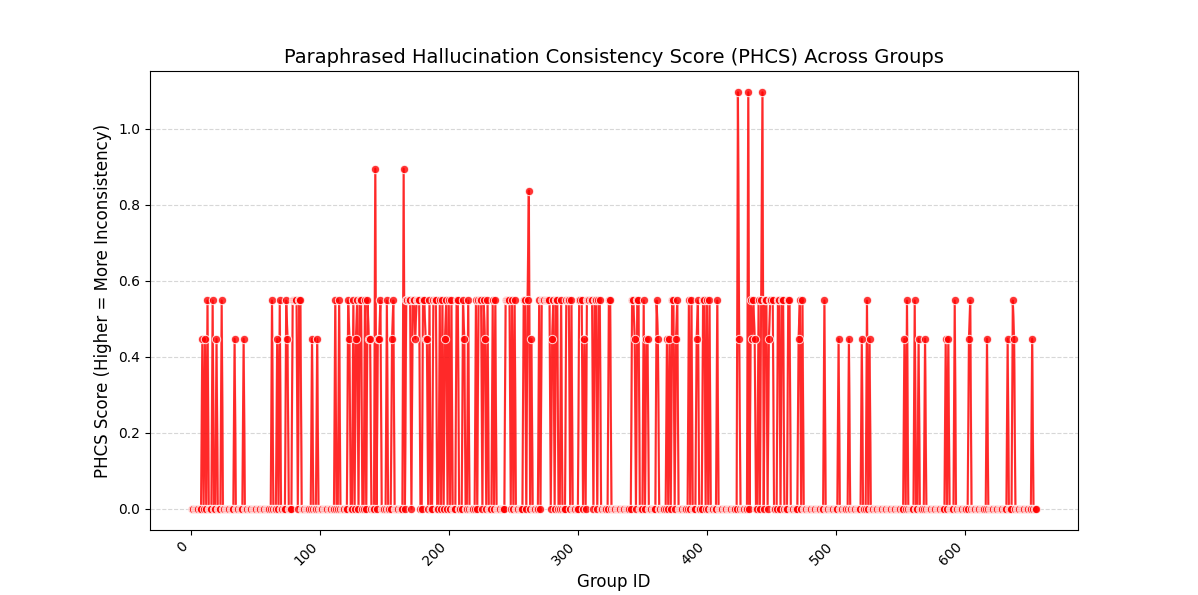
- 实验表明,HalluMatDetector能有效降低30%的幻觉率,并提出了PHCS评分来评估LLM在语义等价查询中的一致性。
📝 摘要(中文)
人工智能,特别是大型语言模型(LLMs),正在变革科学发现,实现快速知识生成和假设构建。然而,一个关键挑战是幻觉,即LLMs生成的事实不正确或具有误导性的信息,从而损害研究的完整性。为了解决这个问题,我们引入了HalluMatData,这是一个用于评估幻觉检测方法、事实一致性和AI生成材料科学内容中响应鲁棒性的基准数据集。与此同时,我们提出了HalluMatDetector,这是一个多阶段幻觉检测框架,它集成了内在验证、多源检索、矛盾图分析和基于度量的评估,以检测和减轻LLM幻觉。我们的研究结果表明,幻觉水平在材料科学的各个子领域中差异显著,高熵查询表现出更大的事实不一致性。通过利用HalluMatDetector验证流程,与标准LLM输出相比,我们降低了30%的幻觉率。此外,我们引入了释义幻觉一致性评分(PHCS)来量化LLM在语义等效查询中响应的不一致性,从而更深入地了解模型的可靠性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成材料科学相关内容时出现的“幻觉”问题,即生成不真实、不准确或与已知事实相悖的信息。现有方法缺乏有效的幻觉检测机制,导致研究人员难以信任LLM生成的内容,阻碍了其在材料科学领域的应用。现有方法的痛点在于无法准确识别和量化LLM生成内容中的错误信息,缺乏针对材料科学领域的特定验证策略。
核心思路:论文的核心思路是构建一个多阶段的验证框架,通过整合多种信息源和验证方法,对LLM生成的内容进行全面评估,从而有效检测和减轻幻觉。该框架的设计理念是利用内在知识、外部知识和一致性分析等多重保障,提高幻觉检测的准确性和可靠性。
技术框架:HalluMatDetector框架包含以下主要阶段:1. 内在验证:利用LLM自身的知识进行初步验证。2. 多源检索:从多个权威的材料科学数据库和文献中检索相关信息。3. 矛盾图分析:构建矛盾图,识别LLM生成内容与检索到的外部信息之间的矛盾之处。4. 基于度量的评估:使用PHCS(Paraphrased Hallucination Consistency Score)等指标量化幻觉程度。整个流程旨在通过多层验证,逐步排除LLM生成内容中的错误信息。
关键创新:该论文的关键创新在于提出了一个针对材料科学领域的、多阶段的幻觉检测框架HalluMatDetector,并构建了相应的基准数据集HalluMatData。与现有方法相比,HalluMatDetector更加注重领域知识的整合和多源信息的验证,能够更准确地检测材料科学领域的幻觉。此外,PHCS评分的提出为量化LLM生成内容的一致性提供了一种新的方法。
关键设计:HalluMatDetector的关键设计包括:1. 多源检索策略:选择权威的材料科学数据库和文献作为信息来源,确保检索到的信息具有较高的可信度。2. 矛盾图构建方法:设计有效的算法,自动识别LLM生成内容与检索到的外部信息之间的矛盾之处。3. PHCS评分计算方法:定义合理的指标,量化LLM在语义等价查询中响应的不一致性。具体参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HalluMatDetector能够有效降低LLM在材料科学内容生成中的幻觉率,与标准LLM输出相比,幻觉率降低了30%。此外,研究还发现,幻觉水平在材料科学的各个子领域中差异显著,高熵查询更容易产生事实不一致性。PHCS评分的引入为量化LLM生成内容的一致性提供了新的手段。
🎯 应用场景
该研究成果可应用于材料科学研究的各个环节,例如辅助材料设计、加速文献综述、验证实验结果等。通过降低LLM生成内容中的幻觉,提高其可靠性,可以加速材料科学的发现进程,并为科研人员提供更值得信赖的AI助手。未来,该方法可以推广到其他科学领域,提高AI在科学研究中的应用价值。
📄 摘要(原文)
Artificial Intelligence (AI), particularly Large Language Models (LLMs), is transforming scientific discovery, enabling rapid knowledge generation and hypothesis formulation. However, a critical challenge is hallucination, where LLMs generate factually incorrect or misleading information, compromising research integrity. To address this, we introduce HalluMatData, a benchmark dataset for evaluating hallucination detection methods, factual consistency, and response robustness in AI-generated materials science content. Alongside this, we propose HalluMatDetector, a multi-stage hallucination detection framework that integrates intrinsic verification, multi-source retrieval, contradiction graph analysis, and metric-based assessment to detect and mitigate LLM hallucinations. Our findings reveal that hallucination levels vary significantly across materials science subdomains, with high-entropy queries exhibiting greater factual inconsistencies. By utilizing HalluMatDetector verification pipeline, we reduce hallucination rates by 30% compared to standard LLM outputs. Furthermore, we introduce the Paraphrased Hallucination Consistency Score (PHCS) to quantify inconsistencies in LLM responses across semantically equivalent queries, offering deeper insights into model reliability.