AI-Generated Code Is Not Reproducible (Yet): An Empirical Study of Dependency Gaps in LLM-Based Coding Agents
作者: Bhanu Prakash Vangala, Ali Adibifar, Ashish Gehani, Tanu Malik
分类: cs.SE, cs.AI, cs.MA
发布日期: 2025-12-26 (更新: 2026-02-03)
💡 一句话要点
研究表明:AI生成的代码在干净环境中难以复现,存在显著依赖缺失问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代码生成 代码可复现性 依赖分析 软件工程 实证研究
📋 核心要点
- 现有研究缺乏对LLM生成代码在干净环境中可复现性的深入评估,难以保证软件开发的可靠性。
- 论文提出三层依赖框架,区分声明、工作和运行时依赖,量化LLM生成代码的可复现性。
- 实验结果表明,LLM生成代码的可复现性较低,且存在大量未声明的隐藏依赖,不同语言间差异显著。
📝 摘要(中文)
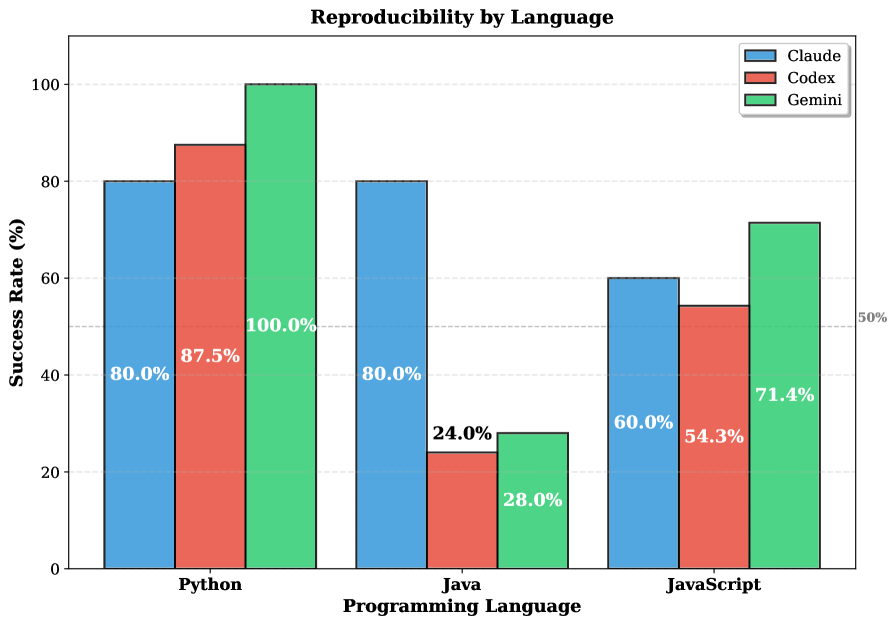
大型语言模型(LLM)作为代码生成代理,有望加速软件开发,但其生成代码的可复现性在很大程度上未被探索。本文进行了一项实证研究,旨在调查LLM生成的代码是否能在仅使用操作系统软件包和模型指定依赖项的干净环境中成功执行。我们评估了三种最先进的LLM代码生成代理(Claude Code、OpenAI Codex和Gemini),针对Python、JavaScript和Java中的100个标准化提示生成的300个项目。我们引入了一个三层依赖框架(区分声明的、工作的和运行时的依赖项)来量化执行可复现性。结果表明,只有68.3%的项目能够开箱即用,并且不同语言之间存在显著差异(Python 89.2%,Java 44.0%)。我们还发现从声明的依赖项到实际运行时依赖项平均扩展了13.5倍,揭示了显著的隐藏依赖项。
🔬 方法详解
问题定义:论文旨在解决LLM生成代码在干净环境中执行的可复现性问题。现有方法缺乏对LLM生成代码依赖关系的全面分析,导致生成的代码难以在新的环境中运行,阻碍了LLM在软件开发中的应用。
核心思路:论文的核心思路是通过构建一个三层依赖框架,量化LLM生成代码的声明依赖、工作依赖和运行时依赖,从而评估其可复现性。通过比较不同层次的依赖关系,可以发现LLM在依赖声明方面的不足,并为改进LLM的代码生成能力提供指导。
技术框架:论文采用实证研究的方法,首先选取三种主流的LLM代码生成代理(Claude Code、OpenAI Codex和Gemini),然后针对Python、JavaScript和Java三种编程语言,使用100个标准化提示生成300个项目。接着,使用三层依赖框架分析每个项目的依赖关系,最后统计分析实验结果,评估LLM生成代码的可复现性。
关键创新:论文的关键创新在于提出了三层依赖框架,该框架能够全面地描述LLM生成代码的依赖关系,包括声明的依赖、实际工作的依赖和运行时依赖。通过区分这三个层次的依赖关系,可以更准确地评估LLM生成代码的可复现性,并发现隐藏的依赖关系。
关键设计:三层依赖框架的具体定义如下:声明的依赖是指LLM在生成的代码中明确声明的依赖项;工作的依赖是指在没有安装所有声明的依赖项的情况下,代码能够成功执行所需的最小依赖项集合;运行时依赖是指代码在完全安装声明的依赖项后,实际运行所需的依赖项集合。论文通过自动化工具和人工分析相结合的方式,确定每个项目的这三个层次的依赖关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,只有68.3%的LLM生成项目能够开箱即用,Python项目的可复现性最高(89.2%),Java项目最低(44.0%)。从声明的依赖项到实际运行时依赖项平均扩展了13.5倍,揭示了LLM生成代码存在显著的隐藏依赖问题。
🎯 应用场景
该研究成果可应用于评估和改进LLM代码生成代理的可靠性,提高生成代码的可复现性,从而加速软件开发流程。此外,该研究提出的三层依赖框架可用于分析和管理软件项目的依赖关系,降低软件维护成本。
📄 摘要(原文)
The rise of Large Language Models (LLMs) as coding agents promises to accelerate software development, but their impact on generated code reproducibility remains largely unexplored. This paper presents an empirical study investigating whether LLM-generated code can be executed successfully in a clean environment with only OS packages and using only the dependencies that the model specifies. We evaluate three state-of-the-art LLM coding agents (Claude Code, OpenAI Codex, and Gemini) across 300 projects generated from 100 standardized prompts in Python, JavaScript, and Java. We introduce a three-layer dependency framework (distinguishing between claimed, working, and runtime dependencies) to quantify execution reproducibility. Our results show that only 68.3% of projects execute out-of-the-box, with substantial variation across languages (Python 89.2%, Java 44.0%). We also find a 13.5 times average expansion from declared to actual runtime dependencies, revealing significant hidden dependencies.