Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
作者: Mengkang Hu, Bowei Xia, Yuran Wu, Ailing Yu, Yude Zou, Qiguang Chen, Shijian Wang, Jiarui Jin, Kexin Li, Wenxiang Jiao, Yuan Lu, Ping Luo
分类: cs.AI, cs.CL
发布日期: 2025-12-26
备注: 48 pages, 15 tables, 7 figures, Project page: https://agent2world.github.io
💡 一句话要点
Agent2World:通过自适应多智能体反馈学习生成符号世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 多智能体系统 强化学习 符号推理 模型生成 自适应反馈 LLM 规划领域定义语言
📋 核心要点
- 现有方法在训练LLM生成世界模型时,缺乏大规模可验证的监督,且静态验证难以发现交互执行中的行为级错误。
- Agent2World通过多智能体框架,利用工具增强和多智能体反馈,实现了更强的世界模型生成能力,并构建了监督微调的数据引擎。
- 实验表明,Agent2World在PDDL和可执行代码表示的基准测试中取得了SOTA结果,微调后模型性能平均提升30.95%。
📝 摘要(中文)
符号世界模型(例如,PDDL领域或可执行模拟器)是基于模型的规划的核心,但训练LLM生成此类世界模型受到缺乏大规模可验证监督的限制。目前的方法主要依赖于静态验证方法,无法捕捉交互执行中产生的行为级错误。本文提出了Agent2World,一个工具增强的多智能体框架,通过将生成建立在多智能体反馈的基础上,实现了强大的推理时世界模型生成,并且可以作为监督微调的数据引擎。Agent2World遵循一个三阶段流程:(i)深度研究员智能体通过网络搜索执行知识合成,以解决规范差距;(ii)模型开发者智能体实现可执行的世界模型;(iii)专门的测试团队进行自适应单元测试和基于模拟的验证。Agent2World在跨越规划领域定义语言(PDDL)和可执行代码表示的三个基准测试中展示了卓越的推理时性能,实现了持续的最先进的结果。除了推理之外,测试团队还充当模型开发者的交互环境,提供行为感知的自适应反馈,从而产生多轮训练轨迹。在这些轨迹上微调的模型显着改善了世界模型的生成,与训练前的同一模型相比,平均相对增益为30.95%。项目页面:https://agent2world.github.io。
🔬 方法详解
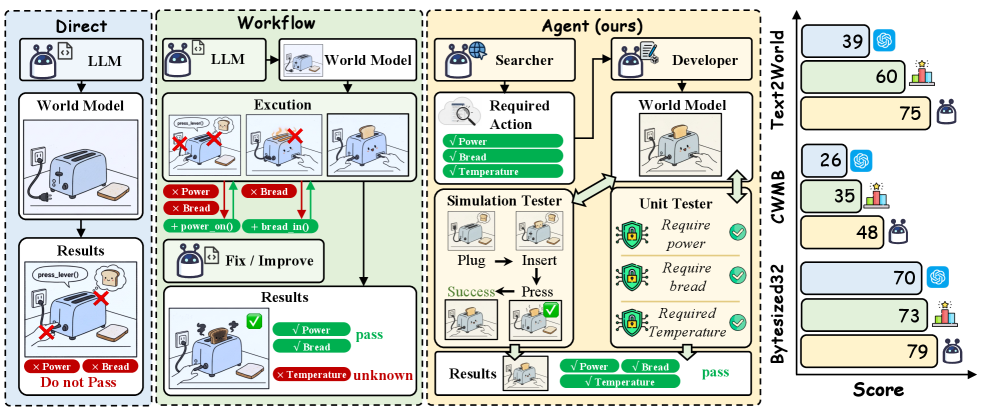
问题定义:论文旨在解决如何有效地训练大型语言模型(LLM)生成高质量的符号世界模型,例如PDDL领域定义或可执行的模拟器。现有方法主要依赖静态验证,无法捕捉到在交互式执行过程中产生的行为层面的错误,导致生成的模型在实际应用中表现不佳。缺乏大规模、可验证的监督数据也是一个关键痛点。
核心思路:论文的核心思路是利用多智能体框架,通过智能体之间的交互和反馈来指导世界模型的生成和优化。具体来说,通过引入一个“测试团队”来对生成的模型进行动态的、行为层面的验证,并利用测试结果为模型开发者提供自适应的反馈,从而实现模型的迭代改进。这种方法将世界模型的生成过程置于一个动态的、交互式的环境中,使其能够更好地适应实际应用的需求。
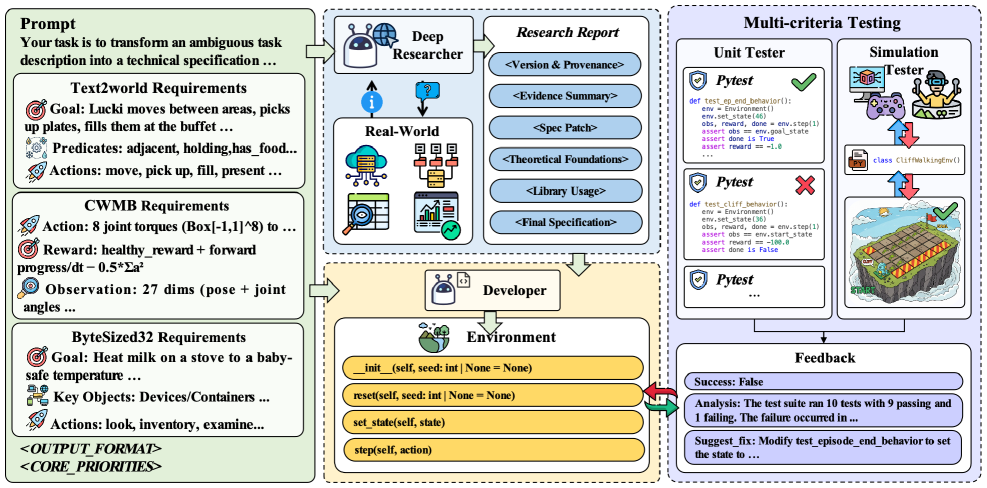
技术框架:Agent2World框架包含三个主要阶段:(1) 深度研究员智能体:负责通过网络搜索等方式进行知识合成,填补世界模型规范中的空白。(2) 模型开发者智能体:负责根据研究员提供的知识,实现可执行的世界模型,例如PDDL代码或可执行的模拟器。(3) 测试团队:负责对模型开发者生成的模型进行自适应的单元测试和基于模拟的验证,并向模型开发者提供反馈。整个流程是一个迭代的过程,模型开发者根据测试团队的反馈不断改进模型。
关键创新:该论文的关键创新在于提出了一个基于多智能体反馈的框架,用于生成和优化符号世界模型。与传统的静态验证方法相比,Agent2World能够捕捉到在交互式执行过程中产生的行为层面的错误,并利用这些错误来指导模型的改进。此外,该框架还能够自动生成用于监督微调的数据,从而进一步提升模型的性能。
关键设计:测试团队的设计是关键。它需要能够进行自适应的单元测试,即根据模型的当前状态和行为,动态地调整测试用例。同时,测试团队还需要能够提供行为感知的反馈,即能够指出模型在哪些方面存在不足,并给出改进的建议。论文中可能还涉及到一些具体的参数设置,例如智能体的数量、学习率、损失函数等,但摘要中没有明确说明。
🖼️ 关键图片

📊 实验亮点
Agent2World在三个基准测试中取得了SOTA结果,证明了其在世界模型生成方面的优越性。通过在测试团队提供的反馈数据上进行微调,模型性能平均提升了30.95%,表明了自适应多智能体反馈在模型优化中的有效性。这些实验结果表明Agent2World是一种有前景的世界模型生成方法。
🎯 应用场景
Agent2World的研究成果可以应用于机器人、游戏AI、自动化规划等领域。高质量的符号世界模型能够帮助智能体更好地理解和预测环境,从而做出更合理的决策。该研究有望推动模型驱动的强化学习和规划技术的发展,并为构建更智能、更自主的智能体提供新的思路。
📄 摘要(原文)
Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.