Analysis of LLM Vulnerability to GPU Soft Errors: An Instruction-Level Fault Injection Study
作者: Duo Chai, Zizhen Liu, Shuhuai Wang, Songwei Pei, Cheng Liu, Huawei Li, Shangguang Wang
分类: cs.AR, cs.AI, cs.CR
发布日期: 2025-12-25
备注: 14 pages, 13 figures
💡 一句话要点
首个LLM指令级GPU软错误注入分析,揭示模型架构、规模和任务复杂度的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 GPU软错误 指令级故障注入 可靠性分析 容错机制
📋 核心要点
- 现有GPU可靠性研究主要集中在通用应用或传统视觉模型,缺乏对大规模LLM的系统性分析,无法充分了解LLM在实际应用中的可靠性。
- 该论文通过指令级故障注入方法,系统性地分析了LLM在GPU上推理时对软错误的抵抗能力,并从模型架构、参数规模和任务复杂度等多角度进行了评估。
- 研究结果揭示了LLM在不同配置和任务下的可靠性特征,为设计更有效的LLM容错机制提供了新的思路和数据支撑。
📝 摘要(中文)
大型语言模型(LLM)对高性能GPU提出了极高的计算和内存需求。同时,晶体管尺寸缩小和工作电压降低使得GPU更容易受到软错误的影响。虽然之前的研究已经考察了GPU的可靠性,但大多集中在通用应用程序或用于视觉任务的传统神经网络上。相比之下,对现代大规模LLM的系统分析仍然有限,尽管它们在各种应用场景中被迅速采用。鉴于LLM的独特特性,它们对软错误的抵抗力可能与早期模型有很大不同。为了弥合这一差距,我们首次对LLM推理进行了指令级故障注入研究。我们的方法从多个角度揭示了可靠性特征,突出了模型架构、参数规模和任务复杂性的影响。这些发现为LLM的可靠性提供了新的见解,并为设计更有效的容错机制提供了信息。
🔬 方法详解
问题定义:论文旨在解决LLM在GPU上运行时,由于软错误导致的可靠性问题。现有研究对LLM的可靠性分析不足,无法有效评估LLM在实际部署中面临的风险。传统GPU可靠性研究主要关注通用计算或视觉任务,其结论难以直接应用于LLM。
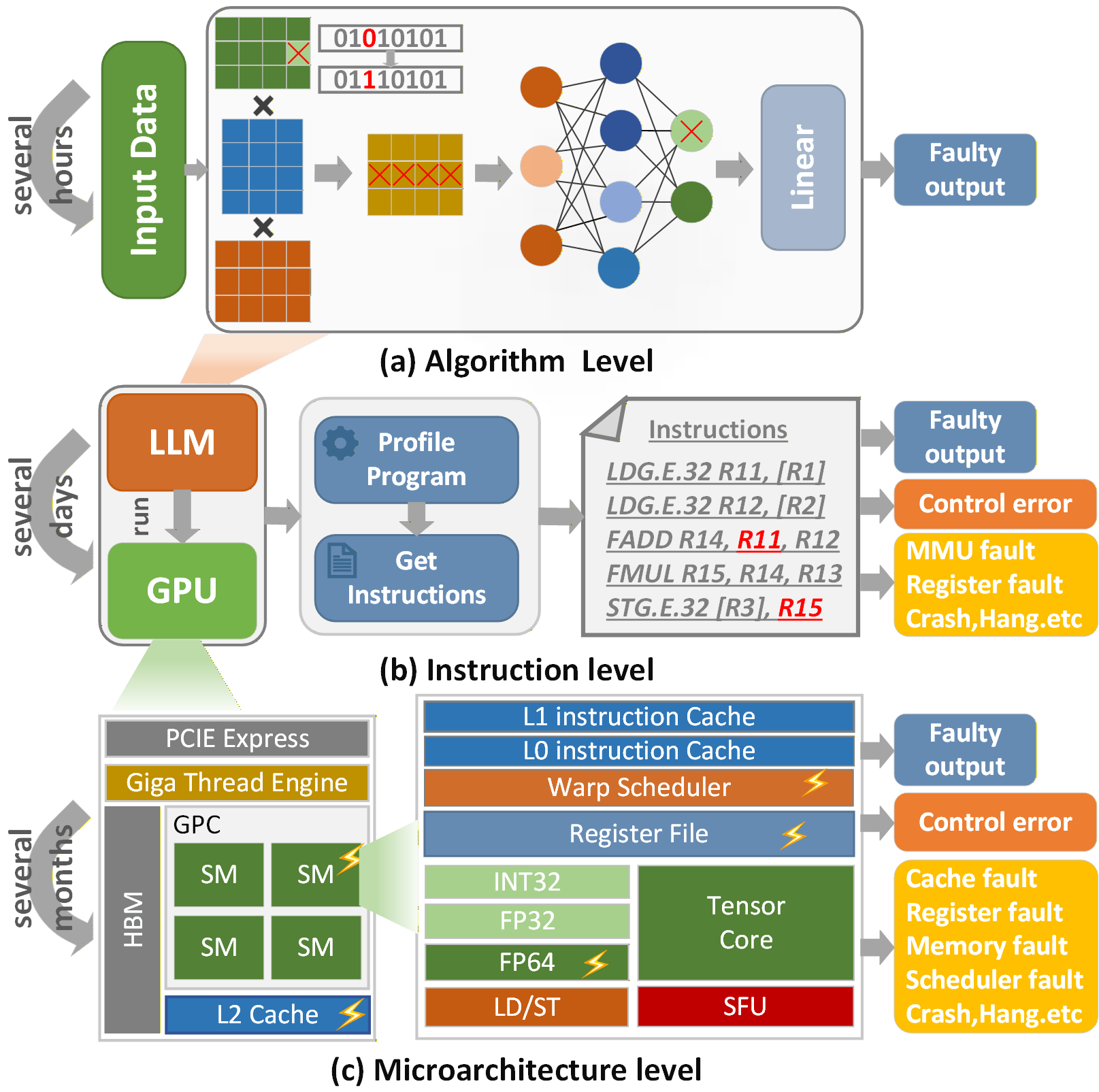
核心思路:论文的核心思路是通过指令级故障注入,模拟GPU运行时可能发生的软错误,并观察这些错误对LLM推理结果的影响。通过分析不同模型架构、参数规模和任务复杂度下的错误传播模式,揭示LLM的可靠性特征。
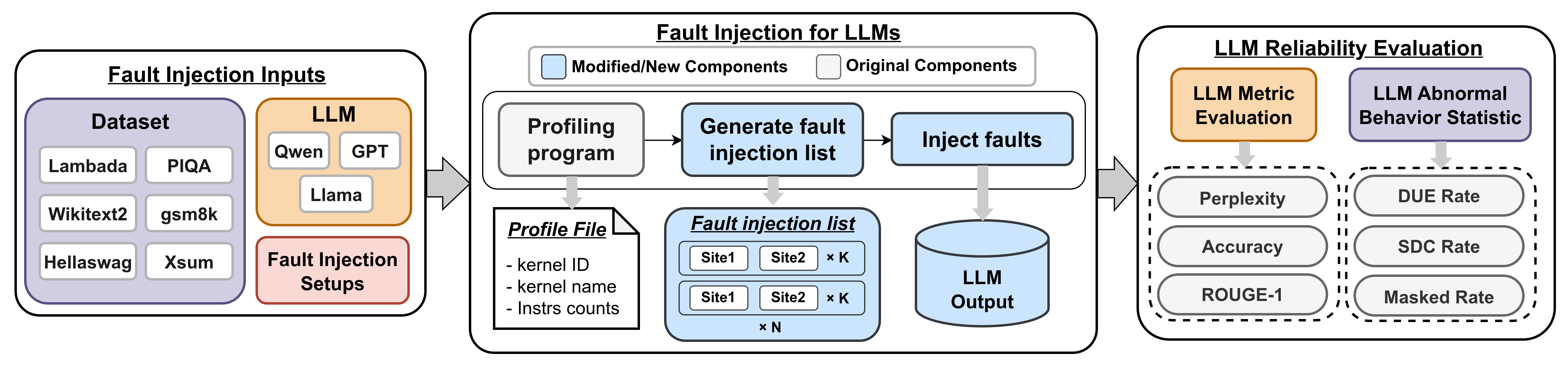
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择具有代表性的LLM模型;2) 在GPU上运行LLM推理过程;3) 在指令级别注入软错误;4) 监控LLM的输出结果,并与无错误运行的结果进行比较;5) 分析错误类型、传播路径和影响程度,从而评估LLM的可靠性。
关键创新:该研究的关键创新在于首次将指令级故障注入技术应用于LLM的可靠性分析。与传统的硬件级别或模型级别的故障注入相比,指令级故障注入能够更精确地模拟GPU运行时可能发生的软错误,并提供更细粒度的错误信息。此外,该研究还系统地分析了模型架构、参数规模和任务复杂度对LLM可靠性的影响,为LLM的容错设计提供了新的视角。
关键设计:研究中,故障注入的位置选择在GPU指令级别,具体选择哪些指令进行注入,以及注入的错误类型(如bit-flip)是关键设计。此外,如何定义和量化LLM的输出结果的“错误”也是一个重要设计,需要根据具体的LLM任务(如文本生成、问答等)来确定。
🖼️ 关键图片
📊 实验亮点
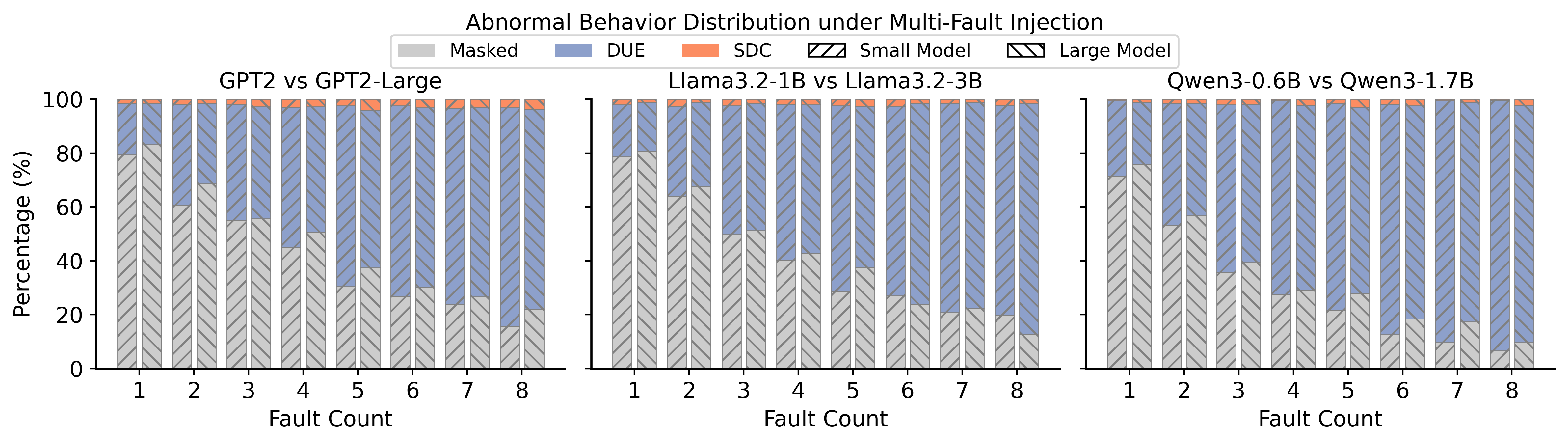
该研究通过指令级故障注入,揭示了LLM对GPU软错误的敏感性。实验结果表明,模型架构、参数规模和任务复杂度都会显著影响LLM的可靠性。例如,某些模型架构对特定类型的软错误更敏感,而更大的模型规模可能会增加错误传播的概率。这些发现为设计更有效的LLM容错机制提供了重要依据。
🎯 应用场景
该研究成果可应用于提升LLM在各种场景下的可靠性,例如云计算、边缘计算和移动设备。通过了解LLM对软错误的敏感性,可以设计更有效的容错机制,降低LLM部署的风险,并提高LLM服务的可用性和稳定性。此外,该研究还可以指导LLM的硬件加速器设计,使其更具鲁棒性。
📄 摘要(原文)
Large language models (LLMs) are highly compute- and memory-intensive, posing significant demands on high-performance GPUs. At the same time, advances in GPU technology driven by shrinking transistor sizes and lower operating voltages have made these devices increasingly susceptible to soft errors. While prior work has examined GPU reliability, most studies have focused on general-purpose applications or conventional neural networks mostly used for vision tasks such as classification and detection. In contrast, systematic analysis of modern large-scale LLMs remains limited, despite their rapid adoption in diverse application scenarios. Given the unique characteristics of LLMs, their resilience to soft errors may differ substantially from earlier models. To bridge this gap, we conduct the first instruction-level fault injection study of LLM inference. Our approach reveals reliability characteristics from multiple perspectives, highlighting the effects of model architecture, parameter scale, and task complexity. These findings provide new insights into LLM reliability and inform the design of more effective fault tolerance mechanisms.