LLM-I2I: Boost Your Small Item2Item Recommendation Model with Large Language Model
作者: Yinfu Feng, Yanjing Wu, Rong Xiao, Xiaoyi Zen
分类: cs.IR, cs.AI
发布日期: 2025-12-25
💡 一句话要点
LLM-I2I:利用大语言模型提升小规模Item2Item推荐模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Item2Item推荐 大型语言模型 数据增强 数据清洗 长尾物品 推荐系统 数据稀疏性
📋 核心要点
- 现有I2I推荐模型在处理数据稀疏和噪声交互时面临挑战,尤其是在长尾物品上表现不佳。
- LLM-I2I框架利用LLM生成高质量的合成交互数据,并过滤噪声数据,从而提升I2I模型的性能。
- 实验结果表明,LLM-I2I在多个数据集上显著提高了推荐准确率和业务指标,尤其是在长尾物品方面。
📝 摘要(中文)
Item2Item (I2I) 推荐模型因其可扩展性、实时性和高质量的推荐效果而被广泛应用于实际系统中。提升I2I性能的研究主要集中在两个方向:1) 模型中心方法,采用更深层的架构,但面临计算成本和部署复杂性增加的风险;2) 数据中心方法,在不改变模型的情况下优化训练数据,具有成本效益,但难以应对数据稀疏和噪声问题。为了解决这些挑战,我们提出了LLM-I2I,一个利用大型语言模型(LLM)来缓解数据质量问题的数据中心框架。LLM-I2I包括(1)一个基于LLM的生成器,用于合成长尾物品的用户-物品交互,缓解数据稀疏性,以及(2)一个基于LLM的判别器,用于过滤来自真实和合成数据的噪声交互。然后融合优化后的数据来训练I2I模型。在工业界(AEDS)和学术界(ARD)数据集上的评估表明,LLM-I2I始终提高推荐准确性,尤其是在长尾物品方面。部署在大型跨境电商平台上,与现有的I2I模型相比,召回率(RN)提高了6.02%,商品交易总额(GMV)提高了1.22%。这项工作突出了LLM在增强数据中心推荐系统方面的潜力,而无需修改模型架构。
🔬 方法详解
问题定义:论文旨在解决Item2Item推荐模型在数据稀疏和噪声交互下,对长尾物品推荐效果不佳的问题。现有方法要么增加模型复杂度,导致计算成本上升;要么依赖数据增强,但难以有效应对数据质量问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成和判别能力,生成高质量的合成交互数据,并过滤噪声数据,从而提升I2I模型的训练数据质量,进而提高推荐性能。这样可以在不改变I2I模型结构的前提下,有效解决数据稀疏和噪声问题。
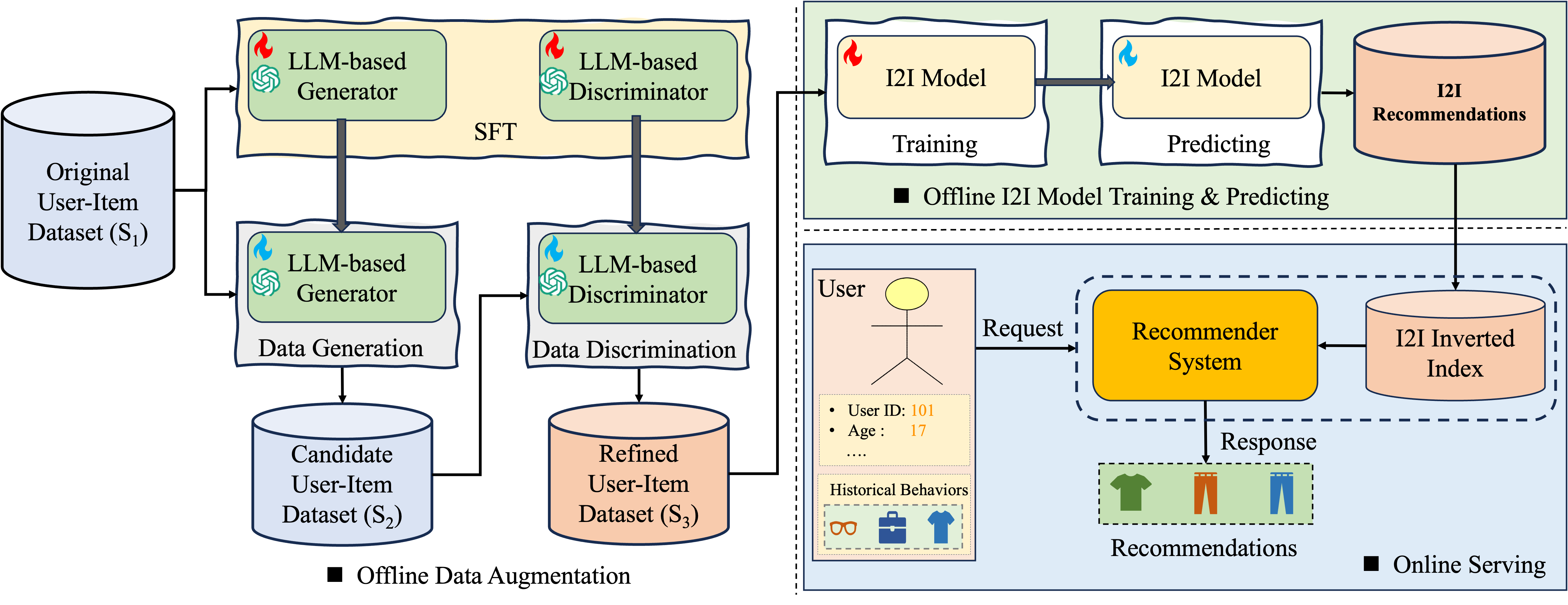
技术框架:LLM-I2I框架包含两个主要模块:LLM-based Generator和LLM-based Discriminator。首先,Generator利用LLM生成长尾物品的合成用户-物品交互数据,缓解数据稀疏性。然后,Discriminator利用LLM区分真实和合成数据中的噪声交互,并进行过滤。最后,将过滤后的真实数据和合成数据融合,用于训练I2I模型。
关键创新:该论文的关键创新在于利用LLM进行数据增强和清洗,而不是直接修改I2I模型结构。与传统的数据增强方法相比,LLM能够生成更具语义信息和更高质量的合成数据,并有效识别和过滤噪声数据。这使得LLM-I2I能够在不增加模型复杂度的前提下,显著提升I2I模型的性能。
关键设计:LLM-based Generator使用Prompt Engineering来指导LLM生成用户-物品交互数据,Prompt的设计需要考虑物品的属性、用户的偏好等因素。LLM-based Discriminator使用二分类模型来判断交互数据是否为噪声,损失函数采用交叉熵损失。具体LLM的选择和参数设置(如temperature)需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM-I2I在AEDS和ARD数据集上均取得了显著的性能提升。在AEDS数据集上,LLM-I2I将Recall@K提高了多个百分点。在部署到大型跨境电商平台后,与现有I2I模型相比,召回率(RN)提高了6.02%,商品交易总额(GMV)提高了1.22%。这些结果表明LLM-I2I在实际应用中具有显著的价值。
🎯 应用场景
LLM-I2I框架可广泛应用于电商、新闻、视频等领域的推荐系统,尤其适用于长尾物品推荐场景。该方法能够有效缓解数据稀疏和噪声问题,提升推荐准确率和用户体验,从而提高平台的用户活跃度和收入。未来,可以将LLM-I2I与其他推荐算法相结合,进一步提升推荐系统的整体性能。
📄 摘要(原文)
Item-to-Item (I2I) recommendation models are widely used in real-world systems due to their scalability, real-time capabilities, and high recommendation quality. Research to enhance I2I performance focuses on two directions: 1) model-centric approaches, which adopt deeper architectures but risk increased computational costs and deployment complexity, and 2) data-centric methods, which refine training data without altering models, offering cost-effectiveness but struggling with data sparsity and noise. To address these challenges, we propose LLM-I2I, a data-centric framework leveraging Large Language Models (LLMs) to mitigate data quality issues. LLM-I2I includes (1) an LLM-based generator that synthesizes user-item interactions for long-tail items, alleviating data sparsity, and (2) an LLM-based discriminator that filters noisy interactions from real and synthetic data. The refined data is then fused to train I2I models. Evaluated on industry (AEDS) and academic (ARD) datasets, LLM-I2I consistently improves recommendation accuracy, particularly for long-tail items. Deployed on a large-scale cross-border e-commerce platform, it boosts recall number (RN) by 6.02% and gross merchandise value (GMV) by 1.22% over existing I2I models. This work highlights the potential of LLMs in enhancing data-centric recommendation systems without modifying model architectures.