LogicLens: Visual-Logical Co-Reasoning for Text-Centric Forgery Analysis
作者: Fanwei Zeng, Changtao Miao, Jing Huang, Zhiya Tan, Shutao Gong, Xiaoming Yu, Yang Wang, Huazhe Tan, Weibin Yao, Jianshu Li
分类: cs.AI
发布日期: 2025-12-25
备注: 11 pages, 5 figures, 3 tables
💡 一句话要点
提出LogicLens,用于文本中心伪造分析的视觉-逻辑协同推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本伪造检测 视觉-文本协同推理 多任务学习 AIGC内容安全 零样本学习
📋 核心要点
- 现有文本中心伪造分析方法缺乏细粒度的视觉分析和复杂的推理能力,且通常将检测、定位和解释视为独立的子任务。
- LogicLens框架通过视觉-文本协同推理,将检测、定位和解释统一为联合任务,并利用Cross-Cues-aware Chain of Thought机制进行推理。
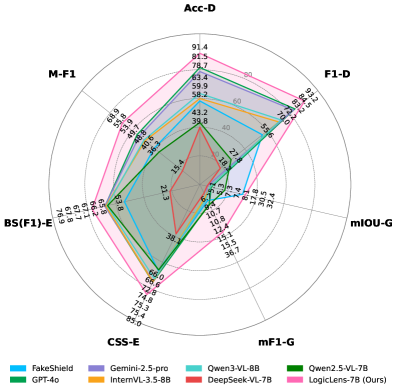
- 实验结果表明,LogicLens在多个数据集上超越现有方法,并在零样本评估中取得了显著的性能提升。
📝 摘要(中文)
本文针对AIGC快速发展带来的文本中心伪造问题,提出LogicLens框架,用于视觉-文本协同推理,将检测、定位和解释统一为联合任务。LogicLens通过Cross-Cues-aware Chain of Thought (CCT)机制,迭代地交叉验证视觉线索和文本逻辑。采用基于GRPO的加权多任务奖励函数,确保跨任务对齐。构建了PR$^2$ (Perceiver, Reasoner, Reviewer)流水线,生成高质量、认知对齐的标注数据。同时,构建了包含5,397张图像的RealText数据集,包含文本解释、像素级分割和真伪标签。实验表明,LogicLens在多个基准测试中表现出色,在T-IC13零样本评估中,宏平均F1得分超过专业框架41.4%,超过GPT-4o 23.4%。在T-SROIE数据集上,mF1、CSS和宏平均F1均显著优于其他基于MLLM的方法。数据集、模型和代码将公开。
🔬 方法详解
问题定义:本文旨在解决文本中心伪造分析问题,即识别图像中被篡改或伪造的文本信息。现有方法通常依赖于粗粒度的视觉特征,缺乏对文本逻辑的深入理解,并且将检测、定位和解释任务分离,忽略了它们之间的内在联系,导致性能受限。
核心思路:LogicLens的核心思路是利用视觉和文本信息进行协同推理,通过迭代地交叉验证视觉线索和文本逻辑,从而更准确地识别伪造文本。该方法将检测、定位和解释任务统一到一个框架中,利用多任务学习来提升整体性能。
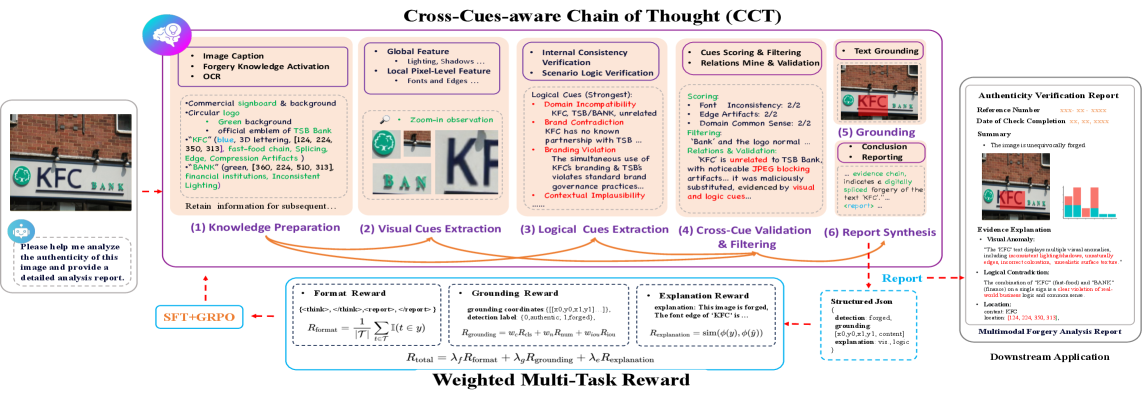
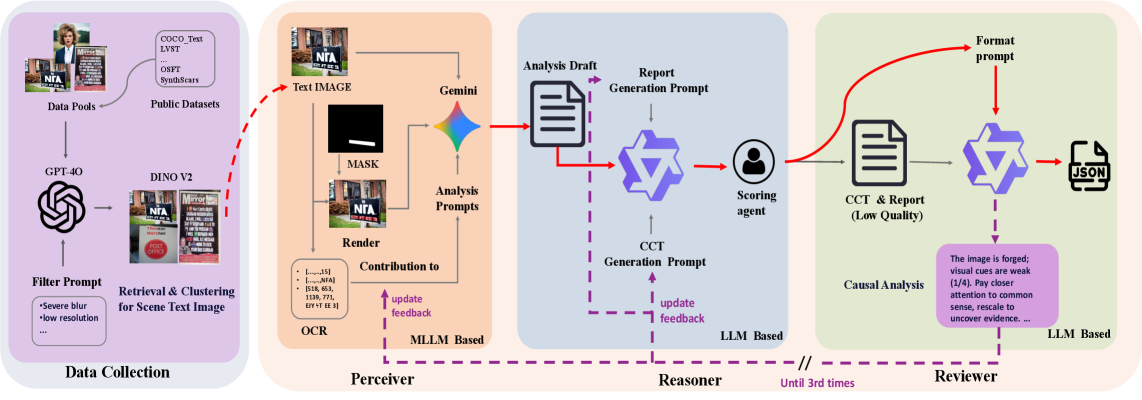
技术框架:LogicLens框架包含以下主要模块:1) Cross-Cues-aware Chain of Thought (CCT)机制,用于迭代地交叉验证视觉线索和文本逻辑;2) 基于GRPO的加权多任务奖励函数,用于确保跨任务对齐;3) PR$^2$ (Perceiver, Reasoner, Reviewer)流水线,用于生成高质量的标注数据。整体流程是,首先利用PR$^2$流水线生成标注数据,然后利用CCT机制进行视觉-文本协同推理,最后利用加权多任务奖励函数进行模型优化。
关键创新:LogicLens的关键创新在于Cross-Cues-aware Chain of Thought (CCT)机制,它能够迭代地交叉验证视觉线索和文本逻辑,从而实现更深入的推理。与现有方法相比,CCT机制能够更好地利用视觉和文本信息之间的互补性,从而提高伪造文本的识别准确率。
关键设计:论文中使用了GRPO(Gradient Reversal with Proximal Optimization)算法进行多任务学习,并设计了一个加权多任务奖励函数,用于平衡不同任务之间的损失。此外,PR$^2$流水线包含三个阶段:感知器(Perceiver)用于提取图像特征,推理器(Reasoner)用于生成文本解释,审查器(Reviewer)用于评估解释的质量。
🖼️ 关键图片
📊 实验亮点
LogicLens在T-IC13零样本评估中,宏平均F1得分超过专业框架41.4%,超过GPT-4o 23.4%。在T-SROIE数据集上,mF1、CSS和宏平均F1均显著优于其他基于MLLM的方法。这些结果表明,LogicLens在文本中心伪造分析方面具有显著的优势。
🎯 应用场景
LogicLens可应用于新闻真实性验证、社交媒体内容审核、金融欺诈检测等领域,有助于提高信息安全和网络环境的可靠性。该研究成果对于打击虚假信息传播、维护社会稳定具有重要意义,并为未来AIGC内容安全研究提供借鉴。
📄 摘要(原文)
Sophisticated text-centric forgeries, fueled by rapid AIGC advancements, pose a significant threat to societal security and information authenticity. Current methods for text-centric forgery analysis are often limited to coarse-grained visual analysis and lack the capacity for sophisticated reasoning. Moreover, they typically treat detection, grounding, and explanation as discrete sub-tasks, overlooking their intrinsic relationships for holistic performance enhancement. To address these challenges, we introduce LogicLens, a unified framework for Visual-Textual Co-reasoning that reformulates these objectives into a joint task. The deep reasoning of LogicLens is powered by our novel Cross-Cues-aware Chain of Thought (CCT) mechanism, which iteratively cross-validates visual cues against textual logic. To ensure robust alignment across all tasks, we further propose a weighted multi-task reward function for GRPO-based optimization. Complementing this framework, we first designed the PR$^2$ (Perceiver, Reasoner, Reviewer) pipeline, a hierarchical and iterative multi-agent system that generates high-quality, cognitively-aligned annotations. Then, we constructed RealText, a diverse dataset comprising 5,397 images with fine-grained annotations, including textual explanations, pixel-level segmentation, and authenticity labels for model training. Extensive experiments demonstrate the superiority of LogicLens across multiple benchmarks. In a zero-shot evaluation on T-IC13, it surpasses the specialized framework by 41.4% and GPT-4o by 23.4% in macro-average F1 score. Moreover, on the challenging dense-text T-SROIE dataset, it establishes a significant lead over other MLLM-based methods in mF1, CSS, and the macro-average F1. Our dataset, model, and code will be made publicly available.