Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
作者: Abhranil Chandra, Ayush Agrawal, Arian Hosseini, Sebastian Fischmeister, Rishabh Agarwal, Navin Goyal, Aaron Courville
分类: cs.AI, cs.LG
发布日期: 2025-12-24 (更新: 2026-01-22)
💡 一句话要点
利用错误CoT轨迹训练提升语言模型推理能力,关注数据分布而非绝对正确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 链式思考 语言模型 推理能力 数据分布 合成数据 自训练 知识蒸馏
📋 核心要点
- 现有方法依赖人工标注的CoT数据,成本高昂且分布可能与模型不匹配,限制了推理能力提升。
- 核心思想是利用更强模型生成的(即使是错误的)CoT轨迹进行训练,因为其分布更接近目标模型。
- 实验表明,使用合成CoT数据训练的模型在数学、算法推理和代码生成任务上优于人工标注数据。
📝 摘要(中文)
本文提出了一个令人惊讶的发现:通过使用更强大的模型生成的链式思考(CoT)轨迹合成数据集进行训练,即使这些轨迹最终都导致了错误的答案,也可以提高语言模型的推理能力。实验表明,这种方法在推理任务上可以产生比在人工标注数据集上训练更好的性能。作者假设,两个关键因素解释了这种现象:首先,合成数据的分布本质上更接近语言模型自身的分布,使其更易于学习。其次,这些“不正确”的轨迹通常只是部分存在缺陷,包含模型可以从中学习的有效推理步骤。为了进一步验证第一个假设,作者使用语言模型释义人工标注的轨迹,使其分布更接近模型自身的分布,并表明这可以提高性能。对于第二个假设,作者引入了越来越有缺陷的CoT轨迹,并研究模型对这些缺陷的容忍程度。作者在各种推理领域(如数学、算法推理和代码生成)中使用MATH、GSM8K、Countdown和MBPP数据集,在Qwen、Llama和Gemma等1.5B到9B的各种语言模型上展示了这些发现。研究表明,策划更接近模型分布的数据集是一个需要考虑的关键方面。作者还表明,正确的最终答案并不总是忠实推理过程的可靠指标。
🔬 方法详解
问题定义:论文旨在解决如何更有效地提升语言模型的推理能力的问题。现有方法主要依赖于人工标注的链式思考(Chain-of-Thought, CoT)数据,这种方法存在两个主要痛点:一是人工标注成本高昂,二是人工标注数据的分布可能与语言模型自身的分布存在差异,导致模型难以有效学习,从而限制了推理能力的提升。
核心思路:论文的核心思路是利用更强大的语言模型生成的合成CoT数据进行训练,即使这些合成数据最终给出的答案是错误的。作者认为,合成数据的分布更接近目标语言模型自身的分布,因此更容易被模型学习。此外,即使是错误的CoT轨迹,也可能包含部分正确的推理步骤,模型可以从中学习到有用的信息。
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用一个更强大的语言模型生成CoT轨迹,这些轨迹可能包含错误答案。2) 使用生成的CoT轨迹训练目标语言模型。3) 通过实验评估目标语言模型在各种推理任务上的性能。4) 通过释义人工标注数据,使其分布更接近模型自身,并评估性能提升。5) 通过引入不同程度错误的CoT轨迹,评估模型对错误的容忍度。
关键创新:论文最重要的技术创新点在于发现,即使是错误的CoT轨迹,只要其分布更接近目标语言模型,也能有效提升模型的推理能力。这挑战了传统上认为只有正确标注数据才能有效训练模型的观点。论文还创新性地提出了通过释义人工标注数据来调整数据分布的方法。
关键设计:论文的关键设计包括:1) 使用不同规模的语言模型(1.5B到9B)进行实验,包括Qwen、Llama和Gemma等模型。2) 在各种推理任务上进行评估,包括数学(MATH、GSM8K)、算法推理(Countdown)和代码生成(MBPP)。3) 通过实验分析不同程度错误的CoT轨迹对模型性能的影响。4) 使用语言模型释义人工标注数据,通过调整温度系数等参数来控制释义的多样性。
🖼️ 关键图片

📊 实验亮点
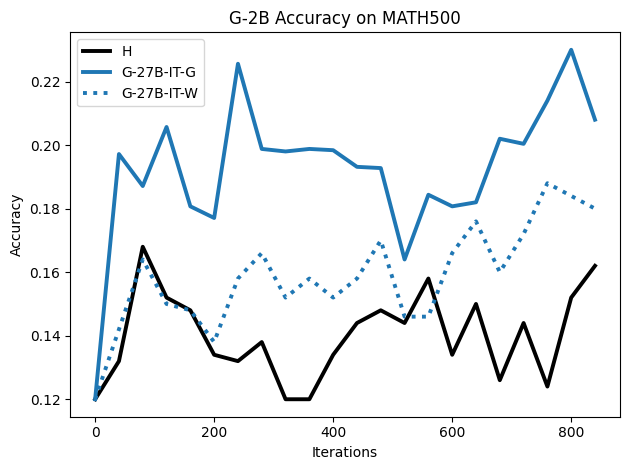
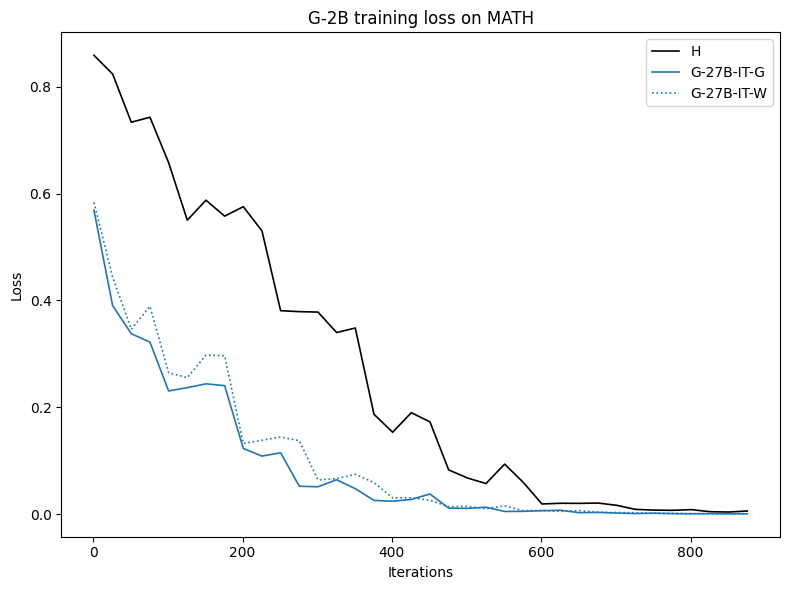
实验结果表明,使用合成CoT数据训练的模型在MATH、GSM8K、Countdown和MBPP等数据集上取得了显著的性能提升。例如,在某些任务上,使用合成数据训练的模型甚至优于使用人工标注数据训练的模型。此外,实验还表明,通过释义人工标注数据,使其分布更接近模型自身,可以进一步提高模型的性能。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如智能客服、自动编程、科学研究等。通过利用合成数据进行训练,可以降低对人工标注数据的依赖,提高模型的泛化能力和鲁棒性,从而加速人工智能在各个领域的应用。
📄 摘要(原文)
We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.