AgentMath: Empowering Mathematical Reasoning for Large Language Models via Tool-Augmented Agent
作者: Haipeng Luo, Huawen Feng, Qingfeng Sun, Can Xu, Kai Zheng, Yufei Wang, Tao Yang, Han Hu, Yansong Tang, Di Wang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-12-23 (更新: 2025-12-27)
备注: LLM, Mathematical Reasoning
💡 一句话要点
AgentMath:通过工具增强Agent提升大语言模型的数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大语言模型 工具增强 强化学习 代码解释器 Agent框架 数学问题求解
📋 核心要点
- 现有大语言模型在复杂数学运算中面临计算效率和准确性的挑战。
- AgentMath框架结合语言模型的推理能力和代码解释器的计算精度。
- AgentMath在数学竞赛基准测试中取得了最先进的性能,验证了其有效性。
📝 摘要(中文)
大型推理模型(LRMs)如o3和DeepSeek-R1在自然语言推理方面取得了显著进展,尤其是在长链式思维方面。然而,当解决需要复杂数学运算的问题时,它们在计算效率和准确性方面仍然存在不足。本文提出了AgentMath,一个agent框架,它将语言模型的推理能力与代码解释器的计算精度无缝集成,以高效地解决复杂的数学问题。我们的方法引入了三个关键创新:(1)一种自动方法,将自然语言链式思维转换为结构化的工具增强轨迹,生成高质量的监督微调(SFT)数据,以缓解数据稀缺问题;(2)一种新颖的agent强化学习(RL)范式,动态地将自然语言生成与实时代码执行交织在一起。这使得模型能够通过多轮交互反馈自主学习最佳的工具使用策略,同时培养代码改进和错误纠正方面的新兴能力;(3)一个高效的训练系统,结合了创新技术,包括请求级异步rollout调度、agent partial rollout和前缀感知加权负载平衡,实现了4-5倍的加速,并使在具有大量工具调用的超长序列场景中进行高效的RL训练成为可能。评估表明,AgentMath在具有挑战性的数学竞赛基准(包括AIME24、AIME25和HMMT25)上实现了最先进的性能。具体而言,AgentMath-30B-A3B分别达到了90.6%、86.4%和73.8%的准确率,取得了先进的性能。结果验证了我们方法的有效性,并为构建更复杂和可扩展的数学推理agent铺平了道路。
🔬 方法详解
问题定义:论文旨在解决大语言模型在复杂数学问题求解中存在的计算效率低和准确性不足的问题。现有方法在处理需要大量计算或涉及复杂公式推导的数学问题时,往往难以保证结果的正确性,且计算资源消耗较大。
核心思路:论文的核心思路是将大语言模型的推理能力与代码解释器的精确计算能力相结合。通过让模型学会利用代码解释器作为工具,执行数学运算,从而提高计算效率和准确性。这种方法类似于人类解决复杂数学问题时,会借助计算器或计算机进行辅助计算。
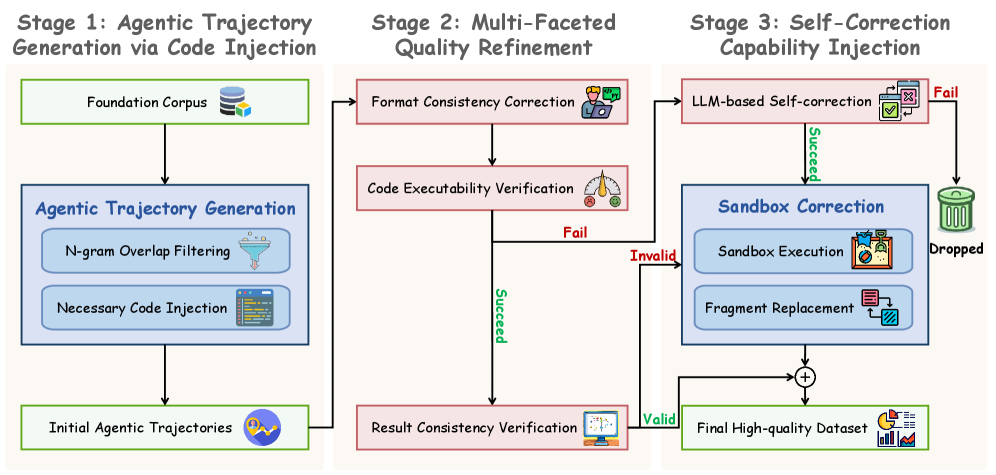
技术框架:AgentMath框架包含以下几个主要模块:1) 数据生成模块:自动将自然语言链式思维转换为结构化的工具增强轨迹,生成高质量的监督微调数据。2) Agent强化学习模块:动态地将自然语言生成与实时代码执行交织在一起,通过多轮交互反馈学习最佳的工具使用策略。3) 高效训练系统:采用请求级异步rollout调度、agent partial rollout和前缀感知加权负载平衡等技术,加速训练过程。整体流程是,首先使用数据生成模块生成训练数据,然后使用Agent强化学习模块训练模型,最后使用高效训练系统加速训练过程。
关键创新:论文最重要的技术创新点在于agent强化学习范式,它允许模型在推理过程中动态地调用代码解释器,并根据执行结果进行调整。这种交互式的学习方式使得模型能够自主学习最佳的工具使用策略,并具备代码改进和错误纠正的能力。与现有方法相比,AgentMath能够更好地利用外部工具,提高解决复杂数学问题的能力。
关键设计:在数据生成方面,设计了自动转换自然语言链式思维为结构化工具增强轨迹的方法。在强化学习方面,设计了奖励函数,鼓励模型使用代码解释器进行计算,并惩罚错误的结果。在训练系统方面,采用了请求级异步rollout调度、agent partial rollout和前缀感知加权负载平衡等技术,以提高训练效率。
🖼️ 关键图片

📊 实验亮点
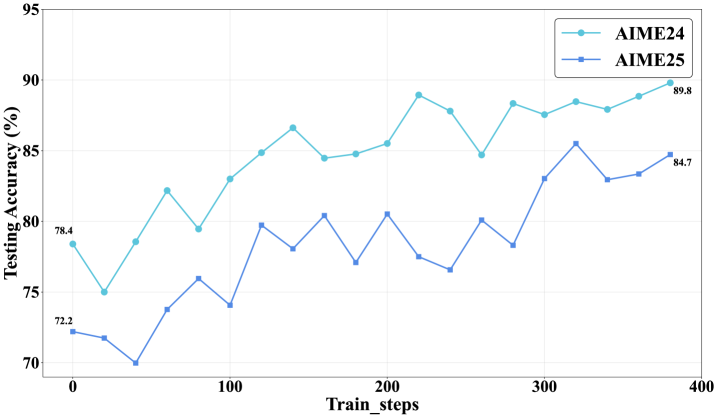
AgentMath在AIME24、AIME25和HMMT25等具有挑战性的数学竞赛基准测试中取得了最先进的性能。具体而言,AgentMath-30B-A3B分别达到了90.6%、86.4%和73.8%的准确率,显著优于现有的大语言模型。
🎯 应用场景
AgentMath具有广泛的应用前景,可应用于自动化数学问题求解、科学计算、金融建模等领域。该研究有助于提升AI在需要精确计算和复杂推理任务中的能力,并为开发更智能的数学助手和科学研究工具奠定基础。未来,该技术有望应用于教育领域,辅助学生学习数学。
📄 摘要(原文)
Large Reasoning Models (LRMs) like o3 and DeepSeek-R1 have achieved remarkable progress in natural language reasoning with long chain-of-thought. However, they remain computationally inefficient and struggle with accuracy when solving problems requiring complex mathematical operations. In this work, we present AgentMath, an agent framework that seamlessly integrates language models' reasoning capabilities with code interpreters' computational precision to efficiently tackle complex mathematical problems. Our approach introduces three key innovations: (1) An automated method that converts natural language chain-of-thought into structured tool-augmented trajectories, generating high-quality supervised fine-tuning (SFT) data to alleviate data scarcity; (2) A novel agentic reinforcement learning (RL) paradigm that dynamically interleaves natural language generation with real-time code execution. This enables models to autonomously learn optimal tool-use strategies through multi-round interactive feedback, while fostering emergent capabilities in code refinement and error correction; (3) An efficient training system incorporating innovative techniques, including request-level asynchronous rollout scheduling, agentic partial rollout, and prefix-aware weighted load balancing, achieving 4-5x speedup and making efficient RL training feasible on ultra-long sequences with scenarios with massive tool invocation. The evaluations show that AgentMath achieves state-of-the-art performance on challenging mathematical competition benchmarks including AIME24, AIME25, and HMMT25. Specifically, AgentMath-30B-A3B attains 90.6%, 86.4%, and 73.8% accuracy respectively, achieving advanced performance. The results validate the effectiveness of our approach and pave the way for building more sophisticated and scalable mathematical reasoning agents.