Leveraging High-Fidelity Digital Models and Reinforcement Learning for Mission Engineering: A Case Study of Aerial Firefighting Under Perfect Information
作者: İbrahim Oğuz Çetinkaya, Sajad Khodadadian, Taylan G. Topcu
分类: cs.CY, cs.AI, eess.SY, math.OC
发布日期: 2025-12-23 (更新: 2025-12-29)
💡 一句话要点
利用高保真数字模型和强化学习进行任务工程:以完美信息下的空中消防为例
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 任务工程 强化学习 数字孪生 智能任务协调 空中消防
📋 核心要点
- 传统系统工程难以应对复杂动态的任务环境,静态架构脆弱,需要严谨的分析方法。
- 论文提出一种智能任务协调方法,结合数字任务模型和强化学习,实现自适应的任务分配和重配置。
- 在空中消防案例中,该方法超越了基线性能,并显著降低了任务性能的波动性。
📝 摘要(中文)
本文提出了一种智能任务协调方法,该方法集成了数字任务模型与强化学习(RL),专门解决自适应任务分配和重配置的需求。具体而言,我们利用基于数字工程(DE)的基础设施,该基础设施由高保真数字任务模型和基于Agent的仿真组成;然后,我们将任务策略管理问题建模为马尔可夫决策过程(MDP),并采用通过近端策略优化(Proximal Policy Optimization)训练的RL Agent。通过利用仿真作为沙箱,我们将系统状态映射到动作,并根据已实现的任务结果改进策略。通过空中消防案例研究证明了基于RL的智能任务协调器的效用。我们的研究结果表明,基于RL的智能任务协调器不仅超越了基线性能,而且显著降低了任务性能的可变性。因此,这项研究可以作为概念验证,表明DE支持的任务仿真与先进的分析工具相结合,为改进任务工程实践提供了一种与任务无关的框架;从任务优先的角度来看,该框架可以扩展到未来更复杂的机队设计和选择问题。
🔬 方法详解
问题定义:论文旨在解决复杂任务环境中,如何进行自适应的任务分配和重配置问题。现有方法通常依赖于静态架构,难以应对环境的不确定性和动态变化,导致任务性能不稳定甚至失败。特别是在像空中消防这样的场景中,快速变化的环境条件对任务的成功至关重要。
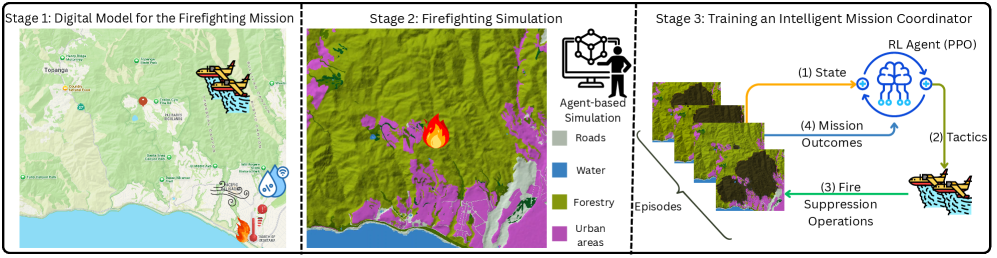
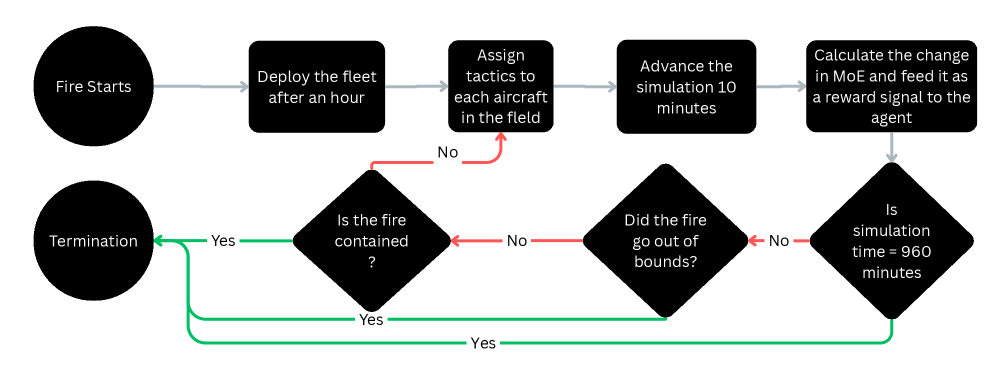
核心思路:论文的核心思路是将任务环境建模为马尔可夫决策过程(MDP),并利用强化学习(RL)训练智能体,使其能够根据当前状态选择最优的动作(任务分配策略)。通过高保真数字任务模型和Agent-based仿真,为RL智能体提供一个“沙箱”环境,在其中进行策略学习和优化。这种方法允许智能体在安全可控的环境中探索各种策略,并根据任务结果进行改进,从而提高任务的适应性和鲁棒性。
技术框架:整体框架包含三个主要组成部分:1) 高保真数字任务模型,用于模拟任务环境和Agent的行为;2) 基于Agent的仿真环境,用于生成训练数据和评估策略性能;3) 基于近端策略优化(PPO)的RL智能体,用于学习和优化任务分配策略。仿真环境将系统状态(例如,火势蔓延情况、飞机位置等)作为RL智能体的输入,RL智能体输出动作(例如,分配飞机到特定区域),然后仿真环境根据动作更新状态,并计算奖励信号,用于训练RL智能体。
关键创新:该论文的关键创新在于将数字工程(DE)和强化学习(RL)相结合,构建了一个智能任务协调框架。与传统的基于规则或优化的任务分配方法相比,该方法能够更好地适应动态变化的任务环境,并学习到更优的任务分配策略。此外,利用高保真数字模型和仿真环境,可以降低实际部署的风险和成本。
关键设计:论文使用近端策略优化(PPO)算法训练RL智能体。状态空间包括火势蔓延情况、飞机位置、剩余水量等信息。动作空间包括将飞机分配到不同的火灾区域。奖励函数的设计旨在鼓励智能体快速有效地扑灭火灾,并避免资源浪费。具体参数设置(如学习率、折扣因子、探索率等)需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于RL的智能任务协调器在空中消防案例中表现出色,不仅超越了基线性能,而且显著降低了任务性能的可变性。这表明该方法能够学习到更优的任务分配策略,并更好地适应动态变化的任务环境。具体性能提升数据未在摘要中明确给出,但强调了超越基线和降低可变性的结论。
🎯 应用场景
该研究成果可应用于各种复杂任务环境下的资源调度和任务分配问题,例如:应急救援、物流配送、智能交通、军事作战等。通过构建高保真数字模型和利用强化学习,可以提高任务的效率、鲁棒性和适应性,降低成本和风险。未来,该方法可以扩展到更复杂的机队设计和选择问题,从任务优先的角度优化系统配置。
📄 摘要(原文)
As systems engineering (SE) objectives evolve from design and operation of monolithic systems to complex System of Systems (SoS), the discipline of Mission Engineering (ME) has emerged which is increasingly being accepted as a new line of thinking for the SE community. Moreover, mission environments are uncertain, dynamic, and mission outcomes are a direct function of how the mission assets will interact with this environment. This proves static architectures brittle and calls for analytically rigorous approaches for ME. To that end, this paper proposes an intelligent mission coordination methodology that integrates digital mission models with Reinforcement Learning (RL), that specifically addresses the need for adaptive task allocation and reconfiguration. More specifically, we are leveraging a Digital Engineering (DE) based infrastructure that is composed of a high-fidelity digital mission model and agent-based simulation; and then we formulate the mission tactics management problem as a Markov Decision Process (MDP), and employ an RL agent trained via Proximal Policy Optimization. By leveraging the simulation as a sandbox, we map the system states to actions, refining the policy based on realized mission outcomes. The utility of the RL-based intelligent mission coordinator is demonstrated through an aerial firefighting case study. Our findings indicate that the RL-based intelligent mission coordinator not only surpasses baseline performance but also significantly reduces the variability in mission performance. Thus, this study serves as a proof of concept demonstrating that DE-enabled mission simulations combined with advanced analytical tools offer a mission-agnostic framework for improving ME practice; which can be extended to more complicated fleet design and selection problems in the future from a mission-first perspective.