Generative Digital Twins: Vision-Language Simulation Models for Executable Industrial Systems
作者: YuChe Hsu, AnJui Wang, TsaiChing Ni, YuanFu Yang
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-12-23 (更新: 2026-01-13)
备注: 10 pages, 9 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出视觉-语言模拟模型,从草图和文本生成可执行工业系统数字孪生。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数字孪生 视觉语言模型 工业仿真 代码生成 多模态学习
📋 核心要点
- 现有工业仿真系统缺乏从视觉和语言信息直接生成可执行代码的能力,限制了其易用性和智能化水平。
- 提出视觉-语言模拟模型(VLSM),利用草图和自然语言提示生成FlexScript代码,实现跨模态的工业仿真系统。
- 构建大规模数据集并提出新的评估指标,实验结果表明该模型在结构精度和执行鲁棒性方面表现出色。
📝 摘要(中文)
本文提出了一种视觉-语言模拟模型(VLSM),它统一了视觉和文本理解,能够从布局草图和自然语言提示中合成可执行的FlexScript代码,从而实现工业仿真系统的跨模态推理。为了支持这种新范式,本研究构建了首个用于生成数字孪生的大规模数据集,包含超过12万个提示-草图-代码三元组,从而实现文本描述、空间结构和仿真逻辑之间的多模态学习。同时,针对该任务,专门提出了三个新的评估指标:结构有效率(SVR)、参数匹配率(PMR)和执行成功率(ESR),以全面评估结构完整性、参数保真度和仿真器可执行性。通过对视觉编码器、连接器和代码预训练语言骨干网络的系统性消融研究,所提出的模型实现了近乎完美的结构精度和高执行鲁棒性。这项工作为将视觉推理和语言理解集成到可执行工业仿真系统中的生成数字孪生奠定了基础。
🔬 方法详解
问题定义:现有工业仿真系统主要依赖人工编写代码,过程繁琐且易出错。缺乏直接从视觉布局草图和自然语言描述生成可执行代码的能力,导致仿真系统的构建效率低下,难以适应快速变化的工业需求。现有方法难以有效融合视觉和语言信息,进行跨模态推理,从而生成准确且可执行的仿真代码。
核心思路:本文的核心思路是构建一个视觉-语言模拟模型(VLSM),该模型能够理解视觉布局草图和自然语言提示,并将它们融合在一起,生成可执行的FlexScript代码。通过多模态学习,模型能够学习到视觉结构、文本描述和仿真逻辑之间的对应关系,从而实现从草图和文本到代码的自动生成。
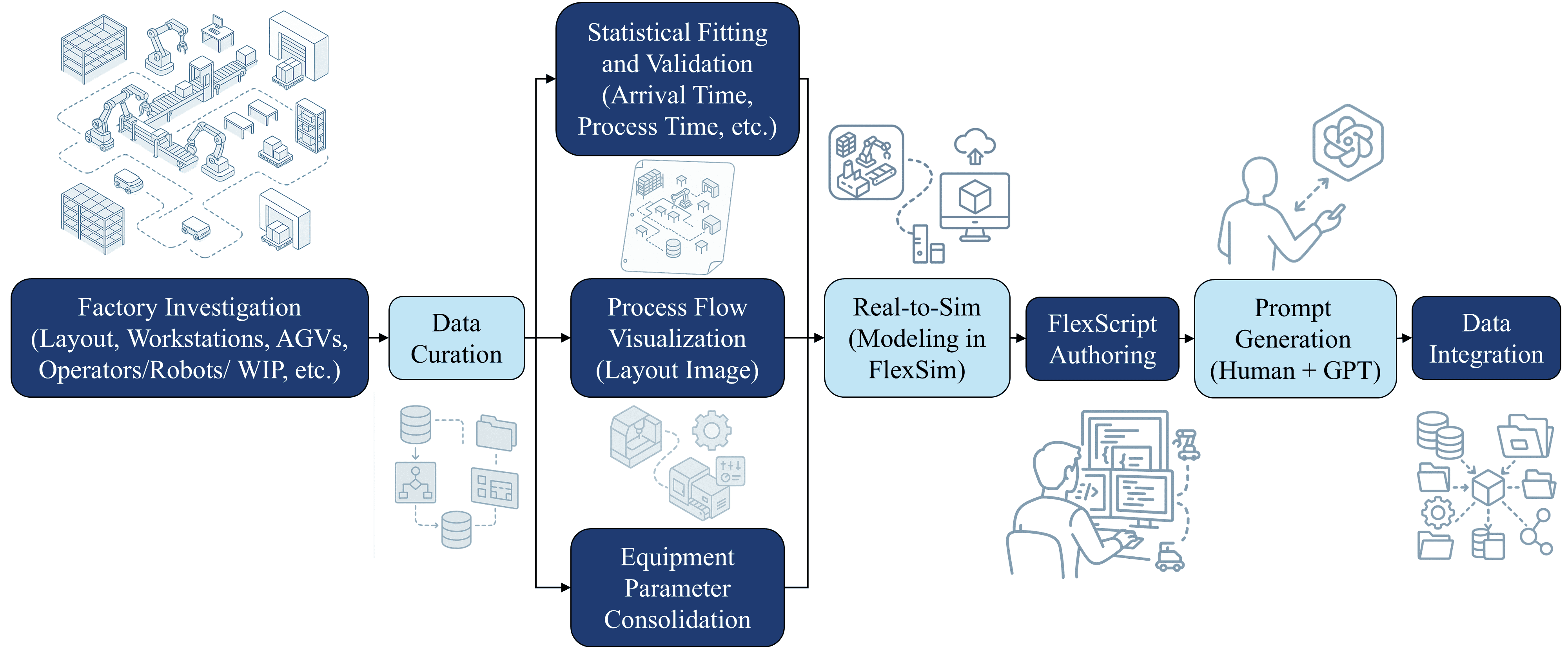
技术框架:VLSM的整体架构包含以下主要模块:1) 视觉编码器:用于提取布局草图的视觉特征。2) 文本编码器:用于提取自然语言提示的文本特征。3) 连接器:用于融合视觉和文本特征,实现跨模态信息交互。4) 代码生成器:基于融合后的特征生成FlexScript代码。整个流程是:输入草图和文本 -> 视觉/文本编码器提取特征 -> 连接器融合特征 -> 代码生成器生成代码。
关键创新:最重要的技术创新点在于提出了一个统一的视觉-语言框架,能够将视觉和语言信息融合在一起,生成可执行的仿真代码。与现有方法相比,VLSM能够直接从草图和文本生成代码,无需人工干预,大大提高了仿真系统的构建效率。此外,本文还构建了大规模数据集,并提出了新的评估指标,为该领域的研究提供了基础。
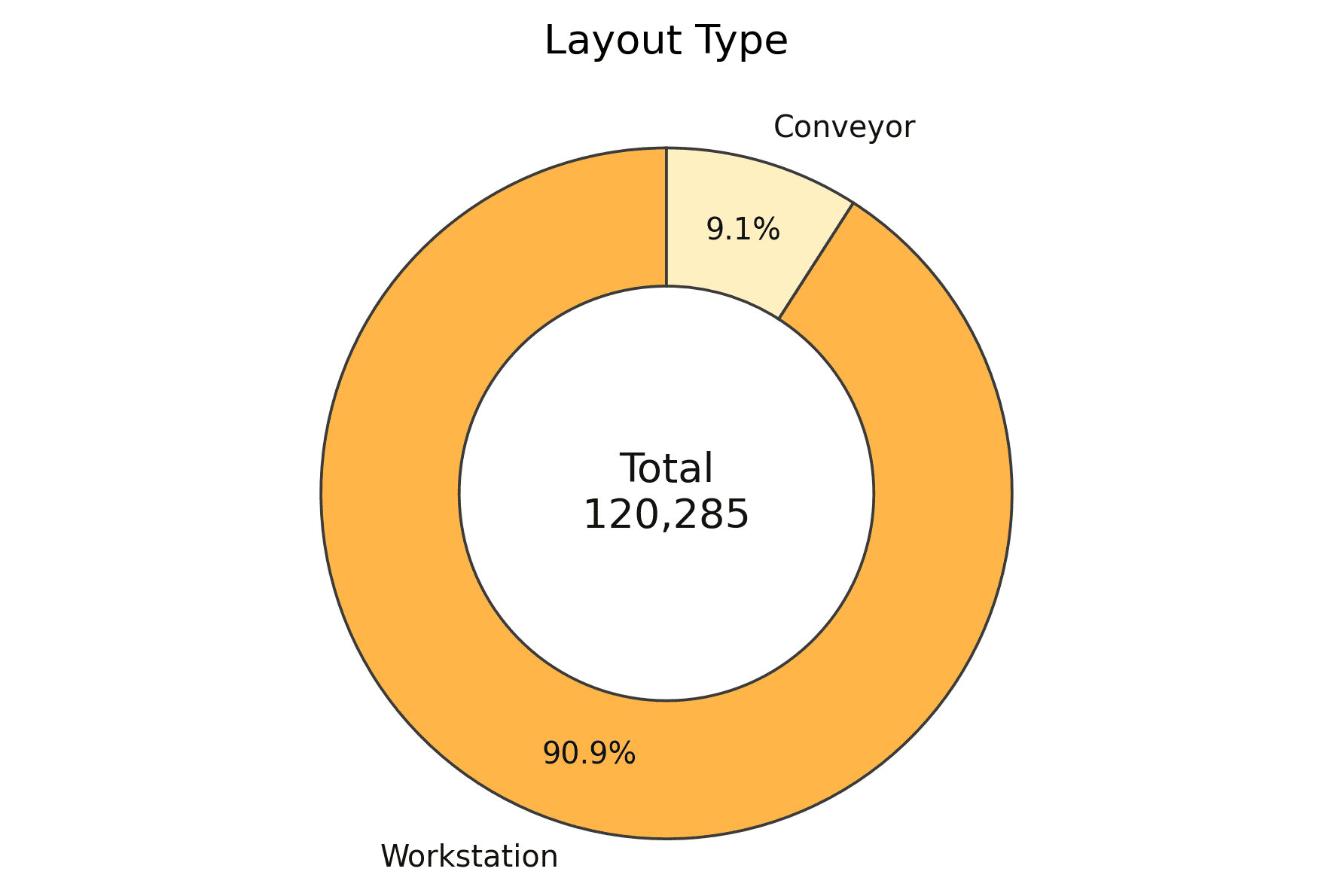
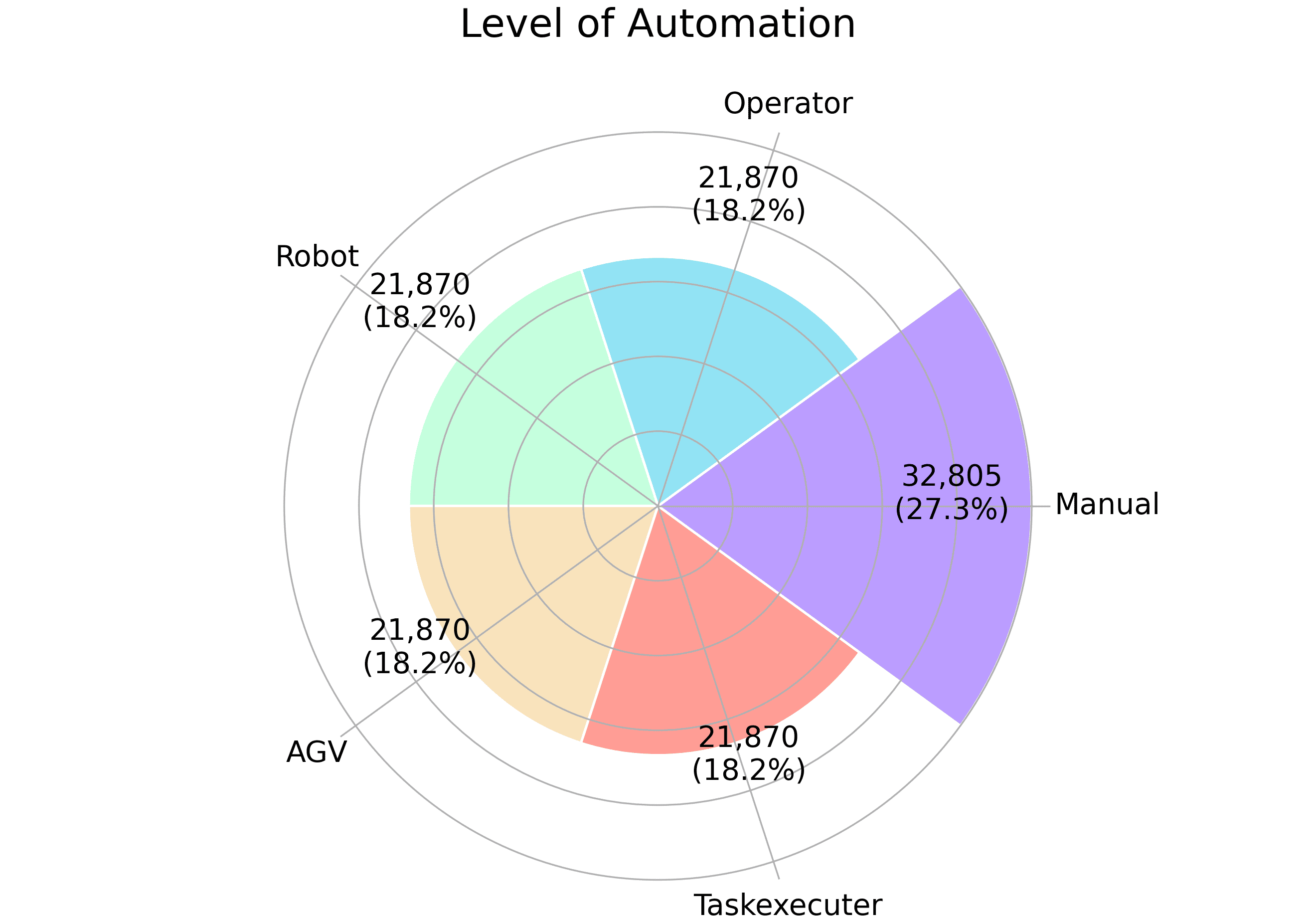
关键设计:视觉编码器可以使用预训练的卷积神经网络(CNN),如ResNet或VGG。文本编码器可以使用预训练的Transformer模型,如BERT或GPT。连接器可以使用注意力机制或交叉注意力机制,实现视觉和文本特征的有效融合。代码生成器可以使用Transformer解码器,逐步生成FlexScript代码。损失函数可以包括代码生成损失、结构损失和参数损失等。数据集包含超过12万个提示-草图-代码三元组。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的模型在结构有效率(SVR)方面接近完美,在执行成功率(ESR)方面也表现出很高的鲁棒性。通过消融实验,验证了各个模块的有效性,并找到了最佳的模型配置。与现有方法相比,该模型在代码生成质量和执行成功率方面均有显著提升。
🎯 应用场景
该研究成果可应用于智能制造、物流优化、仓储管理等领域。通过快速生成数字孪生模型,可以加速工业系统的设计、验证和优化过程,降低成本,提高效率。未来,该技术有望实现更高级别的自动化和智能化,例如自动生成仿真场景、自动优化控制策略等。
📄 摘要(原文)
We propose a Vision-Language Simulation Model (VLSM) that unifies visual and textual understanding to synthesize executable FlexScript from layout sketches and natural-language prompts, enabling cross-modal reasoning for industrial simulation systems. To support this new paradigm, the study constructs the first large-scale dataset for generative digital twins, comprising over 120,000 prompt-sketch-code triplets that enable multimodal learning between textual descriptions, spatial structures, and simulation logic. In parallel, three novel evaluation metrics, Structural Validity Rate (SVR), Parameter Match Rate (PMR), and Execution Success Rate (ESR), are proposed specifically for this task to comprehensively evaluate structural integrity, parameter fidelity, and simulator executability. Through systematic ablation across vision encoders, connectors, and code-pretrained language backbones, the proposed models achieve near-perfect structural accuracy and high execution robustness. This work establishes a foundation for generative digital twins that integrate visual reasoning and language understanding into executable industrial simulation systems. Project page: https://danielhsu2014.github.io/GDT-VLSM-project/