GamiBench: Evaluating Spatial Reasoning and 2D-to-3D Planning Capabilities of MLLMs with Origami Folding Tasks
作者: Ryan Spencer, Roey Yaari, Ritvik Vemavarapu, Joyce Yang, Steven Ngo, Utkarsh Sharma
分类: cs.AI
发布日期: 2025-12-22
🔗 代码/项目: GITHUB
💡 一句话要点
GamiBench:通过折纸任务评估多模态大语言模型空间推理和2D到3D规划能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 空间推理 折纸任务 2D到3D规划 视觉问答 基准测试 视角一致性 物理可行性
📋 核心要点
- 现有基准测试在评估多模态大语言模型(MLLM)的空间推理能力时,缺乏对顺序性和视角依赖性的考虑。
- GamiBench通过折纸任务,从跨视图一致性、物理可行性和中间步骤解释等方面,全面评估MLLM的空间推理过程。
- 实验表明,即使是GPT-5和Gemini-2.5-Pro等领先模型在单步空间理解方面也存在困难,突显了该基准的价值。
📝 摘要(中文)
多模态大语言模型(MLLM)在感知和指令跟随方面表现出色,但在空间推理方面仍然存在困难,即在多个视图和时间推移中对物体进行心理追踪和操作的能力。空间推理是人类智能的关键组成部分,但现有的大多数基准测试侧重于静态图像或最终输出,未能考虑到这种技能的顺序性和视角依赖性。为了弥补这一差距,我们引入了GamiBench,这是一个旨在通过折纸启发式折叠任务评估MLLM中的空间推理和2D到3D规划的基准。GamiBench包括186个常规和186个不可能的2D折痕图案,以及它们对应的3D折叠形状,这些形状来自六个不同的视角,跨越三个视觉问答(VQA)任务:预测3D折叠配置、区分有效视角和检测不可能的图案。与之前仅评估最终预测的基准不同,GamiBench全面评估整个推理过程——测量跨视图一致性、通过不可能折叠检测的物理可行性以及中间折叠步骤的解释。它进一步引入了新的诊断指标——视角一致性(VC)和不可能折叠选择率(IFSR)——以衡量模型处理不同复杂程度的折叠的能力。我们的实验表明,即使是GPT-5和Gemini-2.5-Pro等领先模型在单步空间理解方面也存在困难。这些贡献为评估MLLM中的几何理解和空间推理建立了一个标准化的框架。数据集和代码:https://github.com/stvngo/GamiBench。
🔬 方法详解
问题定义:现有方法在评估多模态大语言模型(MLLM)的空间推理能力时,主要集中于静态图像或最终输出的评估,忽略了空间推理的顺序性和视角依赖性。这导致无法全面评估模型在复杂空间任务中的推理能力,例如理解中间步骤和判断物理可行性。
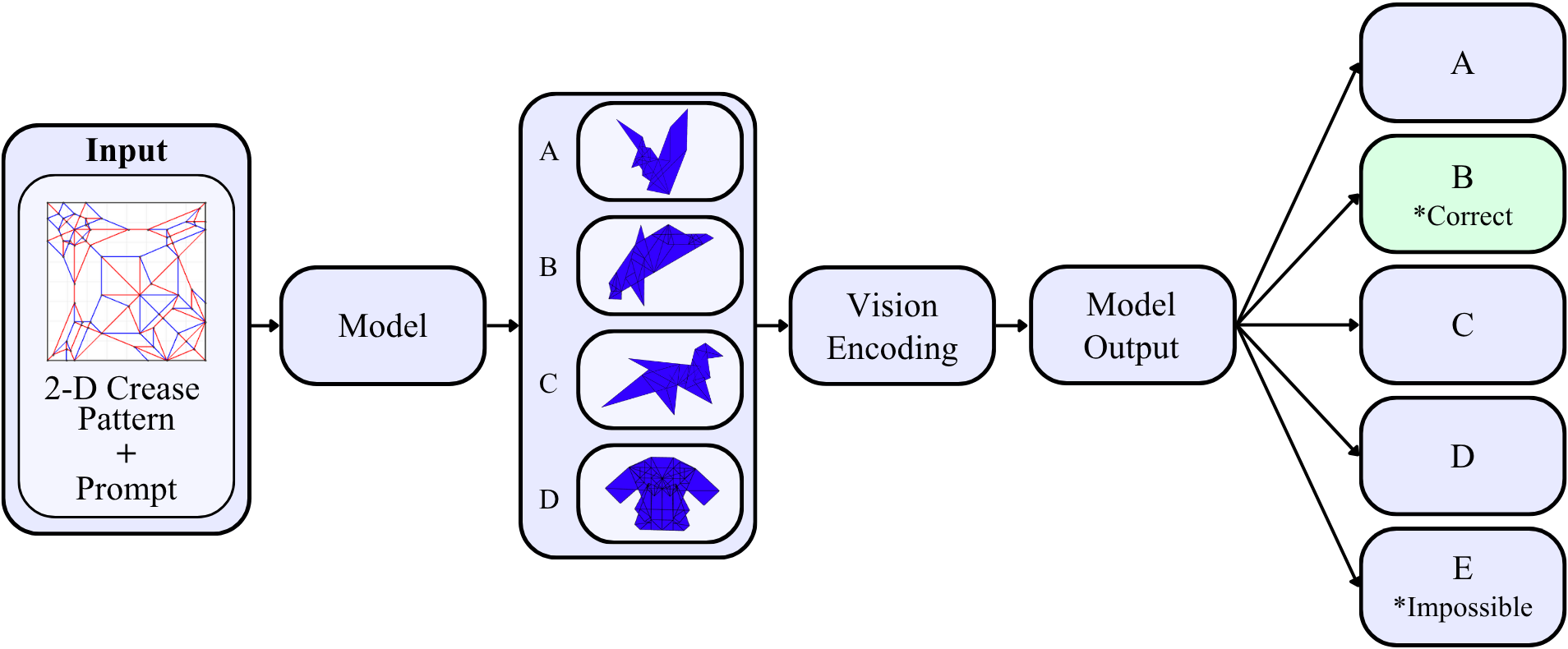
核心思路:GamiBench的核心思路是利用折纸任务来模拟真实世界中的空间推理过程。折纸任务天然具有顺序性和视角依赖性,需要模型在多个视图和时间步骤中跟踪和操作对象。通过设计不同的视觉问答(VQA)任务,例如预测3D折叠配置、区分有效视角和检测不可能的图案,可以全面评估模型的空间推理能力。
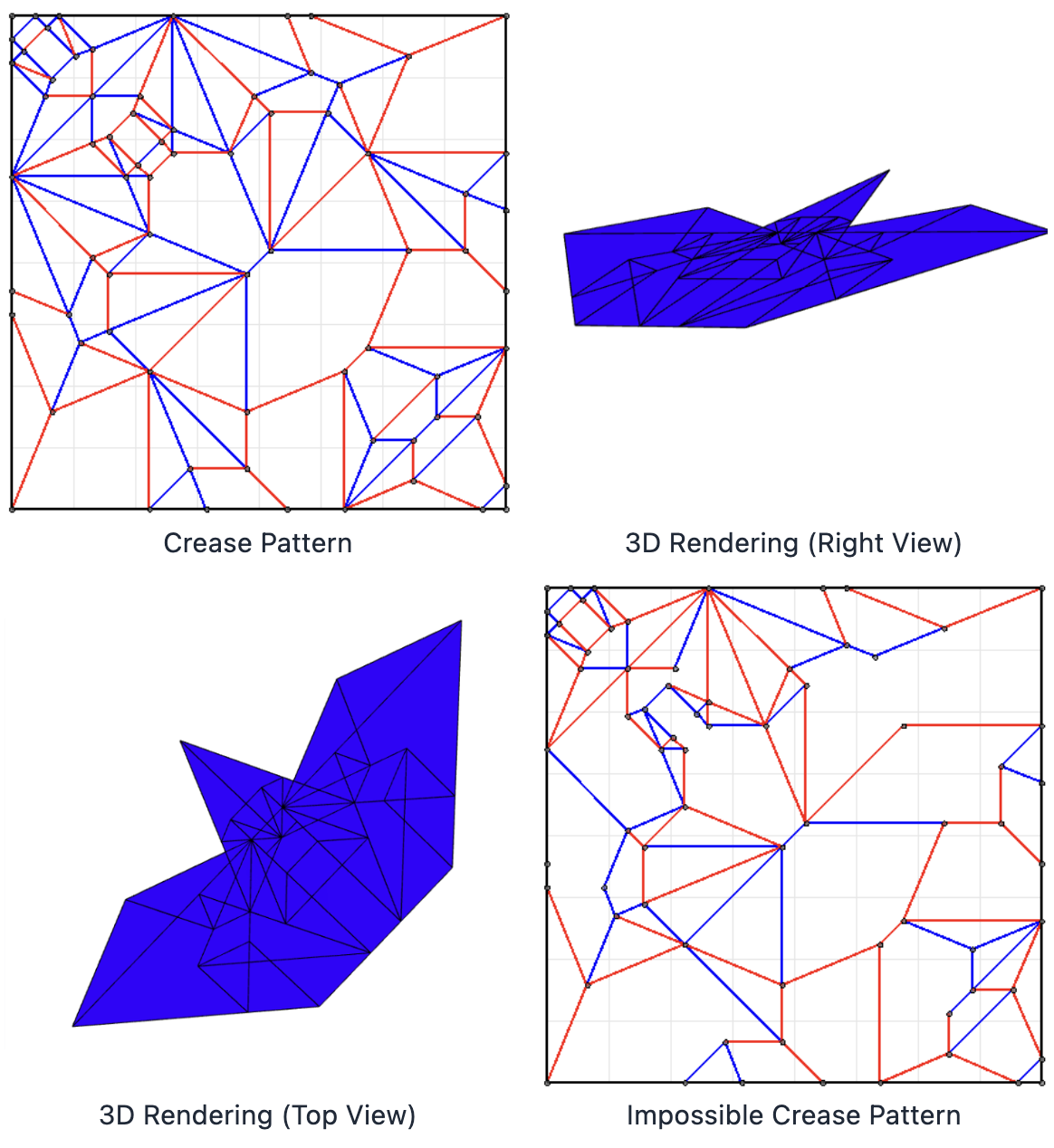
技术框架:GamiBench包含以下主要组成部分:1) 折纸数据集:包含186个常规和186个不可能的2D折痕图案,以及它们对应的3D折叠形状,这些形状来自六个不同的视角。2) 视觉问答(VQA)任务:包括预测3D折叠配置、区分有效视角和检测不可能的图案。3) 评估指标:包括视角一致性(VC)和不可能折叠选择率(IFSR),用于衡量模型处理不同复杂程度的折叠的能力。整体流程是,给定一个2D折痕图案和相应的视角,模型需要回答与3D折叠形状相关的问题。
关键创新:GamiBench的关键创新在于:1) 引入了折纸任务作为评估MLLM空间推理能力的基准,弥补了现有基准的不足。2) 设计了新的诊断指标,例如视角一致性(VC)和不可能折叠选择率(IFSR),用于更细粒度地评估模型的空间推理能力。3) 提供了一个包含常规和不可能折叠图案的数据集,用于评估模型的物理可行性判断能力。
关键设计:GamiBench的关键设计包括:1) 数据集的构建:通过算法生成折纸图案和对应的3D折叠形状,并从六个不同的视角渲染图像。2) VQA任务的设计:设计了三种不同的VQA任务,分别评估模型在预测3D折叠配置、区分有效视角和检测不可能的图案方面的能力。3) 评估指标的设计:视角一致性(VC)衡量模型在不同视角下预测结果的一致性,不可能折叠选择率(IFSR)衡量模型识别不可能折叠图案的能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是GPT-5和Gemini-2.5-Pro等领先模型在GamiBench基准上表现不佳,突显了现有MLLM在空间推理方面的局限性。具体而言,这些模型在单步空间理解、视角一致性和物理可行性判断方面都存在困难。GamiBench提供了一个标准化的框架,可以用于评估和改进MLLM的空间推理能力。
🎯 应用场景
GamiBench的研究成果可以应用于机器人操作、自动驾驶、增强现实等领域。通过提高MLLM的空间推理能力,可以使机器人更好地理解和操作周围环境,提高自动驾驶系统的安全性和可靠性,并为增强现实应用提供更逼真的交互体验。未来,该研究可以扩展到更复杂的空间任务,例如三维重建和场景理解。
📄 摘要(原文)
Multimodal large language models (MLLMs) are proficient in perception and instruction-following, but they still struggle with spatial reasoning: the ability to mentally track and manipulate objects across multiple views and over time. Spatial reasoning is a key component of human intelligence, but most existing benchmarks focus on static images or final outputs, failing to account for the sequential and viewpoint-dependent nature of this skill. To close this gap, we introduce GamiBench, a benchmark designed to evaluate spatial reasoning and 2D-to-3D planning in MLLMs through origami-inspired folding tasks. GamiBench includes 186 regular and 186 impossible 2D crease patterns paired with their corresponding 3D folded shapes, produced from six distinct viewpoints across three visual question-answering (VQA) tasks: predicting 3D fold configurations, distinguishing valid viewpoints, and detecting impossible patterns. Unlike previous benchmarks that assess only final predictions, GamiBench holistically evaluates the entire reasoning process--measuring cross-view consistency, physical feasibility through impossible-fold detection, and interpretation of intermediate folding steps. It further introduces new diagnostic metrics--viewpoint consistency (VC) and impossible fold selection rate (IFSR)--to measure how well models handle folds of varying complexity. Our experiments show that even leading models such as GPT-5 and Gemini-2.5-Pro struggle on single-step spatial understanding. These contributions establish a standardized framework for evaluating geometric understanding and spatial reasoning in MLLMs. Dataset and code: https://github.com/stvngo/GamiBench.