PromptScreen: Efficient Jailbreak Mitigation Using Semantic Linear Classification in a Multi-Staged Pipeline
作者: Akshaj Prashanth Rao, Advait Singh, Saumya Kumaar Saksena, Dhruv Kumar
分类: cs.CR, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-22 (更新: 2026-01-09)
备注: Under Review
💡 一句话要点
PromptScreen:一种多阶段流水线中基于语义线性分类的高效越狱攻击缓解方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示注入防御 越狱攻击缓解 大型语言模型安全 语义线性分类 多阶段流水线
📋 核心要点
- 大型语言模型面临提示注入和越狱攻击的安全威胁,现有防御方法在精度和效率上存在局限性。
- PromptScreen通过多阶段流水线,利用轻量级的语义过滤器和互补检测机制,实现高效的攻击缓解。
- 实验结果表明,PromptScreen在准确率和延迟方面均优于现有方法,验证了其在保护LLM应用方面的有效性。
📝 摘要(中文)
本文提出PromptScreen,一种高效且经过系统评估的防御架构,旨在缓解基于大型语言模型(LLM)系统的提示注入和越狱攻击带来的安全挑战。其核心组件是一个基于文本归一化、TF-IDF表示和线性SVM分类器的语义过滤器。尽管结构简单,该模块在保留数据上实现了93.4%的准确率和96.5%的特异性,显著降低了攻击吞吐量,同时计算开销可忽略不计。在此高效基础上,完整的流水线集成了在连续阶段运行的互补检测和缓解机制,以最小的延迟提供强大的鲁棒性。对比实验表明,基于SVM的配置将整体准确率从35.1%提高到93.4%,同时将平均完成时间从大约450秒减少到47秒,比ShieldGemma的延迟低10倍以上。这些结果表明,所提出的设计同时提高了防御精度和效率,解决了当前基于模型的审核器的核心局限性。在包含超过30,000个标记提示(包括良性、越狱和应用层注入)的精选语料库上的评估证实,分阶段、资源高效的防御可以可靠地保护现代LLM驱动的应用程序。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的提示注入和越狱攻击问题。现有的基于模型的审核器通常计算开销大,延迟高,并且在防御精度方面存在不足,难以有效应对各种攻击场景。
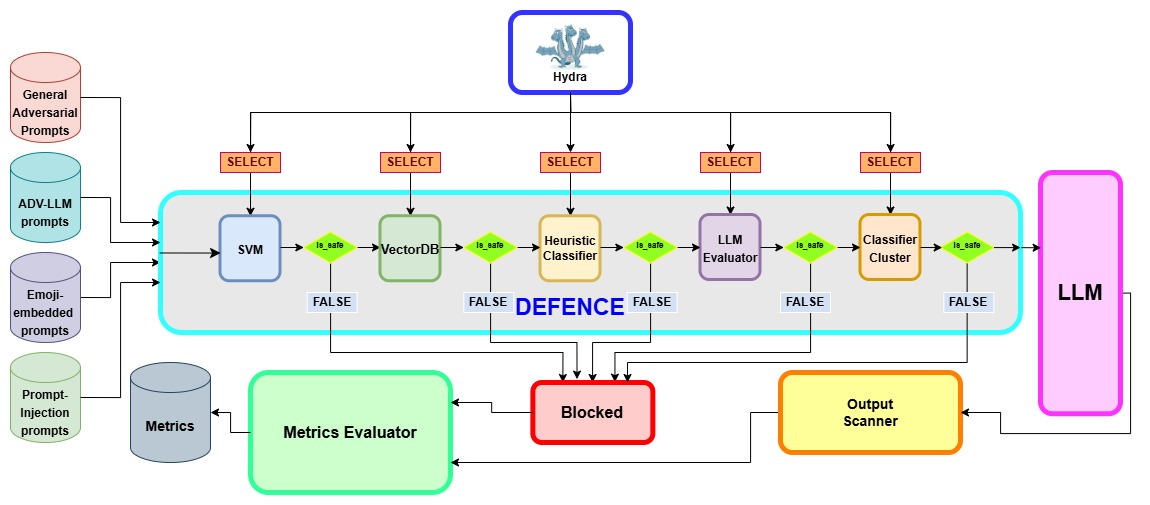
核心思路:PromptScreen的核心思路是构建一个轻量级、多阶段的防御流水线,利用资源高效的语义过滤器快速识别和阻止恶意提示,同时集成互补的检测和缓解机制,以提高整体防御的鲁棒性。通过分阶段处理,可以在早期阶段快速过滤掉大部分攻击,从而降低后续阶段的计算负担。
技术框架:PromptScreen的整体架构是一个多阶段流水线,主要包含以下模块: 1. 文本归一化:对输入提示进行预处理,例如去除特殊字符、转换为小写等。 2. TF-IDF表示:将文本转换为TF-IDF向量表示,捕捉文本的语义信息。 3. 线性SVM分类器:使用线性SVM分类器对提示进行分类,判断其是否为恶意提示。 4. 互补检测和缓解机制:在后续阶段集成其他检测和缓解机制,例如基于规则的过滤器或更复杂的模型,以进一步提高防御能力。
关键创新:PromptScreen的关键创新在于其高效的语义过滤器,该过滤器基于文本归一化、TF-IDF表示和线性SVM分类器,能够在保证高准确率和特异性的前提下,实现极低的计算开销。与传统的基于大型模型的审核器相比,PromptScreen在效率方面具有显著优势。此外,多阶段流水线的设计也提高了整体防御的鲁棒性。
关键设计: * TF-IDF参数:论文可能需要调整TF-IDF的参数,例如最大特征数、最小文档频率等,以优化模型的性能。 * SVM参数:线性SVM分类器的正则化参数C需要进行调整,以平衡模型的偏差和方差。 * 流水线配置:不同阶段的检测和缓解机制需要根据具体的应用场景进行选择和配置,以达到最佳的防御效果。 * 训练数据:需要构建包含良性、越狱和应用层注入等多种类型的提示数据集,用于训练和评估模型。
🖼️ 关键图片
📊 实验亮点
PromptScreen在包含超过30,000个标记提示的语料库上进行了评估,结果表明,基于SVM的配置将整体准确率从35.1%提高到93.4%,同时将平均完成时间从大约450秒减少到47秒,比ShieldGemma的延迟低10倍以上。这些结果表明,PromptScreen在防御精度和效率方面均优于现有方法。
🎯 应用场景
PromptScreen可应用于各种基于大型语言模型的应用场景,例如聊天机器人、智能助手、代码生成器等。通过有效缓解提示注入和越狱攻击,PromptScreen可以提高LLM应用的安全性、可靠性和用户体验,降低恶意利用的风险,并促进LLM技术的更广泛应用。
📄 摘要(原文)
Prompt injection and jailbreaking attacks pose persistent security challenges to large language model (LLM)-based systems. We present PromptScreen, an efficient and systematically evaluated defense architecture that mitigates these threats through a lightweight, multi-stage pipeline. Its core component is a semantic filter based on text normalization, TF-IDF representations, and a Linear SVM classifier. Despite its simplicity, this module achieves 93.4% accuracy and 96.5% specificity on held-out data, substantially reducing attack throughput while incurring negligible computational overhead. Building on this efficient foundation, the full pipeline integrates complementary detection and mitigation mechanisms that operate at successive stages, providing strong robustness with minimal latency. In comparative experiments, our SVM-based configuration improves overall accuracy from 35.1% to 93.4% while reducing average time-to-completion from approximately 450 s to 47 s, yielding over 10 times lower latency than ShieldGemma. These results demonstrate that the proposed design simultaneously advances defensive precision and efficiency, addressing a core limitation of current model-based moderators. Evaluation across a curated corpus of over 30,000 labeled prompts, including benign, jailbreak, and application-layer injections, confirms that staged, resource-efficient defenses can robustly secure modern LLM-driven applications.