Multi-Agent LLM Committees for Autonomous Software Beta Testing
作者: Sumanth Bharadwaj Hachalli Karanam, Dhiwahar Adhithya Kennady
分类: cs.SE, cs.AI, cs.MA
发布日期: 2025-12-21
💡 一句话要点
提出多代理LLM委员会框架以解决软件测试效率低下问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多代理系统 大型语言模型 软件测试 视觉增强 持续集成 自动化测试
📋 核心要点
- 现有的手动软件测试方法成本高且耗时,单代理LLM方法存在幻觉和不一致行为的问题。
- 本文提出的多代理委员会框架通过三轮投票协议使多样化的视觉增强LLM协作,提升测试效率和准确性。
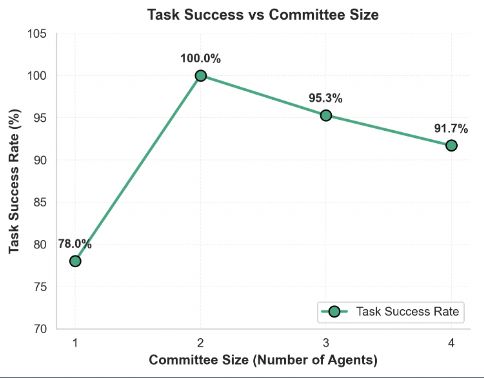
- 实验结果显示,多代理委员会在任务成功率上达89.5%,相比单代理基线提升了13.7至22.0个百分点。
📝 摘要(中文)
手动软件测试成本高且耗时,而单代理大型语言模型(LLM)方法存在幻觉和行为不一致的问题。本文提出了一种多代理委员会框架,利用多样化的视觉增强LLM通过三轮投票协议协作达成测试行动的共识。该框架结合了模型多样性、基于角色的行为变化和视觉用户界面理解,系统性地探索Web应用。在84次实验中,使用9种测试角色和4种场景,多代理委员会的整体任务成功率达89.5%。与单代理基线相比,2至4个代理的配置成功率提高至91.7%至100%。
🔬 方法详解
问题定义:本文旨在解决手动软件测试的高成本和耗时问题,同时克服单代理LLM在测试中的幻觉和不一致性。现有方法在复杂的Web应用测试中表现不佳,无法有效识别用户界面元素。
核心思路:提出多代理委员会框架,通过多样化的视觉增强LLM协作,利用三轮投票机制达成共识,系统性地探索和测试Web应用。这样的设计可以有效减少单一模型的局限性,提升测试的准确性和效率。
技术框架:该框架包括多个视觉增强LLM代理,这些代理通过三轮投票协议进行协作。每个代理根据不同的角色和行为模式进行测试,最终通过投票达成一致的测试行动。
关键创新:最重要的创新在于引入多代理协作机制,结合模型多样性和角色驱动的行为变化,显著提升了测试的成功率和效率。这与传统的单代理方法形成鲜明对比。
关键设计:在实验中,代理的数量设置为2至4个,成功率达到91.7%至100%。系统在每个动作的成功率上达93.1%,并且在用户界面元素识别方面表现优异,导航和报告的成功率为100%。
🖼️ 关键图片


📊 实验亮点
实验结果显示,多代理委员会在84次实验中整体任务成功率达89.5%,相比单代理基线的78.0%提升了13.7至22.0个百分点。特别是在WebShop和OWASP Juice Shop的测试中,成功率分别为74.7%和82.0%,显著优于现有的GPT-3基线。
🎯 应用场景
该研究的潜在应用领域包括软件开发中的持续集成和持续交付(CI/CD)流程,能够有效提高软件测试的自动化水平和准确性。未来,该框架可扩展至更多类型的应用程序测试,推动软件质量保障的智能化进程。
📄 摘要(原文)
Manual software beta testing is costly and time-consuming, while single-agent large language model (LLM) approaches suffer from hallucinations and inconsistent behavior. We propose a multi-agent committee framework in which diverse vision-enabled LLMs collaborate through a three-round voting protocol to reach consensus on testing actions. The framework combines model diversity, persona-driven behavioral variation, and visual user interface understanding to systematically explore web applications. Across 84 experimental runs with 9 testing personas and 4 scenarios, multi-agent committees achieve an 89.5 percent overall task success rate. Configurations with 2 to 4 agents reach 91.7 to 100 percent success, compared to 78.0 percent for single-agent baselines, yielding improvements of 13.7 to 22.0 percentage points. At the action level, the system attains a 93.1 percent success rate with a median per-action latency of 0.71 seconds, enabling real-time and continuous integration testing. Vision-enabled agents successfully identify user interface elements, with navigation and reporting achieving 100 percent success and form filling achieving 99.2 percent success. We evaluate the framework on WebShop and OWASP benchmarks, achieving 74.7 percent success on WebShop compared to a 50.1 percent published GPT-3 baseline, and 82.0 percent success on OWASP Juice Shop security testing with coverage of 8 of the 10 OWASP Top 10 vulnerability categories. Across 20 injected regressions, the committee achieves an F1 score of 0.91 for bug detection, compared to 0.78 for single-agent baselines. The open-source implementation enables reproducible research and practical deployment of LLM-based software testing in CI/CD pipelines.