Beyond the Prompt: An Empirical Study of Cursor Rules
作者: Shaokang Jiang, Daye Nam
分类: cs.SE, cs.AI, cs.HC
发布日期: 2025-12-21 (更新: 2026-01-27)
备注: To appear at MSR 2026
💡 一句话要点
大规模实证研究揭示了光标规则在软件工程中项目上下文编码的关键作用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件工程 项目上下文 光标规则 实证研究
📋 核心要点
- 大型语言模型在软件工程中的应用受限于缺乏项目特定上下文,导致生成质量不佳的代码。
- 该研究通过分析开源项目中光标规则的内容,揭示了开发者认为重要的项目上下文信息。
- 研究构建了项目上下文的分类体系,并分析了不同项目类型和编程语言之间的差异。
📝 摘要(中文)
大型语言模型(LLM)的能力显著,但其有效性不仅取决于显式提示,还依赖于更广泛的上下文。在软件工程中,项目目标、架构和协作规范对响应质量至关重要。为了支持这一点,许多AI编码助手引入了持久性的、机器可读的指令,用于编码项目的独特约束。尽管这种做法日益普及,但这些指令的内容仍未得到研究。本文通过对包含光标规则的401个开源仓库进行大规模实证研究,旨在描述这种新兴的开发者提供的上下文形式。通过定性分析,我们开发了一个全面的项目上下文分类法,开发者认为这些上下文至关重要,并将其组织为五个高级主题:约定、指南、项目信息、LLM指令和示例。我们的研究还探讨了这种上下文在不同项目类型和编程语言中的变化,为下一代上下文感知的AI开发者工具提供了启示。
🔬 方法详解
问题定义:现有的大型语言模型在软件工程领域的应用,往往忽略了项目自身的上下文信息,例如编码规范、项目架构、设计文档等。这导致模型生成的代码难以融入现有项目,甚至可能引入错误或不一致性。因此,如何有效地将项目上下文融入到LLM的输入中,提高代码生成质量,是一个亟待解决的问题。现有方法主要依赖于简单的prompt工程,缺乏对项目上下文的系统性理解和利用。
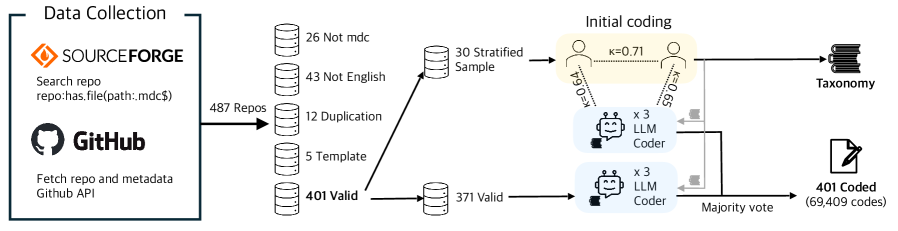
核心思路:该论文的核心思路是通过大规模实证研究,分析开源项目中开发者使用的“光标规则”(cursor rules),提取并归纳开发者认为重要的项目上下文信息。光标规则是一种新兴的、由开发者提供的、机器可读的指令,用于指导AI编码助手。通过分析这些规则,可以了解开发者如何显式地编码项目上下文,从而为设计更好的上下文感知AI工具提供依据。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集:从GitHub等开源代码托管平台收集包含光标规则的开源项目;2) 数据清洗:对收集到的光标规则进行清洗和预处理,去除噪声和冗余信息;3) 定性分析:对清洗后的光标规则进行定性分析,识别并归纳开发者使用的项目上下文信息;4) 分类体系构建:基于定性分析的结果,构建一个全面的项目上下文分类体系;5) 统计分析:对不同项目类型和编程语言的项目上下文信息进行统计分析,揭示其差异性。
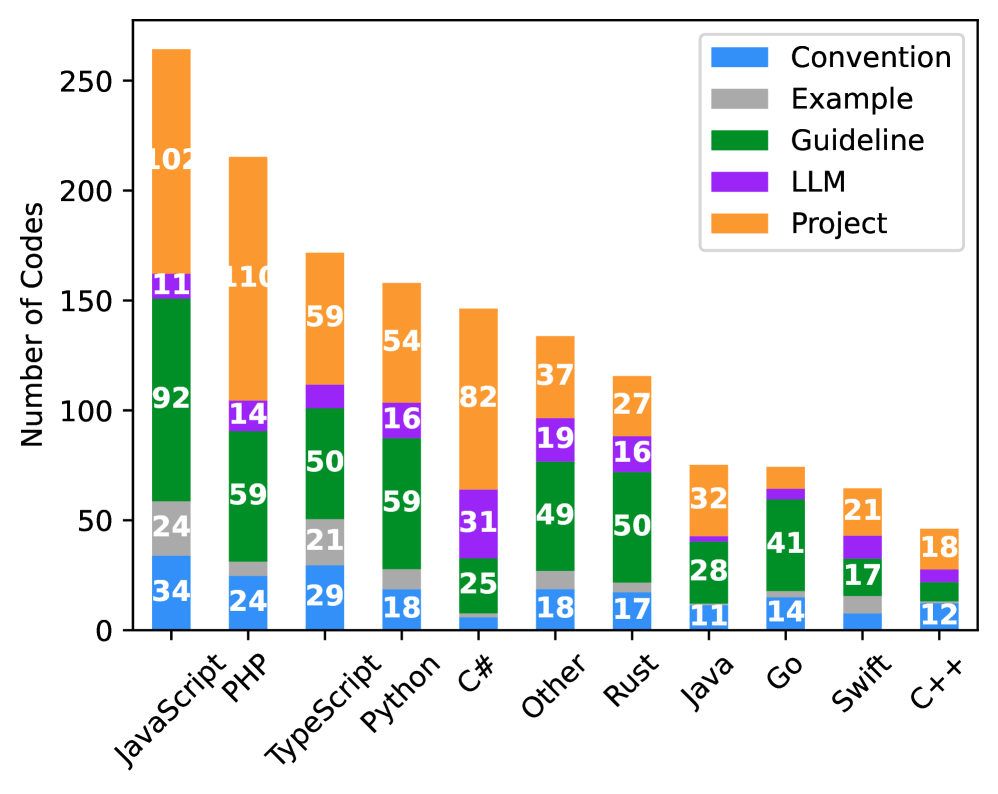
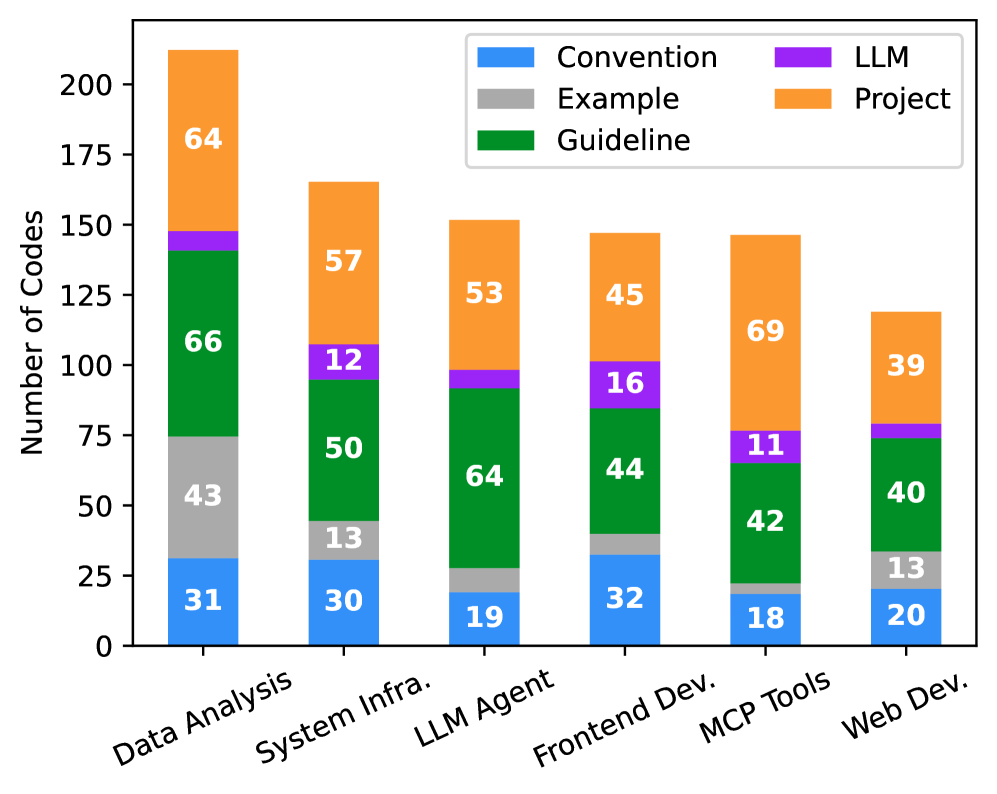
关键创新:该论文的关键创新在于:1) 首次对光标规则这种新兴的开发者提供的上下文形式进行了大规模实证研究;2) 构建了一个全面的项目上下文分类体系,包括约定、指南、项目信息、LLM指令和示例等五个高级主题;3) 揭示了不同项目类型和编程语言的项目上下文信息的差异性。
关键设计:该研究的关键设计在于其定性分析方法。研究者仔细阅读和分析了401个开源仓库中的光标规则,从中提取出开发者认为重要的项目上下文信息。然后,研究者使用开放式编码(open coding)和轴向编码(axial coding)等方法,对这些信息进行归纳和分类,最终构建了一个全面的项目上下文分类体系。此外,研究者还使用了统计分析方法,对不同项目类型和编程语言的项目上下文信息进行比较,从而揭示其差异性。
🖼️ 关键图片
📊 实验亮点
该研究通过分析401个开源仓库,构建了一个包含五个高级主题的项目上下文分类体系。研究发现,不同项目类型和编程语言的项目上下文信息存在显著差异。例如,某些项目更注重编码规范,而另一些项目更注重设计文档。这些发现为开发更有效的上下文感知AI工具提供了重要依据。
🎯 应用场景
该研究成果可应用于下一代上下文感知的AI开发者工具,例如智能代码补全、代码审查、代码生成等。通过将项目上下文信息融入到AI模型的输入中,可以显著提高代码质量和开发效率。此外,该研究还可以帮助开发者更好地理解项目上下文,提高团队协作效率。
📄 摘要(原文)
While Large Language Models (LLMs) have demonstrated remarkable capabilities, research shows that their effectiveness depends not only on explicit prompts but also on the broader context provided. This requirement is especially pronounced in software engineering, where the goals, architecture, and collaborative conventions of an existing project play critical roles in response quality. To support this, many AI coding assistants have introduced ways for developers to author persistent, machine-readable directives that encode a project's unique constraints. Although this practice is growing, the content of these directives remains unstudied. This paper presents a large-scale empirical study to characterize this emerging form of developer-provided context. Through a qualitative analysis of 401 open-source repositories containing cursor rules, we developed a comprehensive taxonomy of project context that developers consider essential, organized into five high-level themes: Conventions, Guidelines, Project Information, LLM Directives, and Examples. Our study also explores how this context varies across different project types and programming languages, offering implications for the next generation of context-aware AI developer tools.