Structural Reinforcement Learning for Heterogeneous Agent Macroeconomics
作者: Yucheng Yang, Chiyuan Wang, Andreas Schaab, Benjamin Moll
分类: econ.TH, cs.AI, cs.LG
发布日期: 2025-12-21
💡 一句话要点
提出结构化强化学习(SRL)方法,高效求解异质Agent宏观经济模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 结构化强化学习 异质Agent模型 宏观经济学 总量风险 市场出清
📋 核心要点
- 传统异质Agent宏观经济模型求解面临维度灾难和复杂市场出清条件等挑战。
- 论文提出结构化强化学习(SRL)方法,利用Agent结构知识,直接学习均衡价格动态。
- 实验表明,SRL方法能高效求解Krusell-Smith、Huggett和HANK等模型,几分钟内完成全局求解。
📝 摘要(中文)
本文提出了一种新的方法来构建和求解具有总量风险的异质Agent模型。该方法用低维价格代替横截面分布作为状态变量,并让Agent直接从模拟路径中学习均衡价格动态。为此,我们引入了一种结构化强化学习(SRL)方法,该方法通过模拟处理价格,同时利用Agent对其自身个体动态的结构性知识。我们的SRL方法为异质Agent模型提供了一种通用且高效的全局求解方法,它绕过了主方程,并能处理传统方法难以解决的问题,特别是重要的市场出清条件。我们在Krusell-Smith模型、具有总量冲击的Huggett模型以及具有前瞻性菲利普斯曲线的HANK模型中说明了该方法的有效性,所有这些模型都在几分钟内实现了全局求解。
🔬 方法详解
问题定义:异质Agent宏观经济模型旨在研究个体异质性如何影响宏观经济变量。传统方法,如基于主方程的方法,在处理高维状态空间和复杂市场出清条件时面临计算瓶颈。现有方法难以有效求解包含非平凡市场出清条件的问题,计算成本高昂。
核心思路:论文的核心思路是将宏观经济模型求解转化为一个强化学习问题,其中Agent通过与环境交互来学习最优策略。关键在于利用Agent自身的结构性知识,避免直接对整个状态空间进行建模。通过将价格作为状态变量,并让Agent直接从模拟路径中学习均衡价格动态,降低了问题的维度。
技术框架:SRL方法包含以下主要阶段:1. 模型设定:定义异质Agent的个体动态和总量冲击。2. 价格模拟:使用强化学习Agent模拟价格动态。3. Agent决策:每个Agent根据当前价格和自身状态做出决策。4. 市场出清:验证市场是否出清,并调整价格。5. 策略更新:根据市场出清情况,更新强化学习Agent的策略。
关键创新:最重要的技术创新点在于将结构化信息融入强化学习过程中。传统强化学习方法通常将环境视为黑盒,而SRL方法则利用Agent对自身个体动态的结构性知识,从而显著提高了学习效率。此外,该方法避免了直接求解主方程,从而能够处理高维状态空间。
关键设计:论文使用强化学习中的策略梯度方法来训练价格预测Agent。具体来说,Agent的目标是最大化其预期回报,回报函数与市场出清误差相关。论文中使用的具体网络结构和参数设置取决于所求解的模型,但通常包括多层感知机或循环神经网络。损失函数的设计旨在鼓励Agent预测能够实现市场出清的价格。
🖼️ 关键图片
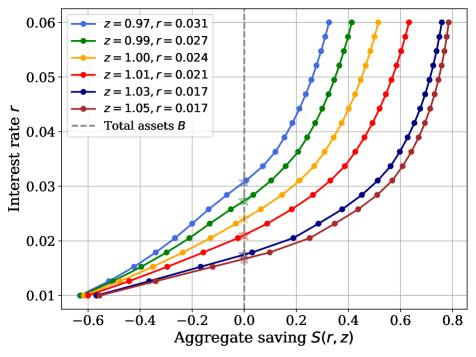
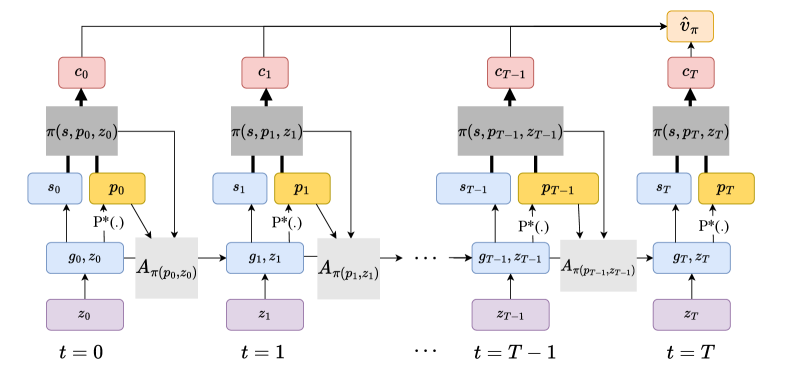

📊 实验亮点
论文在Krusell-Smith模型、具有总量冲击的Huggett模型以及具有前瞻性菲利普斯曲线的HANK模型上进行了实验。实验结果表明,SRL方法能够在几分钟内实现全局求解,显著优于传统方法。例如,在Krusell-Smith模型中,SRL方法能够快速收敛到精确解,并且对参数变化具有鲁棒性。
🎯 应用场景
该研究成果可广泛应用于宏观经济政策分析、金融市场建模和行为经济学等领域。通过高效求解异质Agent模型,可以更准确地评估政策对不同收入群体的影响,预测金融市场的波动,并理解个体行为对宏观经济的影响。该方法为研究复杂经济现象提供了新的工具。
📄 摘要(原文)
We present a new approach to formulating and solving heterogeneous agent models with aggregate risk. We replace the cross-sectional distribution with low-dimensional prices as state variables and let agents learn equilibrium price dynamics directly from simulated paths. To do so, we introduce a structural reinforcement learning (SRL) method which treats prices via simulation while exploiting agents' structural knowledge of their own individual dynamics. Our SRL method yields a general and highly efficient global solution method for heterogeneous agent models that sidesteps the Master equation and handles problems traditional methods struggle with, in particular nontrivial market-clearing conditions. We illustrate the approach in the Krusell-Smith model, the Huggett model with aggregate shocks, and a HANK model with a forward-looking Phillips curve, all of which we solve globally within minutes.