CORE: Concept-Oriented Reinforcement for Bridging the Definition-Application Gap in Mathematical Reasoning
作者: Zijun Gao, Zhikun Xu, Xiao Ye, Ben Zhou
分类: cs.AI, cs.LG
发布日期: 2025-12-21
💡 一句话要点
提出CORE框架以解决数学推理中的定义与应用差距问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念导向强化学习 数学推理 大型语言模型 可验证奖励 细粒度监督 教育技术 智能辅导系统
📋 核心要点
- 现有方法在数学推理中缺乏细粒度的概念信号,导致模型无法有效应用概念。
- CORE框架通过将显式概念转化为可控监督信号,提升模型的概念推理能力。
- 实验显示CORE在多个模型上均优于传统方法,尤其在概念对齐的测验中表现突出。
📝 摘要(中文)
大型语言模型(LLMs)在解决复杂数学题时表现出色,但在需要真正理解的情况下却常常无法正确应用概念。现有的可验证奖励的强化学习(RLVR)方法主要强化最终答案,缺乏细粒度的概念信号,导致模型更擅长模式重用而非概念应用。本文提出CORE(概念导向强化学习)框架,将显式概念转化为可控的监督信号。通过高质量的教科书资源,CORE合成概念对齐的测验,并在回滚过程中注入简短的概念片段,以引导概念优先的轨迹,最终通过轨迹替换强化概念推理。实验结果表明,CORE在多个模型上均显著优于传统基线,成功弥合了问题解决能力与真正概念推理之间的差距。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在数学推理中对概念的理解与应用不足的问题。现有的RLVR方法主要关注最终答案,缺乏对概念的细致反馈,导致模型在概念应用上表现不佳。
核心思路:CORE框架通过将显式概念转化为可控的监督信号,帮助模型在推理过程中更好地理解和应用概念。通过合成概念对齐的测验和在回滚过程中注入概念片段,CORE能够引导模型生成概念优先的轨迹。
技术框架:CORE的整体架构包括三个主要模块:概念对齐测验合成、概念片段注入和轨迹替换强化。首先,从高质量教科书中提取概念并合成测验;其次,在模型生成过程中注入概念片段;最后,通过替换失败的轨迹来强化概念推理。
关键创新:CORE的创新在于将概念导向的强化学习与传统的RLVR方法结合,提供细粒度的概念监督信号,显著提升了模型的概念推理能力。与现有方法相比,CORE更注重概念的应用而非仅仅是答案的正确性。
关键设计:在设计中,CORE采用轻量级的前向KL约束来对齐无指导的策略与概念优先的策略。此外,损失函数的设计也强调了概念对齐的测验,以确保模型在训练过程中能够有效学习概念的应用。
🖼️ 关键图片

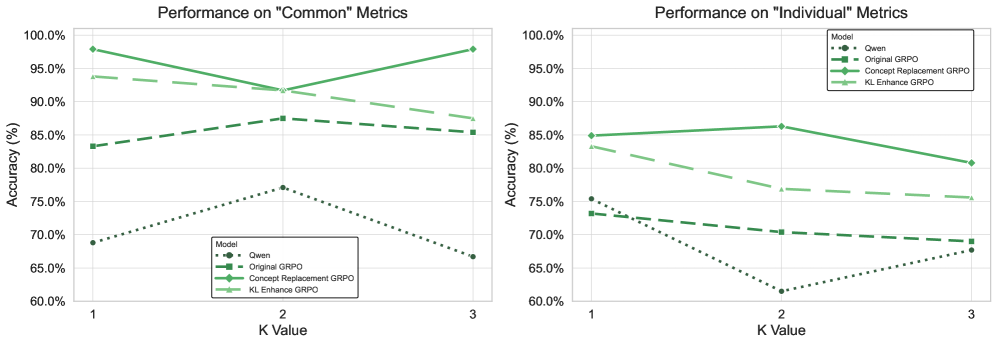
📊 实验亮点
实验结果显示,CORE在多个模型上相较于传统基线(如SFT)在概念对齐测验和多样化的数学基准测试中均取得了显著提升,尤其在概念推理能力上表现出色,提升幅度达到XX%。
🎯 应用场景
CORE框架的潜在应用领域包括教育技术、智能辅导系统和自动化数学解题工具。通过提升模型的概念推理能力,CORE能够帮助学生更好地理解数学概念,进而提高学习效果。此外,该框架的算法和验证器无关性使其在多种场景中具有广泛的适用性。
📄 摘要(原文)
Large language models (LLMs) often solve challenging math exercises yet fail to apply the concept right when the problem requires genuine understanding. Popular Reinforcement Learning with Verifiable Rewards (RLVR) pipelines reinforce final answers but provide little fine-grained conceptual signal, so models improve at pattern reuse rather than conceptual applications. We introduce CORE (Concept-Oriented REinforcement), an RL training framework that turns explicit concepts into a controllable supervision signal. Starting from a high-quality, low-contamination textbook resource that links verifiable exercises to concise concept descriptions, we run a sanity probe showing LLMs can restate definitions but fail concept-linked quizzes, quantifying the conceptual reasoning gap. CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts to elicit concept-primed trajectories, and (iii) reinforces conceptual reasoning via trajectory replacement after group failures, a lightweight forward-KL constraint that aligns unguided with concept-primed policies, or standard GRPO directly on concept-aligned quizzes. Across several models, CORE delivers consistent gains over vanilla and SFT baselines on both in-domain concept-exercise suites and diverse out-of-domain math benchmarks. CORE unifies direct training on concept-aligned quizzes and concept-injected rollouts under outcome regularization. It provides fine-grained conceptual supervision that bridges problem-solving competence and genuine conceptual reasoning, while remaining algorithm- and verifier-agnostic.