HARBOR: Holistic Adaptive Risk assessment model for BehaviORal healthcare
作者: Aditya Siddhant
分类: cs.AI
发布日期: 2025-12-21 (更新: 2026-01-04)
💡 一句话要点
提出HARBOR,用于行为健康风险评估的自适应语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 行为健康 风险评估 语言模型 纵向数据 情绪识别
📋 核心要点
- 行为健康风险评估面临患者数据复杂性和情绪时间动态性的挑战,传统方法难以有效应对。
- HARBOR通过构建行为健康感知的语言模型,直接预测离散的风险评分,从而简化评估流程。
- 实验表明,HARBOR在准确率上显著优于传统机器学习模型和通用LLM,验证了其有效性。
📝 摘要(中文)
由于患者数据的高度多模态特性以及情绪和情感障碍的时间动态性,行为健康风险评估仍然是一个具有挑战性的问题。虽然大型语言模型(LLM)已经展示了强大的推理能力,但它们在结构化临床风险评分中的有效性仍不清楚。本文介绍了HARBOR,一个行为健康感知语言模型,旨在预测离散的情绪和风险评分,称为Harbor风险评分(HRS),其整数范围从-3(严重抑郁症)到+3(躁狂症)。我们还发布了PEARL,一个纵向行为健康数据集,包含来自三名患者的四年每月观察数据,其中包含生理、行为和自我报告的心理健康信号。我们对传统机器学习模型、专有LLM和HARBOR在多个评估设置和消融实验中进行了基准测试。结果表明,HARBOR优于经典基线和现成的LLM,实现了69%的准确率,而逻辑回归为54%,最强的专有LLM基线为29%。
🔬 方法详解
问题定义:行为健康风险评估旨在根据患者的生理、行为和心理健康数据,预测其当前的情绪状态和潜在的风险等级。现有方法,如传统机器学习模型,难以有效整合多模态数据和捕捉情绪的时间动态变化。通用大型语言模型(LLM)虽然具备强大的推理能力,但在结构化临床风险评分任务中的表现尚不明确。
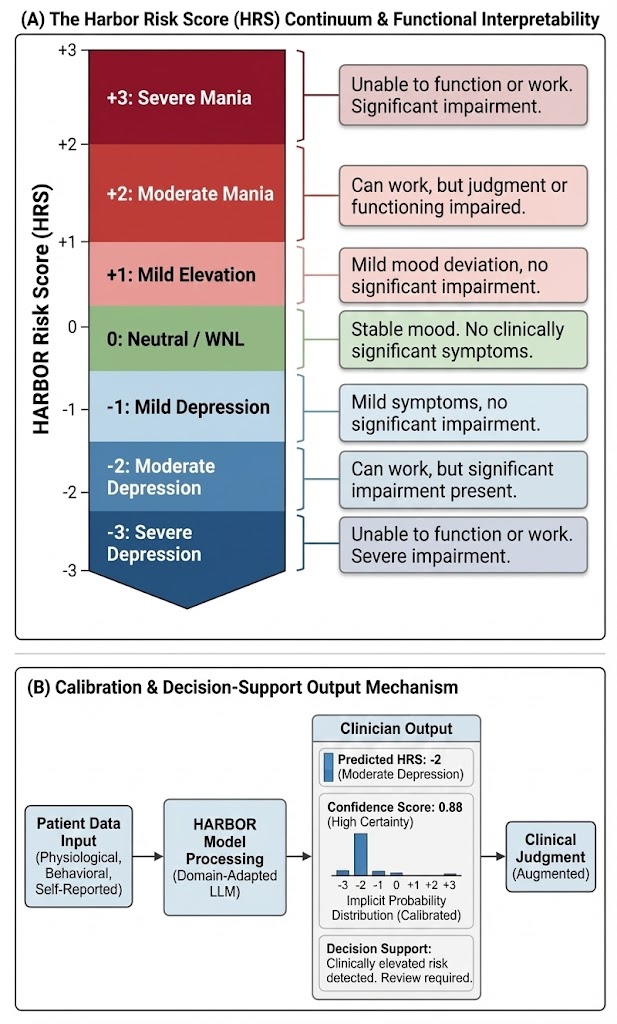
核心思路:HARBOR的核心思路是构建一个专门针对行为健康领域优化的语言模型。通过在行为健康相关的数据上进行训练,使模型能够更好地理解和推理患者的情绪状态和风险等级。该模型直接预测一个离散的风险评分(HRS),简化了评估流程,并提高了预测准确性。
技术框架:HARBOR的技术框架主要包括数据预处理、模型训练和风险评分预测三个阶段。首先,对PEARL数据集中的生理、行为和自我报告的心理健康信号进行预处理,提取有用的特征。然后,使用这些特征训练HARBOR模型,使其能够学习到数据与风险评分之间的映射关系。最后,利用训练好的HARBOR模型,根据新的患者数据预测其HRS。
关键创新:HARBOR的关键创新在于其行为健康感知的设计。与通用LLM相比,HARBOR在特定领域的数据上进行了训练,使其能够更好地理解和处理行为健康相关的信息。此外,HARBOR直接预测离散的风险评分,避免了复杂的后处理步骤,提高了评估效率。
关键设计:HARBOR的具体模型结构和训练细节在论文中未详细说明,属于未知信息。但可以推测,HARBOR可能采用了Transformer架构,并使用了交叉熵损失函数进行训练,以优化风险评分的预测准确率。PEARL数据集的构建,为模型的训练和评估提供了重要的数据基础。
🖼️ 关键图片
📊 实验亮点
HARBOR在PEARL数据集上进行了评估,结果表明其准确率达到了69%,显著优于逻辑回归(54%)和最强的专有LLM基线(29%)。这些结果表明,HARBOR在行为健康风险评估任务中具有显著的优势,能够更准确地预测患者的情绪状态和风险等级。
🎯 应用场景
HARBOR具有广泛的应用前景,可用于临床决策支持、远程患者监控和个性化治疗方案制定。通过自动化的风险评估,HARBOR可以帮助医生更快速、准确地识别高风险患者,并及时采取干预措施。此外,HARBOR还可以用于开发移动健康应用,为患者提供个性化的心理健康支持。
📄 摘要(原文)
Behavioral healthcare risk assessment remains a challenging problem due to the highly multimodal nature of patient data and the temporal dynamics of mood and affective disorders. While large language models (LLMs) have demonstrated strong reasoning capabilities, their effectiveness in structured clinical risk scoring remains unclear. In this work, we introduce HARBOR, a behavioral health aware language model designed to predict a discrete mood and risk score, termed the Harbor Risk Score (HRS), on an integer scale from -3 (severe depression) to +3 (mania). We also release PEARL, a longitudinal behavioral healthcare dataset spanning four years of monthly observations from three patients, containing physiological, behavioral, and self reported mental health signals. We benchmark traditional machine learning models, proprietary LLMs, and HARBOR across multiple evaluation settings and ablations. Our results show that HARBOR outperforms classical baselines and off the shelf LLMs, achieving 69 percent accuracy compared to 54 percent for logistic regression and 29 percent for the strongest proprietary LLM baseline.