Code2Doc: A Quality-First Curated Dataset for Code Documentation
作者: Recep Kaan Karaman, Meftun Akarsu
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-12-21 (更新: 2025-12-24)
💡 一句话要点
Code2Doc:高质量代码文档生成数据集,解决现有数据集质量问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码文档生成 数据集 数据质量 自然语言处理 软件工程
📋 核心要点
- 现有代码文档数据集质量参差不齐,存在噪声、重复和AI生成内容污染等问题,影响模型训练效果。
- Code2Doc通过四阶段筛选流程,强制文档完整性、清晰度,并去除重复和AI生成内容,构建高质量数据集。
- 实验表明,在Code2Doc上微调大型语言模型,BLEU和ROUGE-L指标显著提升,验证了数据集的有效性。
📝 摘要(中文)
自动代码文档生成模型的性能严重依赖于训练数据的质量。然而,现有的大多数代码文档数据集是通过大规模抓取公共仓库构建的,质量控制有限。这导致文档噪声、大量重复以及越来越多的人工智能生成内容污染。这些问题削弱了学习模型的监督信号,并使评估复杂化。本文提出了Code2Doc,一个高质量的代码文档生成数据集,包含13358个函数级别的代码-文档对,涵盖Python、Java、TypeScript、JavaScript和C++五种编程语言。该数据集使用四阶段的筛选流程构建,强制文档的完整性和清晰度,基于结构和复杂性标准过滤函数,删除完全和近似重复的代码,并识别可能由AI生成的文档。从52069个提取的候选样本中,只有25.6%满足所有质量约束。对数据集的分析表明,其平均文档质量得分为6.93(满分10分)。总体而言,86.9%的样本包含显式类型注释,只有2.9%的样本被标记为可能由AI生成。基线实验表明,尽管数据集规模不大,但在Code2Doc上微调大型语言模型,BLEU和ROUGE-L指标分别比零样本性能提高了29.47%和24.04%。本文发布了数据集和完整的筛选流程,以支持自动代码文档生成的可复现研究。
🔬 方法详解
问题定义:现有代码文档生成数据集通常通过大规模爬取构建,缺乏严格的质量控制,导致数据集中存在大量噪声、重复数据以及AI生成的内容,这些问题严重影响了训练模型的性能,并使得模型评估变得困难。因此,需要一个高质量、干净的代码文档数据集来提升代码文档生成模型的性能。
核心思路:Code2Doc的核心思路是通过一个多阶段的筛选流程,从大规模的候选代码-文档对中,严格筛选出高质量的样本。该流程旨在确保文档的完整性和清晰度,过滤掉结构复杂或不规范的代码,去除重复的代码片段,并识别并排除潜在的AI生成内容。通过这种方式,可以构建一个高质量、低噪声的数据集,从而提升代码文档生成模型的训练效果。
技术框架:Code2Doc的构建流程包含四个主要阶段:1) 文档质量评估:评估文档的完整性和清晰度,例如检查是否包含类型注释等。2) 代码结构和复杂性过滤:基于代码的结构和复杂性指标,过滤掉不适合作为训练样本的代码。3) 重复数据删除:删除完全重复和近似重复的代码-文档对,避免模型过拟合。4) AI生成内容识别:识别并排除可能由AI生成的文档,减少数据污染。
关键创新:Code2Doc的关键创新在于其质量优先的筛选流程,该流程能够有效地去除噪声数据,并保留高质量的样本。与以往大规模爬取的数据集构建方法不同,Code2Doc更加注重数据的质量,通过多阶段的筛选,确保数据集的干净和可靠。此外,该数据集还提供了详细的分析报告,方便研究人员了解数据集的特点和适用范围。
关键设计:在文档质量评估阶段,使用了多种指标来衡量文档的完整性和清晰度,例如类型注释的比例、文档长度等。在代码结构和复杂性过滤阶段,使用了代码的圈复杂度、代码行数等指标。在重复数据删除阶段,使用了基于文本相似度的算法来识别近似重复的代码-文档对。在AI生成内容识别阶段,使用了基于文本特征的分类器来判断文档是否可能由AI生成。具体的参数设置和阈值选择是基于经验和实验结果进行调整的。
🖼️ 关键图片
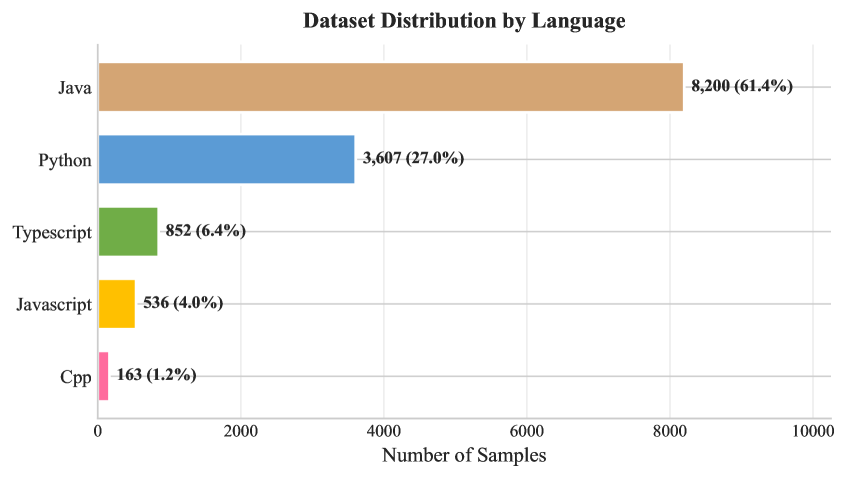
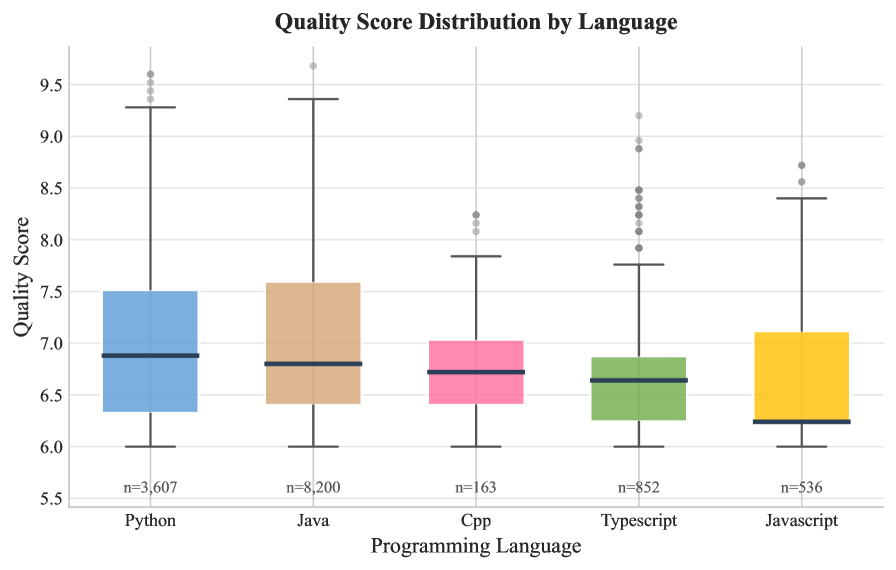
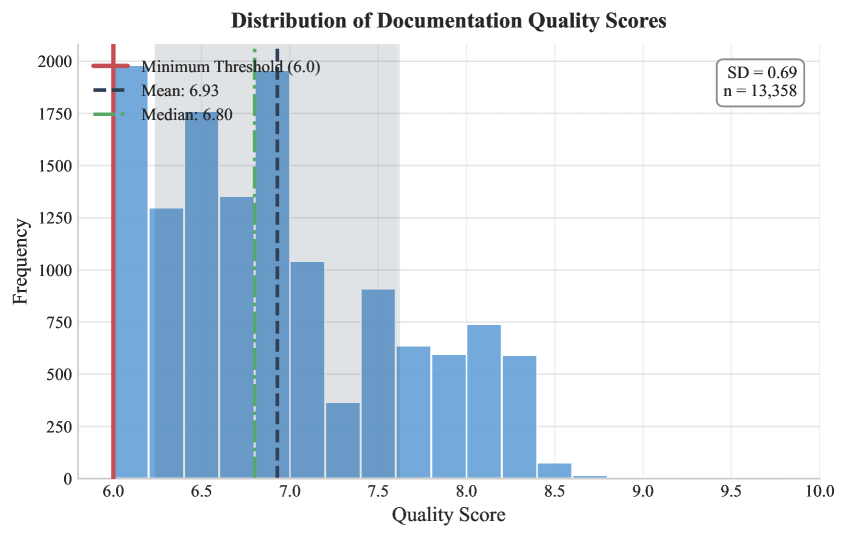
📊 实验亮点
Code2Doc数据集的平均文档质量得分为6.93(满分10分),86.9%的样本包含显式类型注释,只有2.9%的样本被标记为可能由AI生成。在Code2Doc上微调大型语言模型,BLEU指标比零样本性能提高了29.47%,ROUGE-L指标提高了24.04%,证明了该数据集的有效性。
🎯 应用场景
Code2Doc数据集可用于训练和评估自动代码文档生成模型,提高软件开发效率和代码可维护性。高质量的代码文档有助于开发者理解和使用代码,降低学习成本,并减少潜在的错误。该数据集还可用于研究代码文档生成中的各种问题,例如如何生成更准确、更自然的文档,以及如何处理不同编程语言的文档生成。
📄 摘要(原文)
The performance of automatic code documentation generation models depends critically on the quality of the training data used for supervision. However, most existing code documentation datasets are constructed through large scale scraping of public repositories with limited quality control. As a result, they often contain noisy documentation, extensive duplication, and increasing contamination from AI generated content. These issues weaken the supervision signal available to learning-based models and complicate evaluation. We introduce Code2Doc, a quality-first curated dataset for function-level code documentation generation. Code2Doc consists of 13,358 high-quality function-documentation pairs extracted from widely used open-source repositories spanning five programming languages: Python, Java, TypeScript, JavaScript, and C++. The dataset is constructed using a four-stage curation pipeline that enforces documentation completeness and clarity, filters functions based on structural and complexity criteria, removes exact and near-duplicate code, and identifies documentation likely to be AI generated. Starting from 52,069 extracted candidates, only 25.6% satisfy all quality constraints. We provide a detailed analysis of the resulting dataset, which achieves a mean documentation quality score of 6.93 out of 10. Overall, 86.9% of samples contain explicit type annotations, and only 2.9% are flagged as potentially AI generated. Baseline experiments show that fine-tuning a large language model on Code2Doc yields relative improvements of 29.47% in BLEU and 24.04% in ROUGE-L over zero shot performance, despite the modest dataset size. We release both the dataset and the full curation pipeline to support reproducible research on automatic code documentation generation.