Remoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
作者: Wentao Liu, Yuhao Hu, Ruiting Zhou, Baochun Li, Ne Wang
分类: cs.DC, cs.AI
发布日期: 2025-12-21
💡 一句话要点
Remoe:面向Serverless计算的高效低成本MoE推理系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 Serverless计算 异构计算 专家卸载 推理优化
📋 核心要点
- 现有MoE模型在Serverless环境下推理面临内存开销大、成本高昂的问题,简单的模型划分难以有效缓解。
- Remoe通过异构资源分配、专家卸载和预测激活模式等方法,优化MoE模型在Serverless环境下的推理效率。
- 实验表明,Remoe相比现有方法,显著降低了推理成本和冷启动延迟,提升了Serverless MoE推理的性能。
📝 摘要(中文)
混合专家模型(MoE)由于其通过稀疏专家激活扩展模型容量的能力,已成为大型语言模型(LLM)中的主导架构。同时,Serverless计算凭借其弹性和按使用付费的计费方式,非常适合部署具有突发工作负载的MoE。然而,MoE模型中大量的专家导致了内存密集型参数缓存,从而导致高昂的推理成本。由于输入相关的专家激活,这些成本难以通过简单的模型划分来缓解。为了解决这些问题,我们提出了Remoe,一个为Serverless计算量身定制的异构MoE推理系统。Remoe将非专家模块分配给GPU,将专家模块分配给CPU,并将不经常激活的专家卸载到单独的Serverless函数,以减少内存开销并实现并行执行。我们结合了三个关键技术:(1)一种基于输入语义相似性预测专家激活模式的相似提示搜索(SPS)算法;(2)一种通过最坏情况内存估计确保服务级别目标(SLO)的主模型预分配(MMP)算法;(3)一个利用拉格朗日对偶和最长处理时间(LPT)算法的联合内存和副本优化框架。我们在Kubernetes上实现了Remoe,并在多个LLM基准上对其进行了评估。实验结果表明,与最先进的基线相比,Remoe降低了高达57%的推理成本和47%的冷启动延迟。
🔬 方法详解
问题定义:论文旨在解决在Serverless计算环境中部署MoE模型时,由于大量专家参数导致的内存开销和高推理成本问题。现有方法,如简单的模型划分,无法有效解决输入依赖的专家激活模式带来的挑战,导致资源利用率低和成本高昂。
核心思路:Remoe的核心思路是利用Serverless计算的弹性特性,通过异构资源分配和专家卸载,降低内存开销并实现并行执行。它预测专家激活模式,并将不常用的专家卸载到独立的Serverless函数中,从而减少常驻内存的需求。
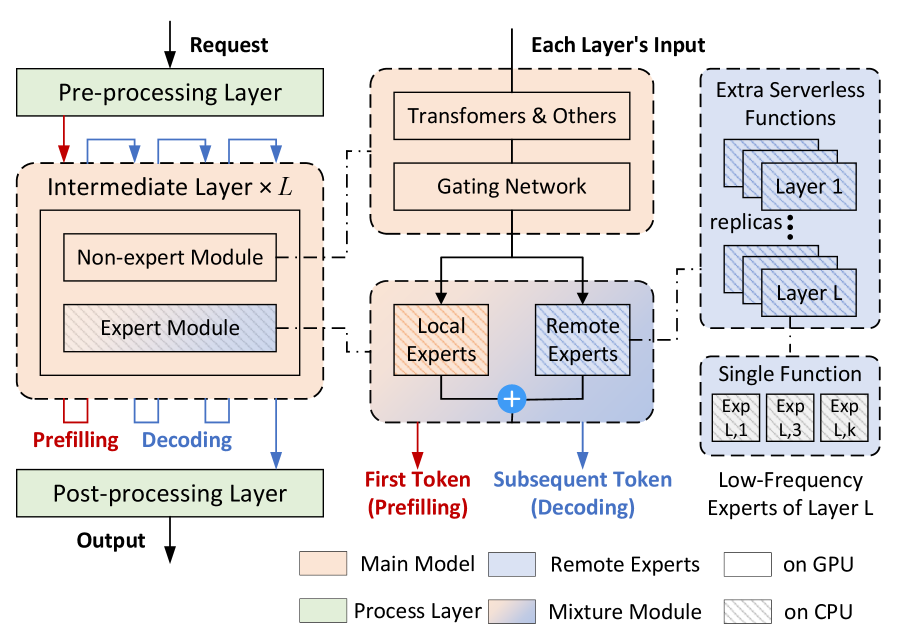
技术框架:Remoe系统包含以下主要模块:1) 相似提示搜索(SPS):基于输入语义相似性预测专家激活模式;2) 主模型预分配(MMP):通过最坏情况内存估计确保服务级别目标(SLO);3) 联合内存和副本优化:利用拉格朗日对偶和最长处理时间(LPT)算法优化资源分配。整体流程为:接收输入,SPS预测专家激活,MMP预分配资源,执行推理,根据激活情况动态卸载/加载专家。
关键创新:Remoe的关键创新在于其异构资源管理和动态专家卸载策略。与传统方法不同,Remoe将非专家模块分配给GPU,专家模块分配给CPU,并将不常用的专家卸载到Serverless函数。这种策略能够有效降低内存开销,并充分利用Serverless计算的弹性。
关键设计:SPS算法使用语义相似度度量来预测专家激活模式,MMP算法基于最坏情况的内存需求进行资源预分配,联合优化框架使用拉格朗日对偶分解问题,并使用LPT算法进行资源调度。具体的参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Remoe在多个LLM基准测试中,与最先进的基线方法相比,能够降低高达57%的推理成本和47%的冷启动延迟。这些显著的性能提升验证了Remoe在Serverless环境下部署MoE模型的有效性。
🎯 应用场景
Remoe适用于需要大规模语言模型推理的Serverless应用场景,例如智能客服、文本生成、机器翻译等。通过降低推理成本和冷启动延迟,Remoe能够提升这些应用的性能和用户体验,并降低运营成本。该研究对Serverless环境下大规模模型部署具有重要意义。
📄 摘要(原文)
Mixture-of-Experts (MoE) has become a dominant architecture in large language models (LLMs) due to its ability to scale model capacity via sparse expert activation. Meanwhile, serverless computing, with its elasticity and pay-per-use billing, is well-suited for deploying MoEs with bursty workloads. However, the large number of experts in MoE models incurs high inference costs due to memory-intensive parameter caching. These costs are difficult to mitigate via simple model partitioning due to input-dependent expert activation. To address these issues, we propose Remoe, a heterogeneous MoE inference system tailored for serverless computing. Remoe assigns non-expert modules to GPUs and expert modules to CPUs, and further offloads infrequently activated experts to separate serverless functions to reduce memory overhead and enable parallel execution. We incorporate three key techniques: (1) a Similar Prompts Searching (SPS) algorithm to predict expert activation patterns based on semantic similarity of inputs; (2) a Main Model Pre-allocation (MMP) algorithm to ensure service-level objectives (SLOs) via worst-case memory estimation; and (3) a joint memory and replica optimization framework leveraging Lagrangian duality and the Longest Processing Time (LPT) algorithm. We implement Remoe on Kubernetes and evaluate it across multiple LLM benchmarks. Experimental results show that Remoe reduces inference cost by up to 57% and cold start latency by 47% compared to state-of-the-art baselines.