ChronoDreamer: Action-Conditioned World Model as an Online Simulator for Robotic Planning
作者: Zhenhao Zhou, Dan Negrut
分类: cs.AI, cs.RO
发布日期: 2025-12-21
💡 一句话要点
ChronoDreamer:用于机器人规划的动作条件世界模型,作为在线模拟器
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 机器人操作 世界模型 接触预测 时空Transformer 视觉-语言模型
📋 核心要点
- 现有机器人操作方法在处理接触丰富的任务时面临挑战,难以准确预测和模拟复杂的物理交互。
- ChronoDreamer通过时空Transformer预测未来视频帧、接触分布和关节角度,利用深度加权Gaussian splat编码接触信息。
- 实验表明,该模型能保持空间连贯性并生成合理的接触预测,同时LLM能有效区分碰撞和非碰撞轨迹。
📝 摘要(中文)
本文提出ChronoDreamer,一个用于接触丰富的机器人操作的动作条件世界模型。给定自我中心的RGB帧、接触图、动作和关节状态的历史,ChronoDreamer通过一个用MaskGIT风格的掩码预测训练的时空Transformer来预测未来的视频帧、接触分布和关节角度。接触被编码为深度加权的Gaussian splat图像,将3D力渲染成适合视觉骨干网络的相机对齐格式。在推理时,预测的rollout由一个视觉-语言模型评估,该模型推理碰撞的可能性,从而在执行前实现对不安全动作的拒绝采样。我们在DreamerBench上进行训练和评估,DreamerBench是一个使用Project Chrono生成的模拟数据集,它提供了跨刚性和可变形对象场景的同步RGB、接触splat、本体感受和物理注释。定性结果表明,该模型在非接触运动期间保持空间连贯性,并生成合理的接触预测,而基于LLM的判别器能够区分碰撞和非碰撞轨迹。
🔬 方法详解
问题定义:现有的机器人操作方法在处理接触丰富的任务时,难以准确预测和模拟复杂的物理交互。尤其是在线机器人规划需要快速且准确的物理环境模拟,而传统方法在处理复杂接触和形变时存在局限性。因此,如何构建一个能够准确预测未来状态,并能有效评估动作安全性的世界模型是关键问题。
核心思路:ChronoDreamer的核心思路是构建一个动作条件的世界模型,该模型能够根据历史的视觉信息、接触信息、动作和关节状态,预测未来的视频帧、接触分布和关节角度。通过将接触信息编码为深度加权的Gaussian splat图像,并利用时空Transformer进行预测,模型能够更好地理解和模拟复杂的物理交互。此外,利用视觉-语言模型进行碰撞风险评估,实现动作的拒绝采样,提高规划的安全性。
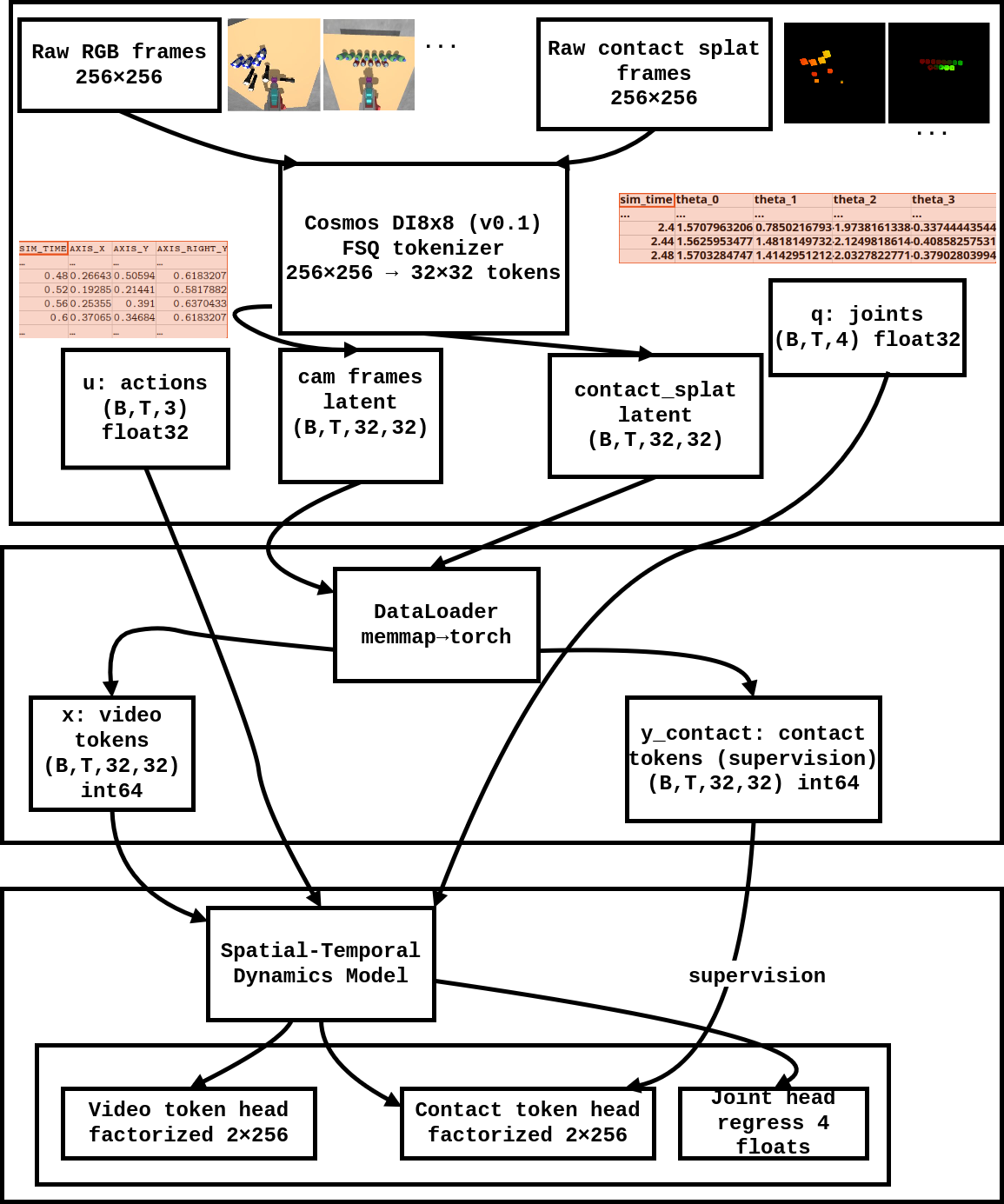
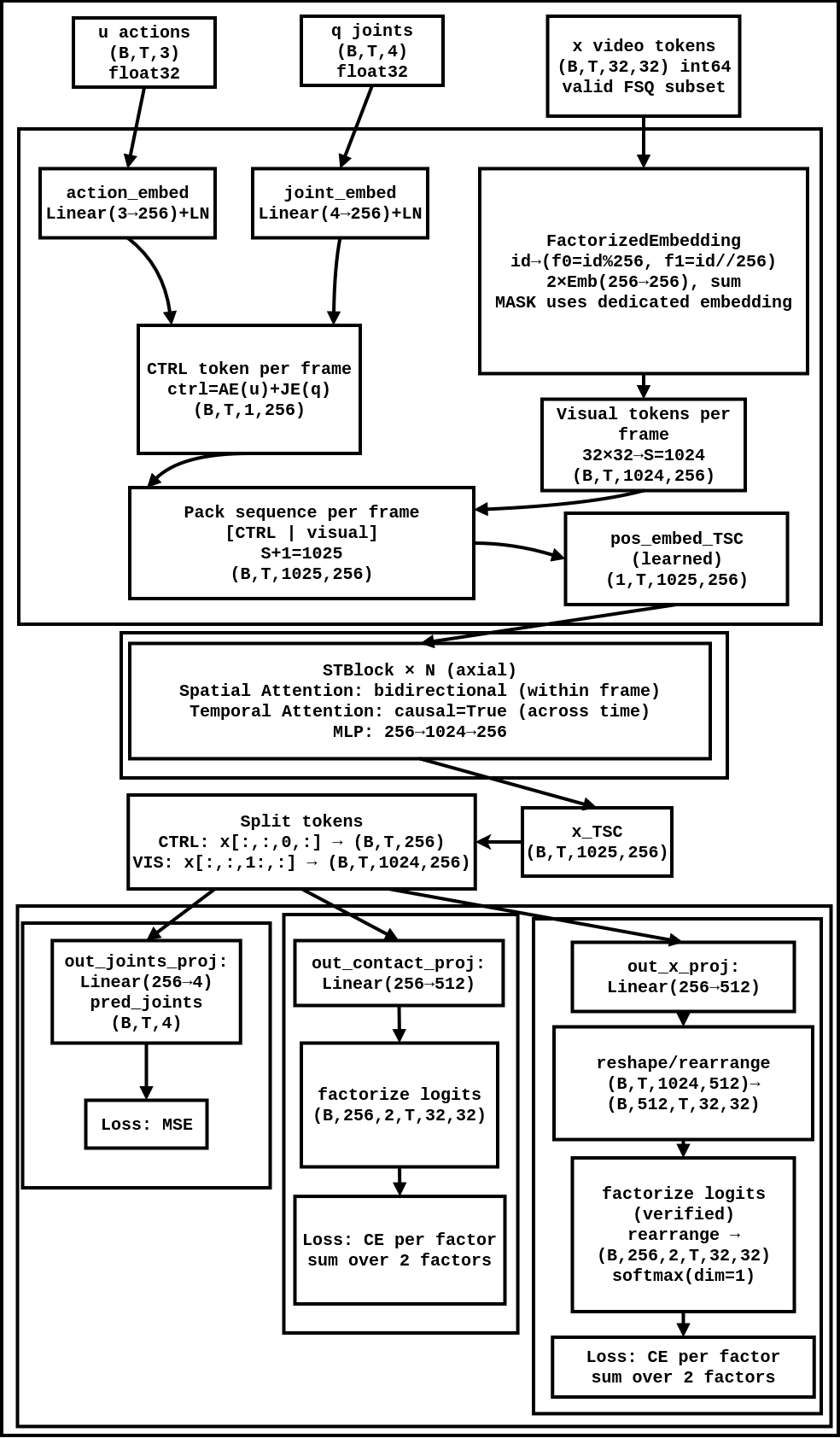
技术框架:ChronoDreamer的整体框架包括以下几个主要模块:1) 数据输入模块:接收历史的RGB帧、接触图、动作和关节状态。2) 接触编码模块:将接触信息编码为深度加权的Gaussian splat图像。3) 时空Transformer预测模块:利用时空Transformer预测未来的视频帧、接触分布和关节角度。4) 视觉-语言模型评估模块:利用视觉-语言模型评估预测轨迹的碰撞风险,并进行动作的拒绝采样。
关键创新:ChronoDreamer的关键创新在于以下几个方面:1) 提出了一种新的接触编码方式,将接触信息编码为深度加权的Gaussian splat图像,使其能够更好地被视觉骨干网络处理。2) 利用时空Transformer进行预测,能够更好地捕捉时间和空间上的依赖关系。3) 结合视觉-语言模型进行碰撞风险评估,实现动作的拒绝采样,提高了规划的安全性。
关键设计:在接触编码模块中,深度加权的Gaussian splat图像的生成方式是关键。在时空Transformer中,MaskGIT风格的掩码预测方式被用于训练,以提高模型的预测能力。视觉-语言模型的选择和训练方式,以及拒绝采样的阈值设置,都会影响最终的性能。
🖼️ 关键图片

📊 实验亮点
ChronoDreamer在DreamerBench数据集上进行了评估,定性结果表明,该模型在非接触运动期间保持空间连贯性,并生成合理的接触预测。基于LLM的判别器能够有效区分碰撞和非碰撞轨迹,验证了模型在碰撞风险评估方面的能力。虽然论文中没有给出具体的性能数据,但定性结果表明该模型具有良好的潜力。
🎯 应用场景
ChronoDreamer可应用于各种接触丰富的机器人操作任务,例如装配、抓取、操作工具等。该模型能够提高机器人规划的效率和安全性,降低因碰撞造成的损坏风险。未来,该技术有望应用于更复杂的机器人系统,例如自主导航、医疗机器人等领域,实现更智能、更安全的机器人操作。
📄 摘要(原文)
We present ChronoDreamer, an action-conditioned world model for contact-rich robotic manipulation. Given a history of egocentric RGB frames, contact maps, actions, and joint states, ChronoDreamer predicts future video frames, contact distributions, and joint angles via a spatial-temporal transformer trained with MaskGIT-style masked prediction. Contact is encoded as depth-weighted Gaussian splat images that render 3D forces into a camera-aligned format suitable for vision backbones. At inference, predicted rollouts are evaluated by a vision-language model that reasons about collision likelihood, enabling rejection sampling of unsafe actions before execution. We train and evaluate on DreamerBench, a simulation dataset generated with Project Chrono that provides synchronized RGB, contact splat, proprioception, and physics annotations across rigid and deformable object scenarios. Qualitative results demonstrate that the model preserves spatial coherence during non-contact motion and generates plausible contact predictions, while the LLM-based judge distinguishes collision from non-collision trajectories.