ESearch-R1: Learning Cost-Aware MLLM Agents for Interactive Embodied Search via Reinforcement Learning
作者: Weijie Zhou, Xuangtang Xiong, Ye Tian, Lijun Yue, Xinyu Wu, Wei Li, Chaoyang Zhao, Honghui Dong, Ming Tang, Jinqiao Wang, Zhengyou Zhang
分类: cs.AI, cs.CV
发布日期: 2025-12-21
💡 一句话要点
提出ESearch-R1,通过强化学习优化成本感知的MLLM智能体,用于交互式具身搜索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 多模态大语言模型 强化学习 成本感知 人机交互
📋 核心要点
- 现有具身智能体在处理模糊指令时,难以平衡物理探索成本与人机交互成本,缺乏成本感知的战略推理。
- ESearch-R1框架将交互式对话、情景记忆检索和物理导航统一到单一决策过程,实现成本感知的具身推理。
- 提出的HC-GRPO通过强化学习优化MLLM,在信息增益和异构成本之间实现最佳权衡,显著提升任务成功率并降低运营成本。
📝 摘要(中文)
多模态大型语言模型(MLLMs)赋予了具身智能体卓越的规划和推理能力。然而,当面对模糊的自然语言指令(例如,在杂乱的房间里“取工具”)时,当前的智能体通常无法平衡物理探索的高成本与人机交互的认知成本。它们通常将消除歧义视为一个被动的感知问题,缺乏最小化总任务执行成本的战略推理。为了弥合这一差距,我们提出了ESearch-R1,一个成本感知的具身推理框架,它将交互式对话(Ask)、情景记忆检索(GetMemory)和物理导航(Navigate)统一到一个单一的决策过程中。我们引入了HC-GRPO(异构成本感知组相对策略优化)。与依赖于独立价值评论器的传统PPO不同,HC-GRPO通过对推理轨迹组进行采样,并强化那些在信息增益和异构成本(例如,导航时间和人类注意力)之间实现最佳权衡的轨迹组来优化MLLM。在AI2-THOR中进行的大量实验表明,ESearch-R1显著优于基于标准ReAct的智能体。它提高了任务成功率,同时将总运营成本降低了约50%,验证了GRPO在使MLLM智能体与物理世界约束对齐方面的有效性。
🔬 方法详解
问题定义:论文旨在解决具身智能体在面对模糊指令时,无法有效平衡物理探索成本(如导航时间)和认知成本(如人机交互)的问题。现有方法通常将消除歧义视为被动感知问题,缺乏战略推理,导致任务执行成本高昂。
核心思路:论文的核心思路是将交互式对话(Ask)、情景记忆检索(GetMemory)和物理导航(Navigate)整合到一个统一的决策过程中,并利用强化学习训练智能体,使其能够根据不同行为的成本和收益进行权衡,从而最小化总任务执行成本。
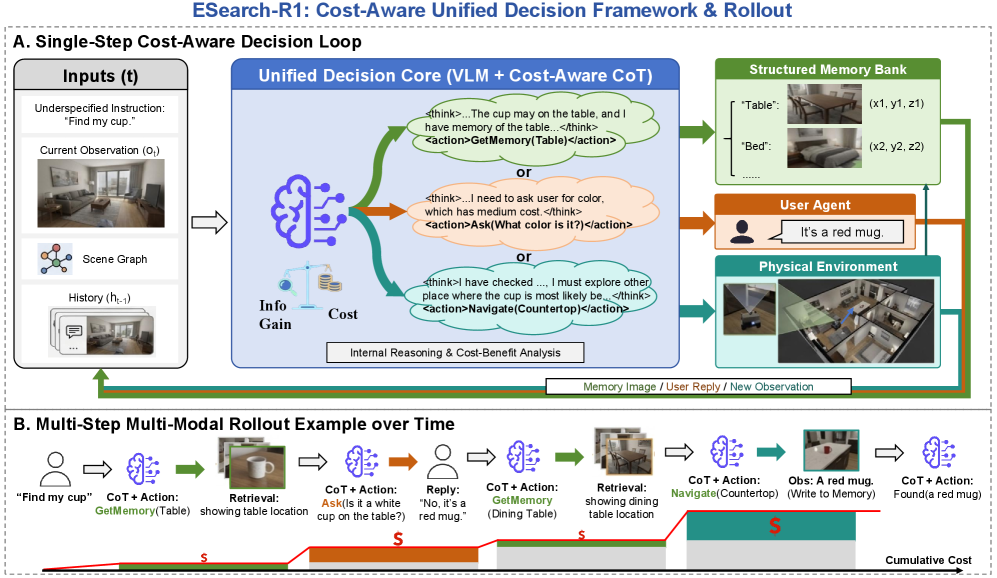
技术框架:ESearch-R1框架包含三个主要模块:Ask模块负责与人类进行交互以消除歧义;GetMemory模块负责从情景记忆中检索相关信息;Navigate模块负责在环境中进行物理导航。这三个模块通过一个统一的决策过程进行协调,该过程由一个MLLM驱动,并使用强化学习进行训练。
关键创新:论文的关键创新在于提出了HC-GRPO(Heterogeneous Cost-Aware Group Relative Policy Optimization)。与传统的PPO算法不同,HC-GRPO不是使用独立的价值评论器,而是通过对推理轨迹组进行采样,并强化那些在信息增益和异构成本之间实现最佳权衡的轨迹组来优化MLLM。这种方法能够更好地将MLLM与物理世界的约束对齐。
关键设计:HC-GRPO的关键设计包括:1) 使用异构成本函数,考虑导航时间、人机交互次数等多种成本;2) 使用组相对策略优化,通过比较不同轨迹组的性能来更有效地学习;3) 使用MLLM作为策略网络,利用其强大的语言理解和推理能力。
🖼️ 关键图片

📊 实验亮点
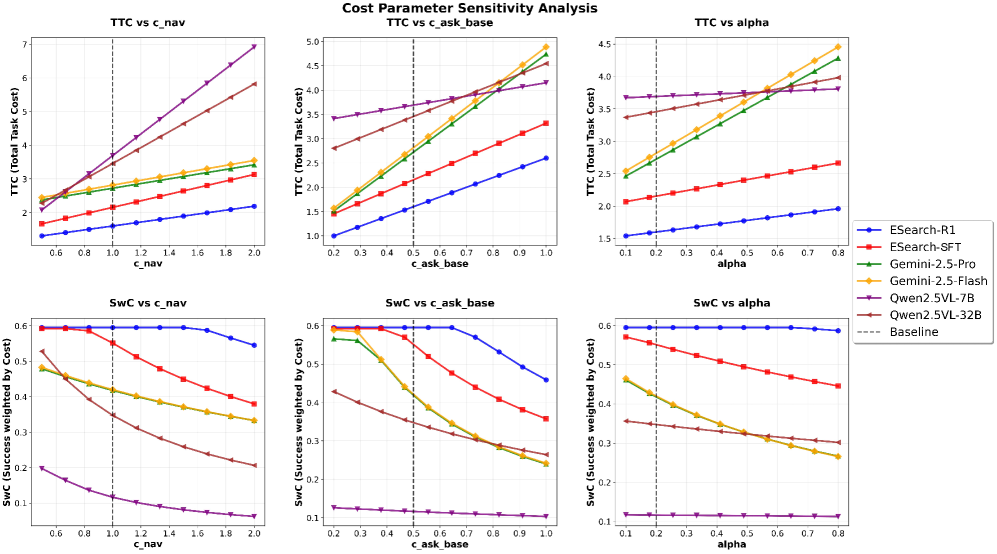
实验结果表明,ESearch-R1在AI2-THOR环境中显著优于基于标准ReAct的智能体。在提高任务成功率的同时,总运营成本降低了约50%。这验证了HC-GRPO在优化MLLM智能体,使其更好地适应物理世界约束方面的有效性。
🎯 应用场景
该研究成果可应用于智能家居、仓储物流、机器人助手等领域。通过赋予智能体成本感知的推理能力,可以使其在复杂环境中更有效地完成任务,降低运营成本,提高用户体验。未来,该技术有望进一步扩展到更广泛的具身智能应用场景。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have empowered embodied agents with remarkable capabilities in planning and reasoning. However, when facing ambiguous natural language instructions (e.g., "fetch the tool" in a cluttered room), current agents often fail to balance the high cost of physical exploration against the cognitive cost of human interaction. They typically treat disambiguation as a passive perception problem, lacking the strategic reasoning to minimize total task execution costs. To bridge this gap, we propose ESearch-R1, a cost-aware embodied reasoning framework that unifies interactive dialogue (Ask), episodic memory retrieval (GetMemory), and physical navigation (Navigate) into a single decision process. We introduce HC-GRPO (Heterogeneous Cost-Aware Group Relative Policy Optimization). Unlike traditional PPO which relies on a separate value critic, HC-GRPO optimizes the MLLM by sampling groups of reasoning trajectories and reinforcing those that achieve the optimal trade-off between information gain and heterogeneous costs (e.g., navigate time, and human attention). Extensive experiments in AI2-THOR demonstrate that ESearch-R1 significantly outperforms standard ReAct-based agents. It improves task success rates while reducing total operational costs by approximately 50\%, validating the effectiveness of GRPO in aligning MLLM agents with physical world constraints.