Bidirectional RAG: Safe Self-Improving Retrieval-Augmented Generation Through Multi-Stage Validation
作者: Teja Chinthala
分类: cs.AI
发布日期: 2025-12-20
备注: 10 pages, 2 figures, 2 tables. 36 experiments across 4 datasets with 3 random seeds. Code available upon request
💡 一句话要点
提出Bidirectional RAG,通过多阶段验证实现安全自提升的检索增强生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 自提升学习 知识库更新 多阶段验证 自然语言推理
📋 核心要点
- 传统RAG系统依赖静态语料库,无法从用户交互中学习和进化,限制了其知识的动态更新。
- Bidirectional RAG通过验证生成响应的回写,安全地扩展语料库,实现RAG系统的自提升能力。
- 实验表明,Bidirectional RAG在覆盖率上显著优于标准RAG,同时有效控制了语料库的膨胀。
📝 摘要(中文)
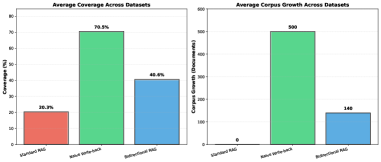
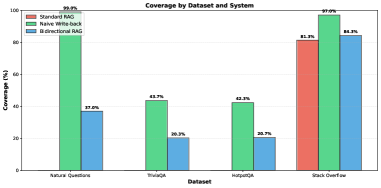
检索增强生成(RAG)系统通过将大型语言模型与外部知识库相结合来增强其响应能力,但传统的RAG架构使用静态语料库,无法从用户交互中演进。本文提出了一种新颖的RAG架构——Bidirectional RAG,它通过验证高质量生成响应的回写来实现安全的语料库扩展。该系统采用多阶段接受层,结合了基于自然语言推理(NLI)的grounding验证、归因检查和新颖性检测,以防止幻觉污染,同时实现知识积累。在Natural Questions、TriviaQA、HotpotQA和Stack Overflow四个数据集上,经过三次随机种子实验,Bidirectional RAG实现了40.58%的平均覆盖率,几乎是标准RAG(20.33%)的两倍,同时比naive回写减少了72%的文档添加(140 vs 500)。这项工作表明,在严格验证的约束下,自提升RAG是可行且安全的,为RAG系统从部署中学习提供了一条实用途径。
🔬 方法详解
问题定义:现有RAG系统使用静态语料库,无法利用用户交互产生的高质量信息进行知识更新,导致系统无法持续学习和进化。简单的将生成内容回写到语料库中,容易引入错误信息(幻觉),污染知识库,降低系统性能。
核心思路:Bidirectional RAG的核心思路是通过一个多阶段的验证机制,筛选高质量的生成内容,并将其安全地回写到语料库中,从而实现RAG系统的自提升。这种双向的交互(检索增强生成和生成内容回写)使得系统能够不断学习和适应新的信息。
技术框架:Bidirectional RAG包含以下主要模块:1) 标准RAG流程:使用检索模块从外部知识库中检索相关信息,并将其与用户query一起输入到生成模型中,生成响应。2) 多阶段接受层:对生成的响应进行多重验证,包括:a) Grounding Verification:使用NLI模型验证生成内容是否与检索到的证据一致;b) Attribution Checking:检查生成内容是否能够追溯到原始知识来源;c) Novelty Detection:检测生成内容是否为新的知识,避免重复信息。3) 语料库更新:只有通过多阶段验证的生成内容才会被安全地回写到语料库中。
关键创新:Bidirectional RAG的关键创新在于其安全自提升的架构,通过多阶段验证机制,有效防止了幻觉污染,同时实现了知识的积累。与简单的回写方法相比,Bidirectional RAG能够更有效地扩展语料库,并保证知识的质量。
关键设计:多阶段接受层的各个验证模块是关键。NLI模型用于评估生成内容与检索证据的蕴含关系,需要选择合适的预训练模型并进行微调。Attribution Checking需要维护知识来源的元数据,并设计有效的追溯算法。Novelty Detection可以使用聚类或相似度计算等方法来判断生成内容是否为新的知识。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Bidirectional RAG在四个数据集上实现了40.58%的平均覆盖率,几乎是标准RAG(20.33%)的两倍。同时,与naive回写相比,Bidirectional RAG减少了72%的文档添加(140 vs 500),表明其能够更有效地扩展语料库,并控制知识库的膨胀。这些结果验证了Bidirectional RAG在安全自提升方面的有效性。
🎯 应用场景
Bidirectional RAG可应用于需要持续学习和知识更新的场景,例如智能客服、问答系统、知识图谱构建等。通过从用户交互中学习,系统能够不断提升其响应质量和知识覆盖范围,更好地满足用户需求。该方法还可用于构建动态的、自适应的知识库,为各种AI应用提供更可靠的知识支撑。
📄 摘要(原文)
Retrieval-Augmented Generation RAG systems enhance large language models by grounding responses in external knowledge bases, but conventional RAG architectures operate with static corpora that cannot evolve from user interactions. We introduce Bidirectional RAG, a novel RAG architecture that enables safe corpus expansion through validated write back of high quality generated responses. Our system employs a multi stage acceptance layer combining grounding verification (NLI based entailment, attribution checking, and novelty detection to prevent hallucination pollution while enabling knowledge accumulation. Across four datasets Natural Questions, TriviaQA, HotpotQA, Stack Overflow with three random seeds 12 experiments per system, Bidirectional RAG achieves 40.58% average coverage nearly doubling Standard RAG 20.33% while adding 72% fewer documents than naive write back 140 vs 500. Our work demonstrates that self improving RAG is feasible and safe when governed by rigorous validation, offering a practical path toward RAG systems that learn from deployment.