Large Language Models as Discounted Bayesian Filters
作者: Jensen Zhang, Jing Yang, Keze Wang
分类: cs.AI
发布日期: 2025-12-20
备注: Under submission
💡 一句话要点
提出基于折扣贝叶斯滤波的大语言模型在线推理评估框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 在线推理 贝叶斯滤波 折扣因子 信念更新
📋 核心要点
- 现有研究缺乏对LLM在动态环境中在线推理能力的深入评估,尤其是在信念需要持续更新的场景下。
- 论文提出将LLM的信念更新过程建模为折扣贝叶斯滤波器,通过折扣因子来量化LLM对历史信息的遗忘程度。
- 实验表明,LLM的信念更新类似于贝叶斯后验,但存在对旧证据的系统性折扣,且可以通过提示策略进行校准。
📝 摘要(中文)
大型语言模型(LLM)通过上下文学习展现出强大的少样本泛化能力,但它们在动态和随机环境中的推理过程仍然不透明。以往的研究主要集中在静态任务上,忽略了信念需要持续更新时的在线适应能力,而这对于LLM作为世界模型或智能体至关重要。本文引入了一个贝叶斯滤波框架来评估LLM中的在线推理。我们的概率探针套件涵盖了多元离散分布(如掷骰子)和连续分布(如高斯过程),其中真实参数随时间变化。我们发现,虽然LLM的信念更新类似于贝叶斯后验,但它们更准确地被描述为具有模型特定折扣因子(小于1)的指数遗忘滤波器。这揭示了对旧证据的系统性折扣,并且折扣程度在不同的模型架构之间差异显著。尽管固有的先验常常校准不当,但更新机制本身仍然是结构化的和有原则的。我们进一步在一个模拟智能体任务中验证了这些发现,并提出了有效的提示策略,以最小的计算成本重新校准先验。
🔬 方法详解
问题定义:论文旨在解决LLM在动态和随机环境中进行在线推理时,其信念更新机制不透明的问题。现有方法主要关注静态任务,忽略了LLM作为世界模型或智能体时,需要不断根据新信息更新信念的关键能力。现有方法无法有效评估LLM如何整合新信息并调整其内部信念。
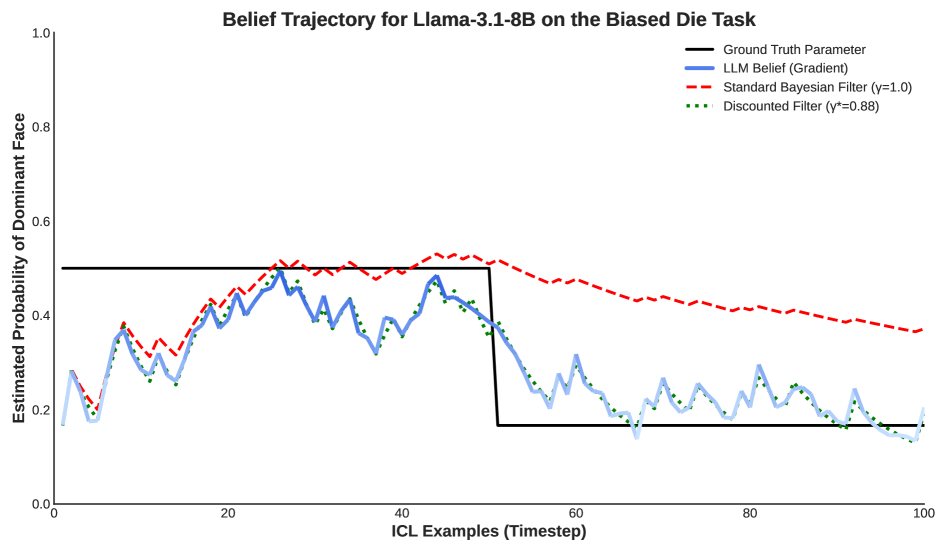
核心思路:论文的核心思路是将LLM的信念更新过程类比于贝叶斯滤波,并引入“折扣因子”来模拟LLM对历史信息的遗忘。通过观察LLM在不同概率分布下的信念更新行为,可以推断出其内在的折扣因子,从而理解其在线推理的机制。
技术框架:整体框架包括以下几个主要步骤:1) 设计概率探针套件,包括多元离散分布(如掷骰子)和连续分布(如高斯过程),其中真实参数随时间变化。2) 使用这些探针作为LLM的输入,观察LLM的信念更新过程。3) 将LLM的信念更新与标准的贝叶斯后验进行比较,并拟合一个指数遗忘滤波器,从而估计LLM的折扣因子。4) 在模拟智能体任务中验证这些发现,并探索提示策略来校准LLM的先验。
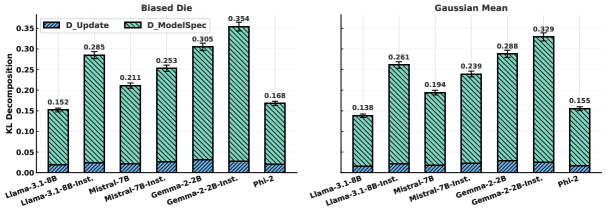
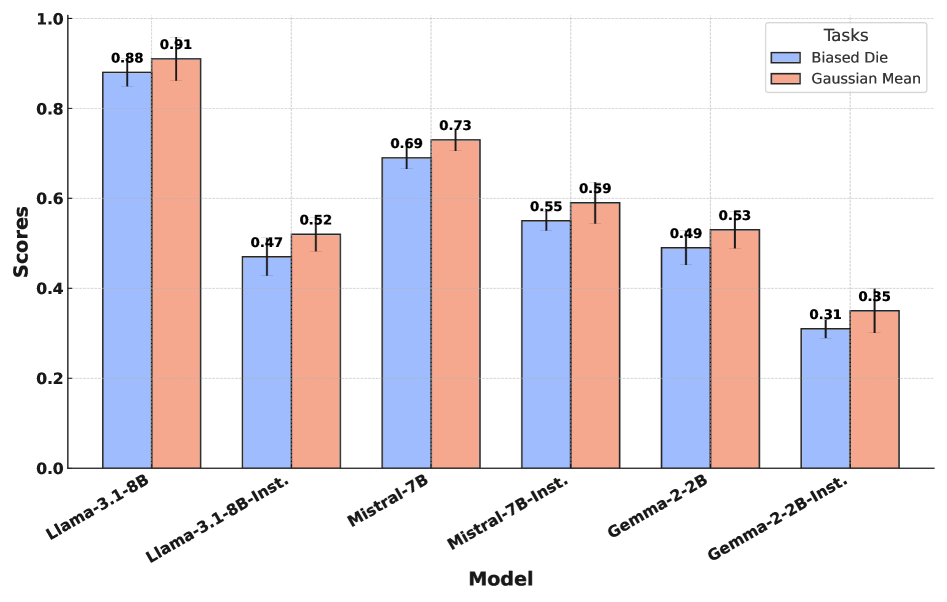
关键创新:最重要的技术创新点在于将LLM的信念更新过程建模为“折扣贝叶斯滤波器”。与传统的贝叶斯滤波相比,该模型引入了一个折扣因子,用于量化LLM对历史信息的遗忘程度。这使得研究人员能够更准确地描述LLM的在线推理行为,并发现其存在的系统性偏差。
关键设计:论文的关键设计包括:1) 概率探针套件的设计,需要覆盖不同类型的概率分布,并确保真实参数随时间变化。2) 指数遗忘滤波器的选择,该滤波器能够简洁地描述LLM对历史信息的遗忘行为。3) 提示策略的设计,旨在以最小的计算成本校准LLM的先验。具体参数设置和损失函数等细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM的信念更新类似于贝叶斯后验,但存在对旧证据的系统性折扣,折扣因子小于1。不同模型架构的折扣因子差异显著,表明不同模型对历史信息的遗忘程度不同。通过提示策略,可以有效校准LLM的先验,提高其在线推理的准确性。
🎯 应用场景
该研究成果可应用于提升LLM在动态环境中的决策能力,例如机器人导航、金融预测和智能对话系统。通过理解LLM的信念更新机制,可以设计更有效的提示策略,提高LLM的可靠性和适应性。此外,该研究也为评估和改进LLM作为世界模型的能力提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate strong few-shot generalization through in-context learning, yet their reasoning in dynamic and stochastic environments remains opaque. Prior studies mainly focus on static tasks and overlook the online adaptation required when beliefs must be continuously updated, which is a key capability for LLMs acting as world models or agents. We introduce a Bayesian filtering framework to evaluate online inference in LLMs. Our probabilistic probe suite spans both multivariate discrete distributions, such as dice rolls, and continuous distributions, such as Gaussian processes, where ground-truth parameters shift over time. We find that while LLM belief updates resemble Bayesian posteriors, they are more accurately characterized by an exponential forgetting filter with a model-specific discount factor smaller than one. This reveals systematic discounting of older evidence that varies significantly across model architectures. Although inherent priors are often miscalibrated, the updating mechanism itself remains structured and principled. We further validate these findings in a simulated agent task and propose prompting strategies that effectively recalibrate priors with minimal computational cost.