SoK: Understanding (New) Security Issues Across AI4Code Use Cases
作者: Qilong Wu, Taoran Li, Tianyang Zhou, Varun Chandrasekaran
分类: cs.CR, cs.AI
发布日期: 2025-12-20
备注: 39 pages, 19 figures
💡 一句话要点
综述AI4Code应用中的新型安全问题,并提出未来发展方向
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: AI4Code 代码安全 漏洞检测 代码生成 代码翻译 对抗攻击 安全基准
📋 核心要点
- 现有AI4Code系统在代码生成等方面取得进展,但安全性问题日益突出,如不安全输出和易受攻击等。
- 该研究通过分析现有AI4Code系统的安全漏洞,提出了在代码生成中嵌入安全实践等改进方向。
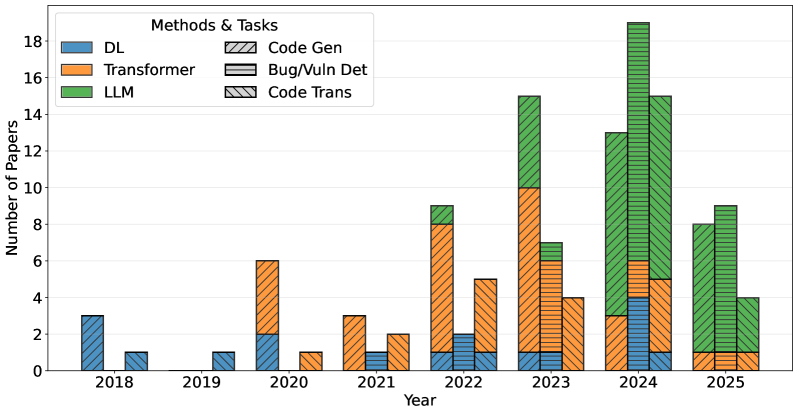
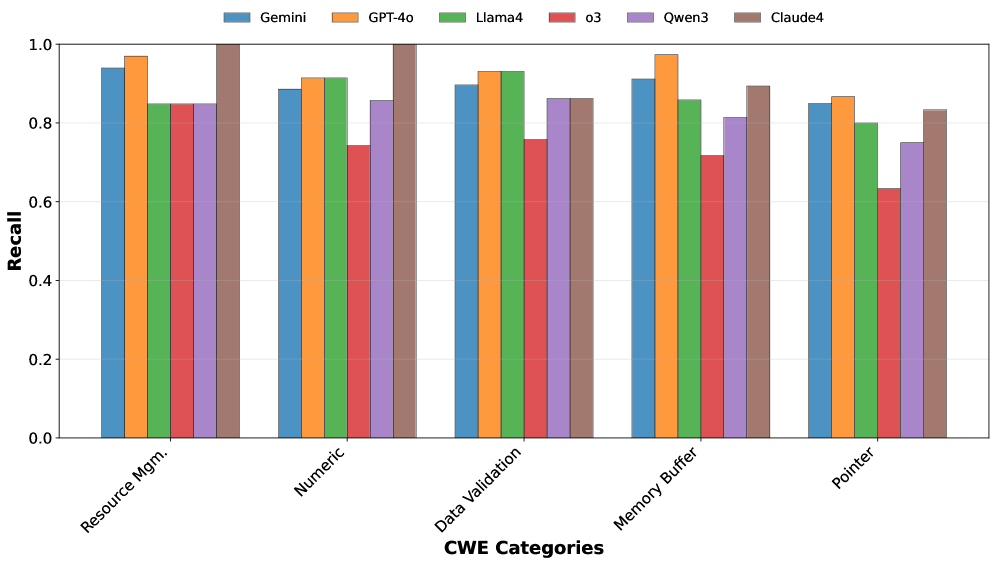
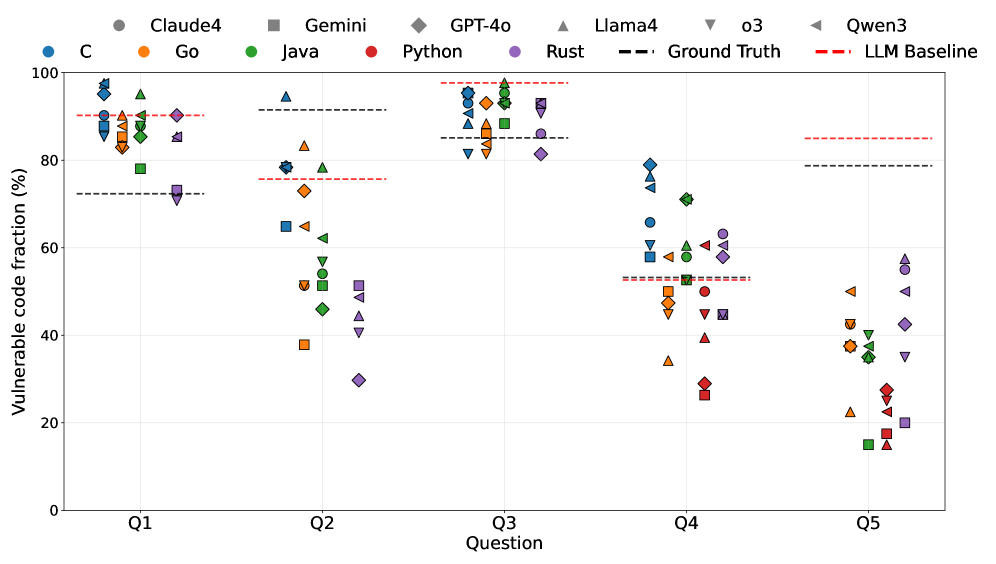
- 通过对六个模型的比较研究,揭示了代码生成、漏洞检测和代码翻译中存在的安全挑战。
📝 摘要(中文)
AI4Code系统正在重塑软件工程,诸如GitHub Copilot之类的工具加速了代码生成、翻译和漏洞检测。然而,伴随这些进步,安全风险仍然普遍存在:不安全的输出、有偏见的基准以及易受对抗性操纵的特性,都削弱了它们的可靠性。本SoK调查了AI4Code在三个核心应用中的安全态势,识别出重复出现的差距:Python和玩具问题在基准测试中占据主导地位、缺乏标准化的安全数据集、评估中的数据泄露以及脆弱的对抗鲁棒性。对六个最先进模型的比较研究说明了这些挑战:不安全模式持续存在于代码生成中,漏洞检测对语义保持攻击非常脆弱,微调常常使安全目标错位,代码翻译产生不均衡的安全效益。通过分析,我们提炼出三个前进方向:在代码生成中嵌入默认安全实践,构建强大而全面的检测基准,以及利用翻译作为增强语言安全性的途径。我们呼吁转向安全优先的AI4Code,将漏洞缓解和鲁棒性嵌入到整个开发生命周期中。
🔬 方法详解
问题定义:论文旨在解决AI4Code系统在代码生成、漏洞检测和代码翻译等应用中存在的安全问题。现有方法存在诸多痛点,例如:基准测试主要集中在Python和简单问题上,缺乏标准化的安全数据集,评估过程中存在数据泄露,以及对抗鲁棒性较差等。这些问题导致AI4Code系统容易产生不安全的代码,难以有效检测漏洞,并且容易受到恶意攻击。
核心思路:论文的核心思路是全面分析AI4Code系统的安全风险,并提出改进方向,从而推动开发更安全可靠的AI4Code工具。具体而言,论文通过对现有模型的安全漏洞进行分析,总结出三个前进方向:在代码生成中嵌入默认安全实践,构建强大而全面的检测基准,以及利用翻译作为增强语言安全性的途径。
技术框架:该论文采用了一种系统化的研究方法,首先对AI4Code的三个核心应用(代码生成、漏洞检测和代码翻译)进行综述,然后通过对六个最先进的模型进行比较研究,揭示了这些模型在安全性方面存在的挑战。最后,基于分析结果,论文提出了三个改进方向,并呼吁转向安全优先的AI4Code开发模式。
关键创新:该论文的主要创新在于对AI4Code安全问题进行了全面的分析和总结,并提出了具体的改进方向。与现有研究相比,该论文不仅关注了模型的性能,还深入探讨了模型的安全性,并提出了在代码生成中嵌入默认安全实践等创新性的解决方案。
关键设计:论文的关键设计在于对六个最先进的AI4Code模型进行了比较研究,通过分析这些模型在代码生成、漏洞检测和代码翻译等任务中的表现,揭示了它们在安全性方面存在的不足。此外,论文还提出了构建强大而全面的检测基准的建议,这对于评估AI4Code系统的安全性至关重要。
🖼️ 关键图片
📊 实验亮点
论文通过对六个最先进的AI4Code模型进行比较研究,发现不安全模式持续存在于代码生成中,漏洞检测对语义保持攻击非常脆弱,微调常常使安全目标错位,代码翻译产生不均衡的安全效益。这些发现突出了现有AI4Code系统在安全性方面存在的不足。
🎯 应用场景
该研究成果可应用于软件开发工具的安全增强,例如改进代码自动生成工具,使其默认生成更安全的代码。此外,该研究还可用于构建更可靠的漏洞检测系统,以及开发更安全的跨语言代码翻译工具。最终目标是提升整个软件开发生命周期的安全性。
📄 摘要(原文)
AI-for-Code (AI4Code) systems are reshaping software engineering, with tools like GitHub Copilot accelerating code generation, translation, and vulnerability detection. Alongside these advances, however, security risks remain pervasive: insecure outputs, biased benchmarks, and susceptibility to adversarial manipulation undermine their reliability. This SoK surveys the landscape of AI4Code security across three core applications, identifying recurring gaps: benchmark dominance by Python and toy problems, lack of standardized security datasets, data leakage in evaluation, and fragile adversarial robustness. A comparative study of six state-of-the-art models illustrates these challenges: insecure patterns persist in code generation, vulnerability detection is brittle to semantic-preserving attacks, fine-tuning often misaligns security objectives, and code translation yields uneven security benefits. From this analysis, we distill three forward paths: embedding secure-by-default practices in code generation, building robust and comprehensive detection benchmarks, and leveraging translation as a route to security-enhanced languages. We call for a shift toward security-first AI4Code, where vulnerability mitigation and robustness are embedded throughout the development life cycle.