Asynchronous Pipeline Parallelism for Real-Time Multilingual Lip Synchronization in Video Communication Systems
作者: Eren Caglar, Amirkia Rafiei Oskooei, Mehmet Kutanoglu, Mustafa Keles, Mehmet S. Aktas
分类: cs.MM, cs.AI, cs.CV, cs.DC, cs.NI
发布日期: 2025-12-20
备注: Accepted to IEEE Big Data 2025, AIDE4IoT Workshop. Copyright \c{opyright} 2025 IEEE
💡 一句话要点
提出异步流水线并行Transformer框架,用于实时多语种唇动同步
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 唇动同步 多语种翻译 异步并行 Transformer 实时通信
📋 核心要点
- 现有实时多语种唇动同步系统延迟高、资源利用率低,难以满足实际应用需求。
- 提出基于异步流水线并行的Transformer框架,通过消息队列解耦模块,实现并发执行。
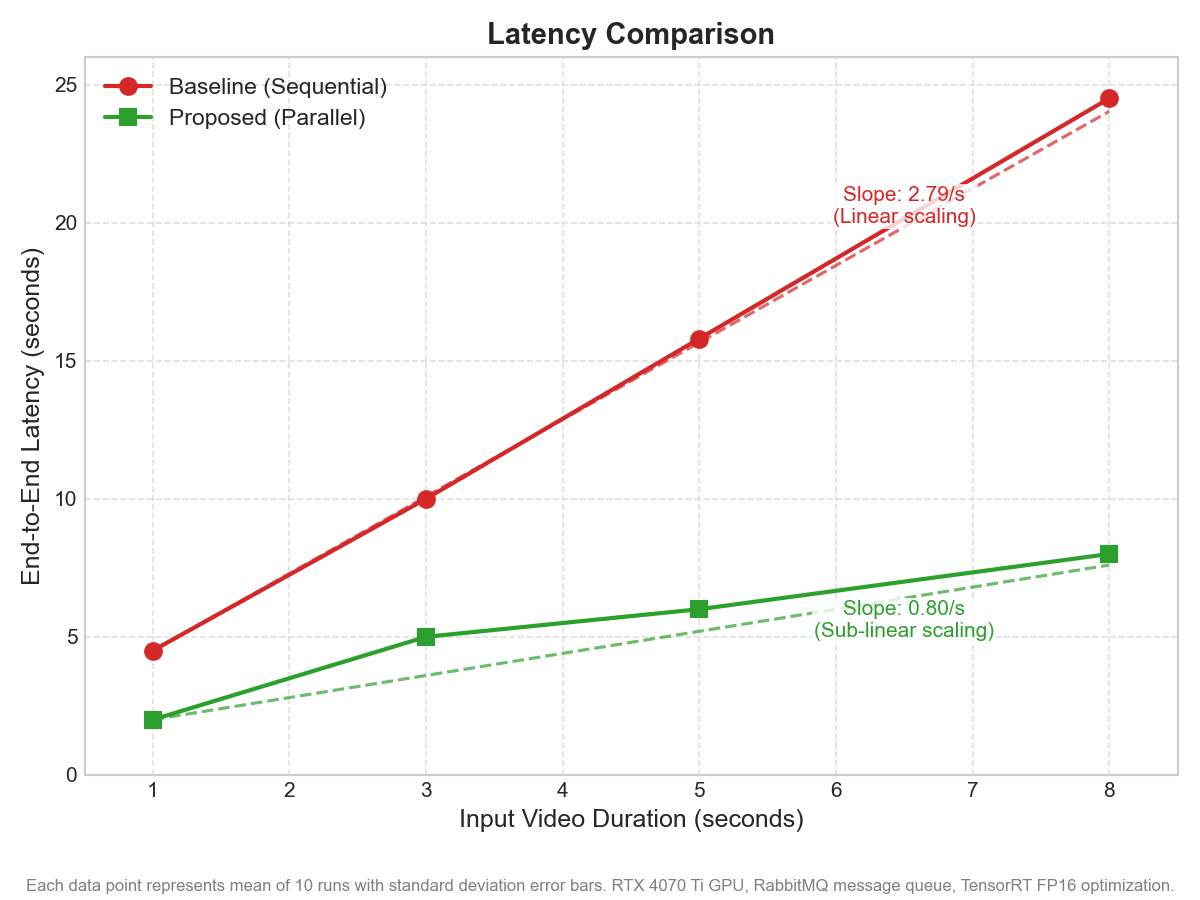
- 实验表明,该架构显著降低了端到端延迟,提高了同步稳定性和资源利用率。
📝 摘要(中文)
本文提出了一种并行异步的Transformer框架,旨在为实时视频会议系统提供高效准确的多语种唇动同步。该架构集成了翻译、语音处理和唇动同步模块,采用流水线并行设计,通过基于消息队列的解耦实现模块的并发执行,与串行方法相比,端到端延迟最多可降低3.1倍。为了提高计算效率和吞吐量,通过底层图编译、混合精度量化和硬件加速内核融合来优化每个模块的推理工作流程。这些优化在保持模型精度和视觉质量的同时,显著提高了效率。此外,上下文自适应静音检测组件在语义连贯的边界处分割输入语音流,从而提高了跨语言的翻译一致性和时间对齐。实验结果表明,所提出的并行架构在处理速度、同步稳定性和资源利用率方面优于传统的串行流水线。模块化、面向消息的设计使这项工作适用于资源受限的物联网通信场景,包括远程医疗、多语种信息亭和远程协助系统。总而言之,这项工作推进了下一代AIoT系统的低延迟、资源高效的多模态通信框架的开发。
🔬 方法详解
问题定义:论文旨在解决实时视频通信系统中多语种唇动同步的延迟问题。现有方法通常采用串行处理方式,即先翻译、再进行语音处理,最后进行唇动同步,导致端到端延迟较高,难以满足实时性要求。此外,现有方法在资源利用率方面也存在不足,难以在资源受限的设备上部署。
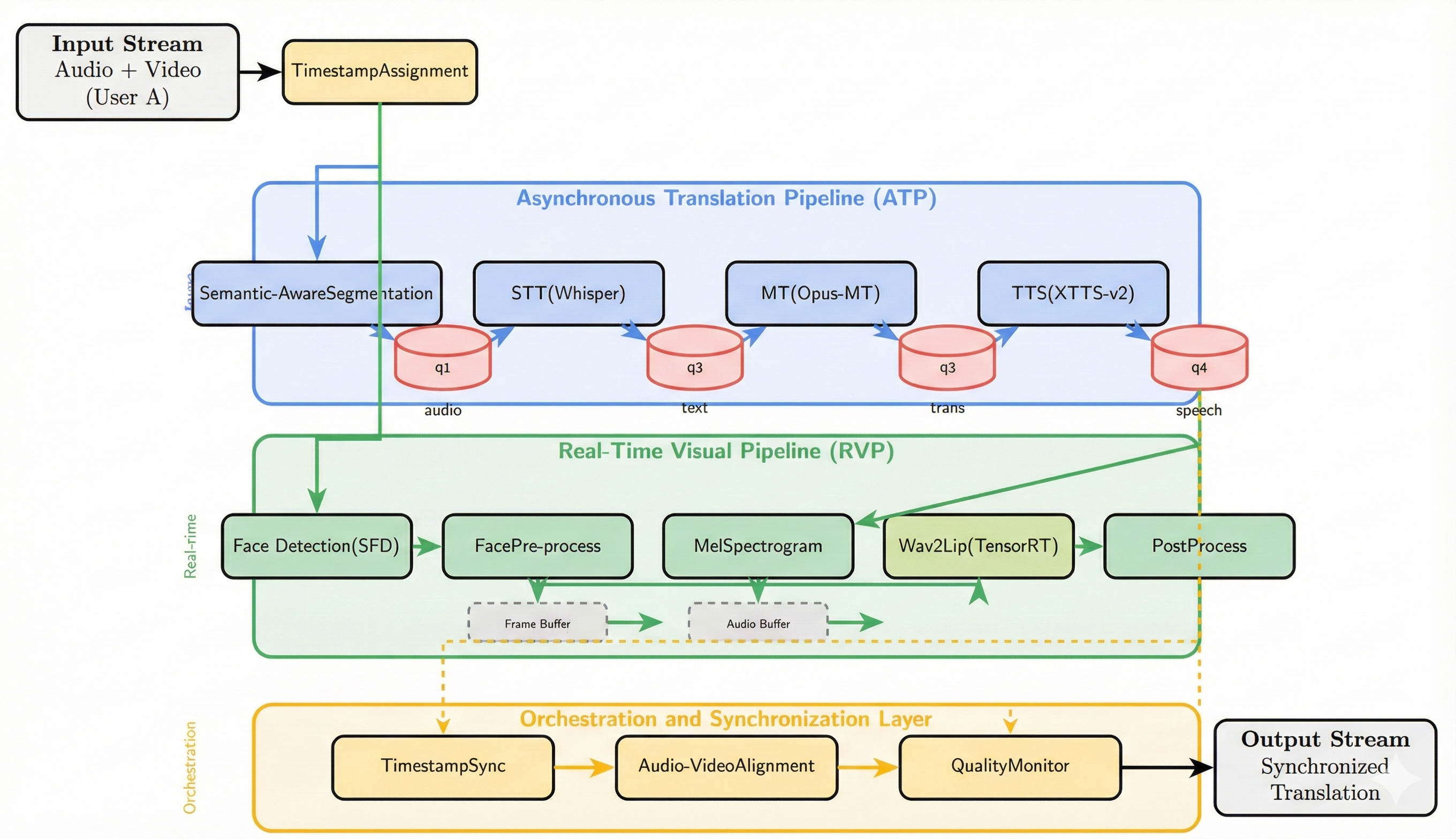
核心思路:论文的核心思路是采用异步流水线并行的方式来处理多语种唇动同步任务。通过将翻译、语音处理和唇动同步模块解耦,并利用消息队列进行通信,使得各个模块可以并发执行,从而降低端到端延迟。此外,论文还通过优化每个模块的推理过程,提高计算效率和吞吐量。
技术框架:整体架构包含三个主要模块:翻译模块、语音处理模块和唇动同步模块。这些模块通过消息队列进行异步通信,形成一个流水线。首先,翻译模块将源语言的语音翻译成目标语言的文本。然后,语音处理模块将目标语言的文本转换成语音。最后,唇动同步模块根据目标语言的语音生成相应的唇动动画。为了提高效率,每个模块都进行了优化,包括底层图编译、混合精度量化和硬件加速内核融合。
关键创新:论文的关键创新在于提出了异步流水线并行的架构,以及针对每个模块的优化方法。异步流水线并行架构使得各个模块可以并发执行,从而显著降低了端到端延迟。针对每个模块的优化方法,如底层图编译、混合精度量化和硬件加速内核融合,提高了计算效率和吞吐量。此外,上下文自适应静音检测组件也提高了翻译一致性和时间对齐。
关键设计:论文中使用了Transformer模型作为翻译和唇动同步模块的基础。消息队列的选择对系统的性能有重要影响,论文可能采用了某种特定的消息队列技术。混合精度量化方案的选择也对模型的精度和效率有影响。此外,硬件加速内核融合的具体实现方式也是一个关键的技术细节,但论文摘要中没有详细说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的并行架构在处理速度上优于传统的串行流水线,端到端延迟最多可降低3.1倍。此外,该架构在同步稳定性和资源利用率方面也表现出优势。通过底层图编译、混合精度量化和硬件加速内核融合等优化手段,在保持模型精度和视觉质量的同时,显著提高了效率。
🎯 应用场景
该研究成果可应用于多种实时多语种通信场景,如远程医疗、多语种信息亭、远程协助系统等。通过降低延迟、提高同步稳定性和资源利用率,可以提升用户体验,促进跨语言交流。未来,该技术有望在AIoT系统中发挥更大的作用,例如智能家居、智能交通等。
📄 摘要(原文)
This paper introduces a parallel and asynchronous Transformer framework designed for efficient and accurate multilingual lip synchronization in real-time video conferencing systems. The proposed architecture integrates translation, speech processing, and lip-synchronization modules within a pipeline-parallel design that enables concurrent module execution through message-queue-based decoupling, reducing end-to-end latency by up to 3.1 times compared to sequential approaches. To enhance computational efficiency and throughput, the inference workflow of each module is optimized through low-level graph compilation, mixed-precision quantization, and hardware-accelerated kernel fusion. These optimizations provide substantial gains in efficiency while preserving model accuracy and visual quality. In addition, a context-adaptive silence-detection component segments the input speech stream at semantically coherent boundaries, improving translation consistency and temporal alignment across languages. Experimental results demonstrate that the proposed parallel architecture outperforms conventional sequential pipelines in processing speed, synchronization stability, and resource utilization. The modular, message-oriented design makes this work applicable to resource-constrained IoT communication scenarios including telemedicine, multilingual kiosks, and remote assistance systems. Overall, this work advances the development of low-latency, resource-efficient multimodal communication frameworks for next-generation AIoT systems.