MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
作者: Sirui Li, Wangyue Lu, Xiaorui Shi, Ke Weng, Haozhe Sun, Minghe Yu, Tiancheng Zhang, Ge Yu, Hengyu Liu, Lun Du
分类: cs.AI, cs.LO
发布日期: 2025-12-20
💡 一句话要点
提出MSC-180基准,用于评估LLM在数学分支上的自动定理证明能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动定理证明 大型语言模型 数学推理 基准数据集 形式验证
📋 核心要点
- 现有基于LLM的定理证明器在数学推理中存在领域覆盖范围有限和泛化能力弱等局限性。
- 提出MSC-180基准,包含180个覆盖不同数学分支、难度各异的形式验证问题。
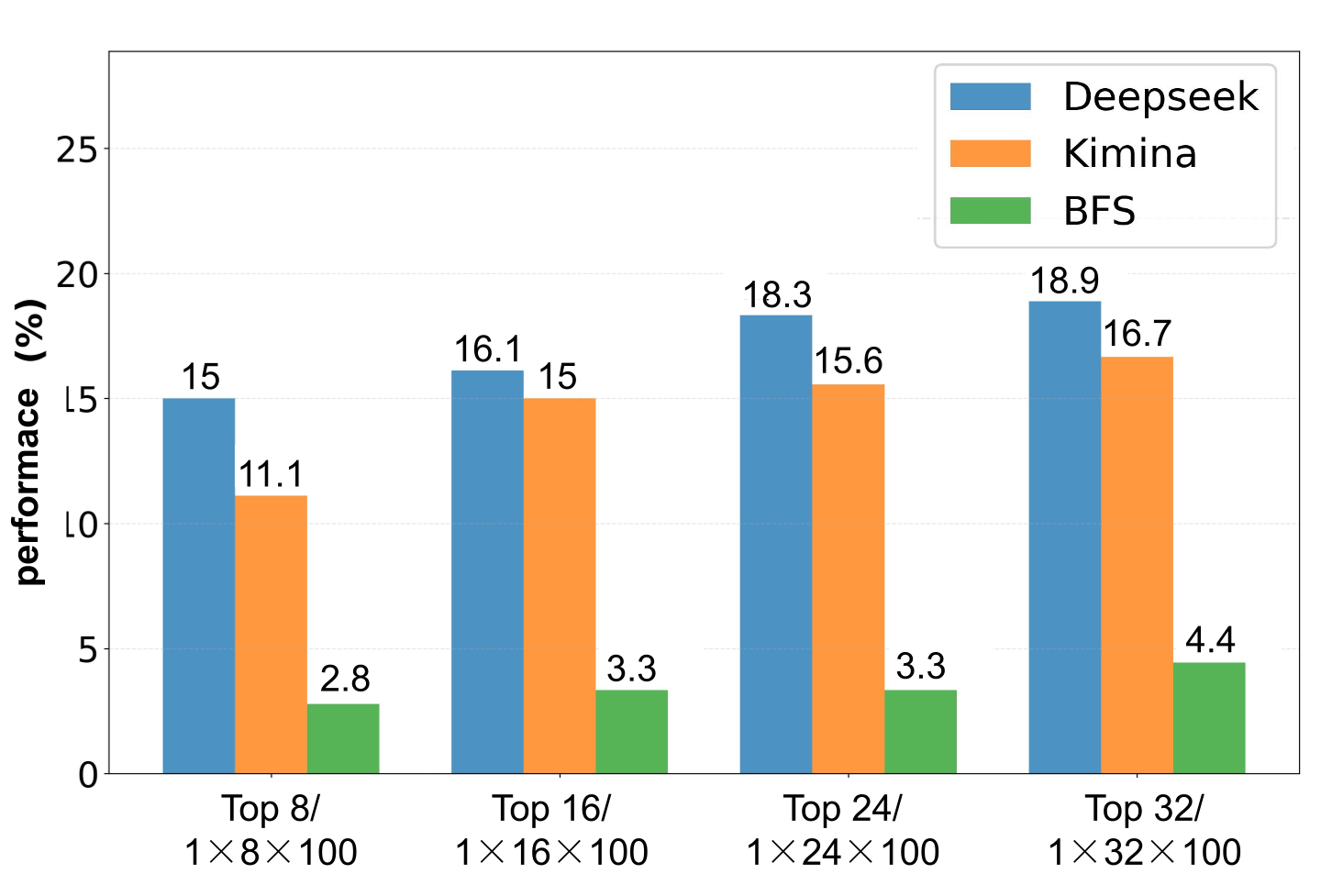
- 实验表明,现有LLM在MSC-180上的表现不佳,存在显著的领域偏差和难度差距。
📝 摘要(中文)
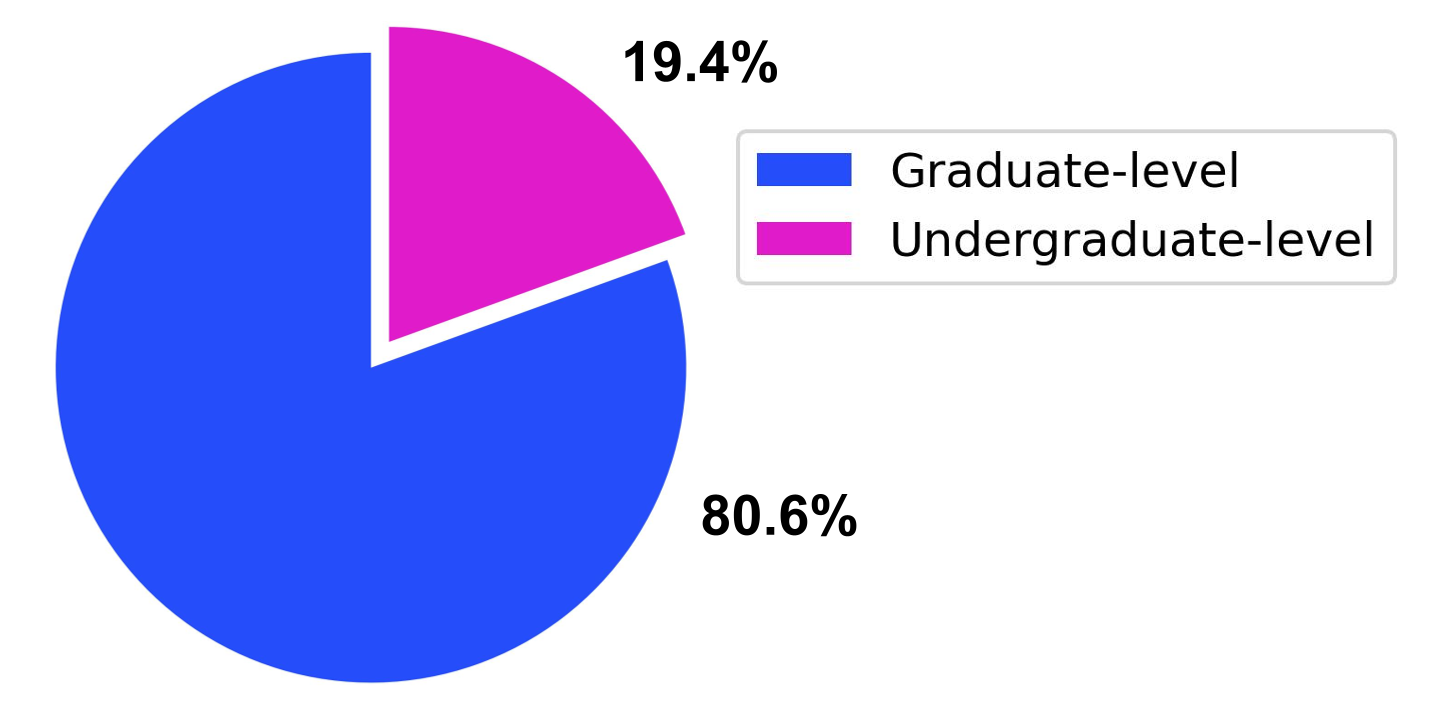
本文提出了MSC-180,一个基于MSC2020数学学科分类的自动定理证明评估基准。该基准包含180个形式验证问题,覆盖60个数学分支,难度从本科到研究生级别。每个问题都经过领域专家的多轮验证和完善,以确保形式上的准确性。在pass@32设置下,对最先进的基于LLM的定理证明器的评估表明,最佳模型的总体通过率仅为18.89%,存在显著的领域偏差(最大领域覆盖率41.7%)和难度差距(研究生级别问题的通过率显著降低)等问题。为了进一步量化数学领域之间的性能差异,引入了变异系数(CV)作为评估指标。观察到的CV值比统计高变异性阈值高4-6倍,表明这些模型仍然依赖于训练语料库中的模式匹配,而不是拥有可转移的推理机制和系统的泛化能力。MSC-180及其多维评估框架为推动下一代具有真正数学推理能力的AI系统的发展提供了一个判别性和系统性的基准。
🔬 方法详解
问题定义:论文旨在解决现有基于大型语言模型(LLM)的自动定理证明器在数学推理方面存在的局限性,具体表现为领域覆盖范围不足和泛化能力较弱。现有的定理证明器往往只在特定数学领域表现良好,难以应对更广泛的数学问题,并且容易受到训练数据的影响,缺乏真正的推理能力。
核心思路:论文的核心思路是构建一个更具挑战性和代表性的基准数据集MSC-180,该数据集覆盖了更广泛的数学领域,并且包含了不同难度的题目,从而能够更全面地评估自动定理证明器的性能。通过在该基准上进行评估,可以更准确地了解现有方法的优缺点,并为未来的研究提供指导。
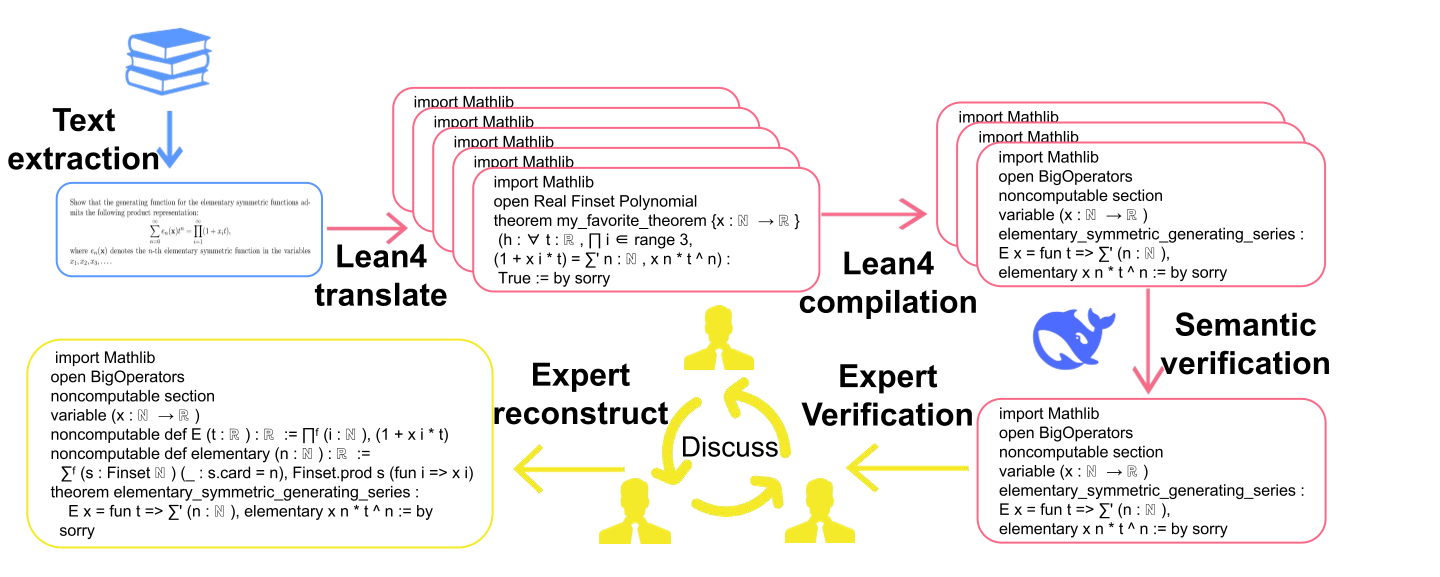
技术框架:MSC-180基准的构建流程主要包括以下几个阶段:首先,基于MSC2020数学学科分类,选取了60个不同的数学分支。然后,在每个分支中,选取了3个难度不同的问题,难度范围从本科到研究生级别。每个问题都经过领域专家的多轮验证和完善,以确保形式上的准确性。最后,使用pass@32和变异系数(CV)等指标对现有的LLM进行评估。
关键创新:该论文的关键创新在于提出了MSC-180基准,该基准具有以下几个优点:1)覆盖范围广,包含了60个不同的数学分支;2)难度多样,包含了从本科到研究生级别的题目;3)形式准确,每个问题都经过领域专家的多轮验证和完善。此外,论文还引入了变异系数(CV)作为评估指标,可以更全面地评估自动定理证明器的性能。
关键设计:MSC-180基准的关键设计在于其问题的选择和验证过程。为了确保基准的代表性,论文基于MSC2020数学学科分类,选取了60个不同的数学分支。为了确保问题的形式准确性,每个问题都经过领域专家的多轮验证和完善。此外,论文还使用了pass@32作为主要的评估指标,该指标衡量了模型在32次尝试中至少成功一次的概率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有最先进的LLM在MSC-180上的总体通过率仅为18.89%。领域覆盖率最高仅为41.7%,且研究生级别问题的通过率显著低于本科级别。变异系数(CV)值比统计高变异性阈值高4-6倍,表明模型依赖于模式匹配,缺乏可转移的推理能力。
🎯 应用场景
该研究成果可应用于开发更强大的自动定理证明器,从而在数学、计算机科学等领域实现更可靠的 formal verification。 此外,该基准可以促进AI在科学发现和工程设计中的应用,例如自动验证算法的正确性,或辅助设计更优化的数学模型。
📄 摘要(原文)
Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.