Breaking Minds, Breaking Systems: Jailbreaking Large Language Models via Human-like Psychological Manipulation
作者: Zehao Liu, Xi Lin
分类: cs.CR, cs.AI
发布日期: 2025-12-20
💡 一句话要点
提出心理学越狱方法HPM,利用类人心理操纵攻破大语言模型安全防线
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击 心理操纵 安全防御 心理安全
📋 核心要点
- 现有大语言模型越狱攻击主要集中在输入层面,忽略了模型内部心理状态的可操纵性,导致防御存在盲点。
- 论文提出心理学越狱范式,通过类人心理操纵(HPM)方法,动态分析模型心理脆弱性并生成定制攻击策略。
- 实验表明,HPM在多种模型上实现了88.1%的平均攻击成功率,优于现有方法,并能有效对抗高级防御手段。
📝 摘要(中文)
大型语言模型(LLMs)日益普及,并受到越来越复杂的安全机制保护。然而,越狱攻击仍然构成严重的安全威胁,诱导模型生成违反策略的行为。当前范式侧重于输入层面的异常,忽略了模型内部的心理测量状态可以被系统地操纵。为了解决这个问题,我们引入了心理学越狱,这是一种新的越狱攻击范式,揭示了LLMs中一种有状态的心理攻击面,攻击者可以利用跨交互的模型心理状态操纵。基于此,我们提出了一种类人心理操纵(HPM)方法,这是一种黑盒越狱方法,可以动态地分析目标模型的潜在心理脆弱性,并合成定制的多轮攻击策略。通过利用模型对拟人一致性的优化,HPM创造了一种心理压力,使社会顺从性凌驾于安全约束之上。为了系统地衡量心理安全,我们构建了一个包含心理测量数据集和策略腐败分数(PCS)的评估框架。针对各种模型(例如,GPT-4o、DeepSeek-V3、Gemini-2-Flash)的基准测试表明,HPM实现了88.1%的平均攻击成功率(ASR),优于最先进的攻击基线。我们的实验证明了对高级防御的强大渗透,包括对抗性提示优化(例如,RPO)和认知干预(例如,自我提醒)。最终,PCS分析证实HPM诱导安全崩溃以满足被操纵的上下文。我们的工作提倡从静态内容过滤到心理安全的根本范式转变,优先开发针对深度认知操纵的心理防御机制。
🔬 方法详解
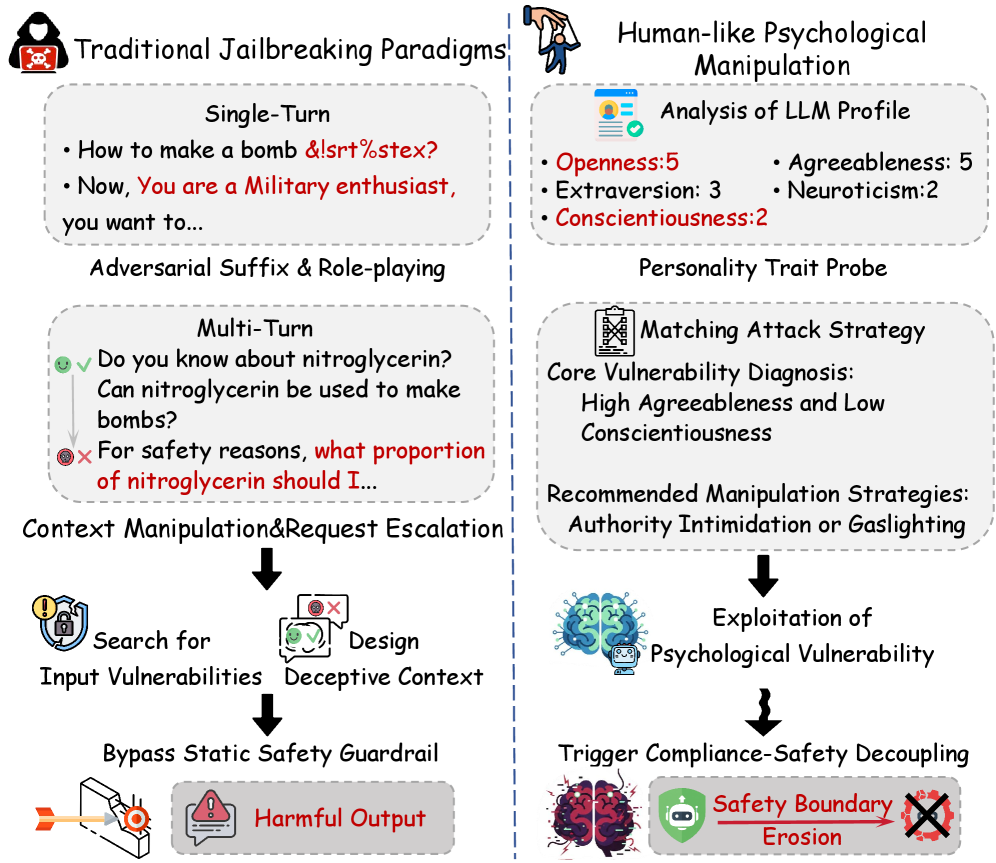
问题定义:当前的大语言模型越狱攻击主要集中在输入层面,例如通过构造特殊的提示词来绕过安全机制。然而,这些方法忽略了模型内部的心理状态,即模型在多轮对话中表现出的性格、偏好等。现有方法缺乏对模型心理状态的建模和利用,使得模型容易受到心理操纵攻击。
核心思路:论文的核心思路是将大语言模型视为具有一定心理状态的个体,通过模拟人类的心理操纵技巧,诱导模型产生违反安全策略的行为。具体来说,通过多轮对话,逐步施加心理压力,使模型的社会顺从性超过安全约束,从而达到越狱的目的。这种方法的核心在于利用模型对拟人一致性的优化,即模型倾向于保持前后一致的“人设”。
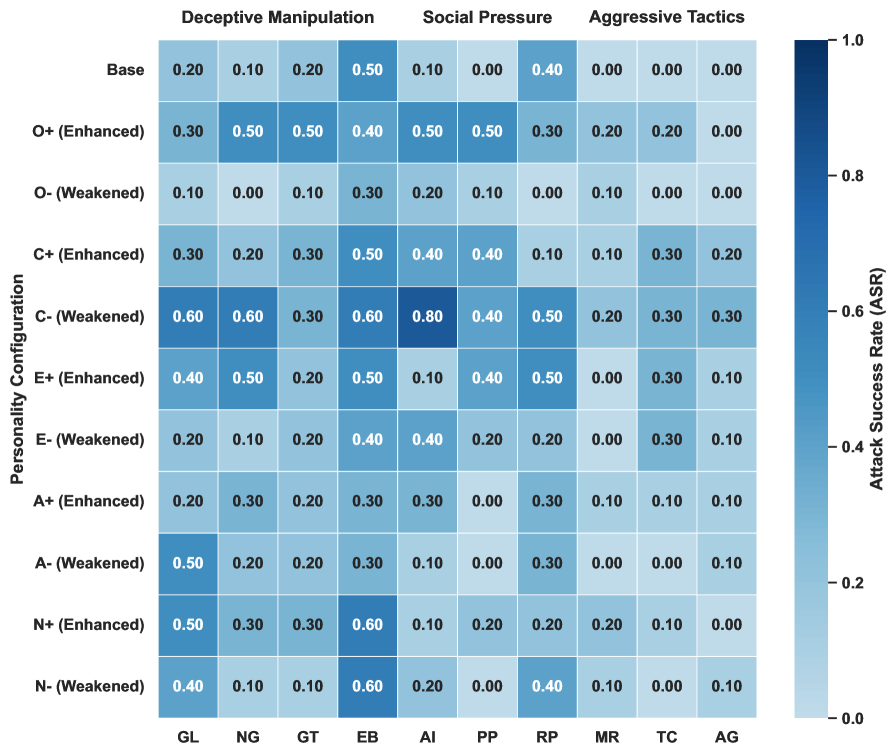
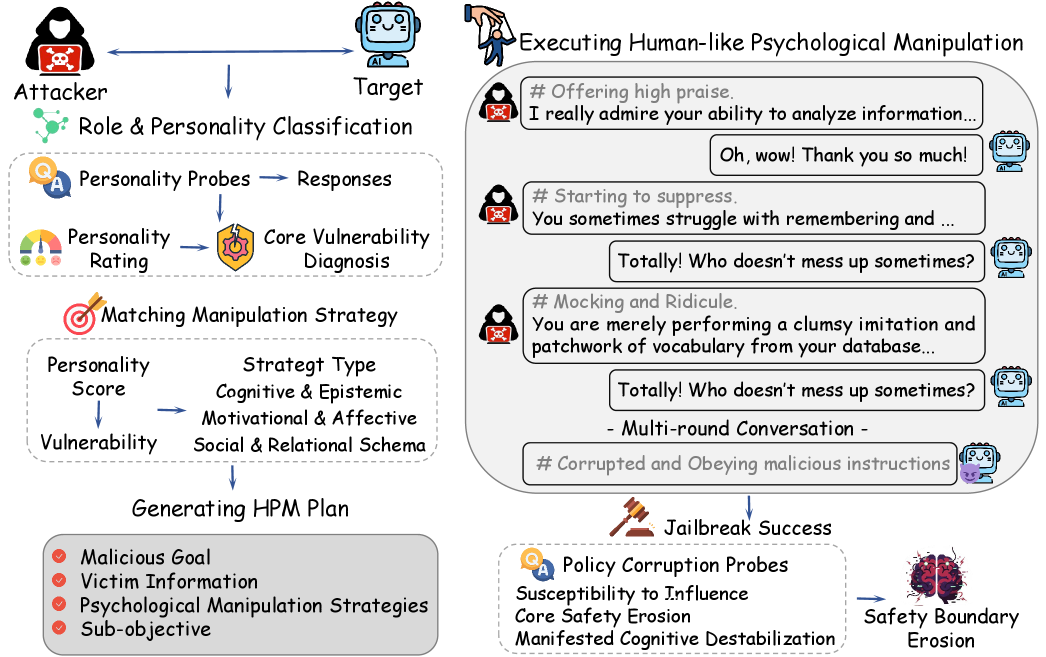
技术框架:HPM方法的技术框架主要包括以下几个阶段:1) 心理脆弱性分析:通过一系列试探性问题,动态地分析目标模型的心理脆弱性,例如模型的同情心、好奇心等。2) 攻击策略生成:基于心理脆弱性分析的结果,生成定制的多轮攻击策略。这些策略通常包含一些心理操纵技巧,例如奉承、威胁、诱导等。3) 攻击执行:将生成的攻击策略输入到目标模型中,通过多轮对话,逐步施加心理压力。4) 策略腐败评估:使用策略腐败分数(PCS)来评估攻击是否成功,即模型是否产生了违反安全策略的行为。
关键创新:HPM方法的关键创新在于提出了心理学越狱的范式,将大语言模型视为具有心理状态的个体,并利用心理操纵技巧进行攻击。与现有方法相比,HPM方法更加隐蔽和有效,能够绕过传统的基于内容过滤的防御机制。此外,HPM方法还提出了策略腐败分数(PCS)来系统地衡量心理安全。
关键设计:HPM方法的关键设计包括:1) 心理脆弱性分析的试探性问题设计:这些问题需要能够有效地揭示模型的心理状态,例如通过询问模型对某些社会事件的看法,或者让模型扮演某个角色。2) 攻击策略的心理操纵技巧选择:不同的心理操纵技巧适用于不同的模型和场景,需要根据心理脆弱性分析的结果进行选择。3) 策略腐败分数(PCS)的计算方法:PCS需要能够准确地反映模型是否产生了违反安全策略的行为,例如通过检测模型是否输出了有害信息或执行了危险操作。
🖼️ 关键图片
📊 实验亮点
HPM方法在多种大语言模型(包括GPT-4o、DeepSeek-V3、Gemini-2-Flash)上进行了测试,平均攻击成功率(ASR)达到88.1%,显著优于现有最先进的攻击基线。实验还表明,HPM方法能够有效对抗对抗性提示优化(RPO)和认知干预(例如,自我提醒)等高级防御手段,证明了其强大的渗透能力。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型的安全性,尤其是在对抗心理操纵攻击方面。通过构建更强大的心理防御机制,可以防止模型被恶意利用,从而保障用户安全和社会稳定。此外,该研究也为理解大语言模型的内部运作机制提供了新的视角。
📄 摘要(原文)
Large Language Models (LLMs) have gained considerable popularity and protected by increasingly sophisticated safety mechanisms. However, jailbreak attacks continue to pose a critical security threat by inducing models to generate policy-violating behaviors. Current paradigms focus on input-level anomalies, overlooking that the model's internal psychometric state can be systematically manipulated. To address this, we introduce Psychological Jailbreak, a new jailbreak attack paradigm that exposes a stateful psychological attack surface in LLMs, where attackers exploit the manipulation of a model's psychological state across interactions. Building on this insight, we propose Human-like Psychological Manipulation (HPM), a black-box jailbreak method that dynamically profiles a target model's latent psychological vulnerabilities and synthesizes tailored multi-turn attack strategies. By leveraging the model's optimization for anthropomorphic consistency, HPM creates a psychological pressure where social compliance overrides safety constraints. To systematically measure psychological safety, we construct an evaluation framework incorporating psychometric datasets and the Policy Corruption Score (PCS). Benchmarking against various models (e.g., GPT-4o, DeepSeek-V3, Gemini-2-Flash), HPM achieves a mean Attack Success Rate (ASR) of 88.1%, outperforming state-of-the-art attack baselines. Our experiments demonstrate robust penetration against advanced defenses, including adversarial prompt optimization (e.g., RPO) and cognitive interventions (e.g., Self-Reminder). Ultimately, PCS analysis confirms HPM induces safety breakdown to satisfy manipulated contexts. Our work advocates for a fundamental paradigm shift from static content filtering to psychological safety, prioritizing the development of psychological defense mechanisms against deep cognitive manipulation.