Attention Distance: A Novel Metric for Directed Fuzzing with Large Language Models
作者: Wang Bin, Ao Yang, Kedan Li, Aofan Liu, Hui Li, Guibo Luo, Weixiang Huang, Yan Zhuang
分类: cs.SE, cs.AI
发布日期: 2025-12-19
备注: Accepted to ICSE 2026 Research Track
🔗 代码/项目: GITHUB
💡 一句话要点
提出注意力距离以解决现有模糊测试中的逻辑关系缺失问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模糊测试 软件安全 漏洞检测 大型语言模型 注意力机制
📋 核心要点
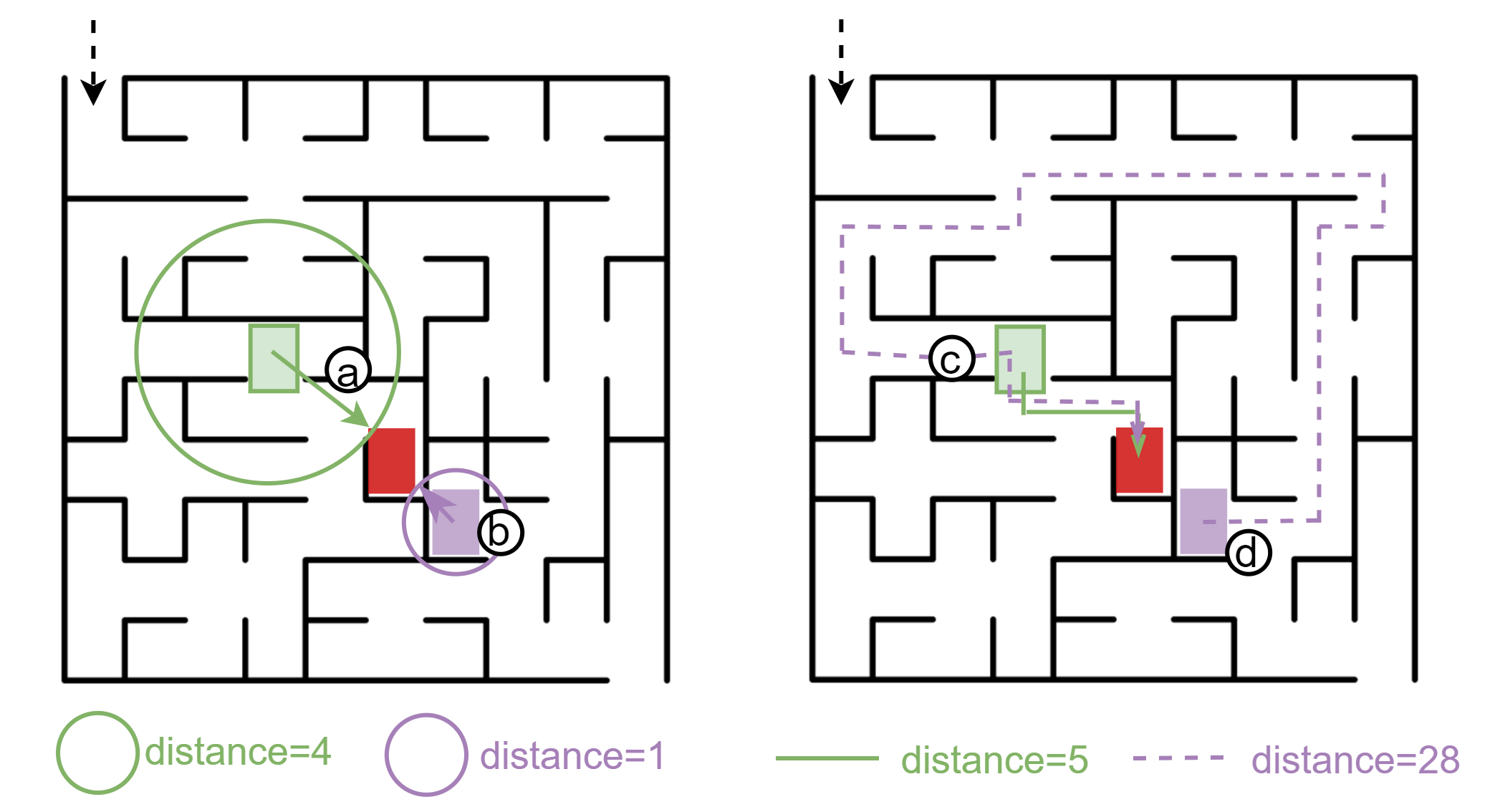
- 现有定向灰盒模糊测试方法仅关注物理距离,忽略了代码段之间的逻辑关系,导致测试效果不佳。
- 本文提出注意力距离,通过大型语言模型的上下文分析计算代码元素间的注意力分数,揭示其内在联系。
- 在38个真实漏洞重现实验中,使用注意力距离的测试效率平均提升3.43倍,相较于DAFL和WindRanger分别提升2.89倍和7.13倍。
📝 摘要(中文)
在软件安全测试领域,定向灰盒模糊测试(DGF)因其高效的目标定位和优秀的检测性能而受到广泛关注。然而,现有方法仅测量种子执行路径与目标位置之间的物理距离,忽视了代码段之间的逻辑关系。这种遗漏可能导致在复杂二进制文件中产生冗余或误导性的指导,从而削弱DGF在实际应用中的有效性。为了解决这一问题,本文提出了注意力距离这一新颖度量,利用大型语言模型的上下文分析计算代码元素之间的注意力分数,揭示其内在联系。在相同的AFLGo配置下,仅通过替换距离度量,本文在38个真实漏洞重现实验中实现了平均3.43倍的测试效率提升。与最先进的定向模糊测试工具DAFL和WindRanger相比,本文方法分别实现了2.89倍和7.13倍的性能提升。所有相关代码和数据集已公开可用。
🔬 方法详解
问题定义:本文旨在解决现有定向灰盒模糊测试中对物理距离的依赖,导致逻辑关系缺失的问题。这种缺失在复杂二进制文件中可能导致冗余或误导性的测试指导,影响DGF的实际效果。
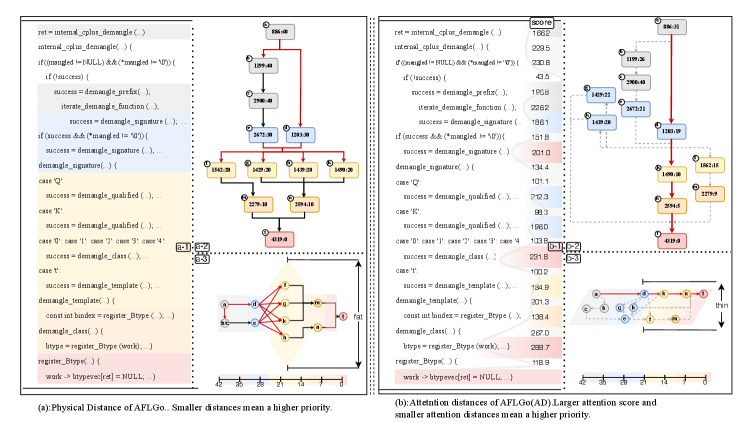
核心思路:论文提出的注意力距离度量通过大型语言模型分析代码元素之间的上下文关系,计算注意力分数,从而揭示代码段之间的内在逻辑联系。这样的设计能够更准确地指导模糊测试,提高漏洞检测的效率。
技术框架:整体架构包括数据预处理、注意力距离计算、模糊测试执行等主要模块。首先,对代码进行解析和特征提取,然后利用大型语言模型计算代码元素间的注意力分数,最后将这些分数用于指导模糊测试过程。
关键创新:最重要的创新点在于引入了注意力距离这一新度量,替代传统的物理距离,使得模糊测试能够更好地捕捉代码逻辑关系。这一方法与现有的基于物理距离的模糊测试方法本质上不同,能够显著提升测试效果。
关键设计:在实现过程中,注意力距离的计算依赖于大型语言模型的预训练权重,确保了上下文分析的准确性。参数设置上,保持了AFLGo的原有配置,仅替换了距离度量,确保了实验的公平性和可比性。损失函数和网络结构的选择也经过精心设计,以优化注意力分数的计算。
🖼️ 关键图片
📊 实验亮点
实验结果显示,使用注意力距离的模糊测试在38个真实漏洞重现实验中实现了平均3.43倍的测试效率提升。与最先进的定向模糊测试工具DAFL和WindRanger相比,本文方法分别提升了2.89倍和7.13倍,验证了注意力距离的有效性和优越性。
🎯 应用场景
该研究的潜在应用领域包括软件安全测试、漏洞检测和代码分析等。通过提高模糊测试的效率,能够更快速地发现软件中的安全漏洞,从而提升软件的安全性和可靠性。未来,该方法有望在更广泛的安全测试场景中得到应用,推动软件安全领域的发展。
📄 摘要(原文)
In the domain of software security testing, Directed Grey-Box Fuzzing (DGF) has garnered widespread attention for its efficient target localization and excellent detection performance. However, existing approaches measure only the physical distance between seed execution paths and target locations, overlooking logical relationships among code segments. This omission can yield redundant or misleading guidance in complex binaries, weakening DGF's real-world effectiveness. To address this, we introduce \textbf{attention distance}, a novel metric that leverages a large language model's contextual analysis to compute attention scores between code elements and reveal their intrinsic connections. Under the same AFLGo configuration -- without altering any fuzzing components other than the distance metric -- replacing physical distances with attention distances across 38 real vulnerability reproduction experiments delivers a \textbf{3.43$\times$} average increase in testing efficiency over the traditional method. Compared to state-of-the-art directed fuzzers DAFL and WindRanger, our approach achieves \textbf{2.89$\times$} and \textbf{7.13$\times$} improvements, respectively. To further validate the generalizability of attention distance, we integrate it into DAFL and WindRanger, where it also consistently enhances their original performance. All related code and datasets are publicly available at https://github.com/TheBinKing/Attention_Distance.git.