Unifying Causal Reinforcement Learning: Survey, Taxonomy, Algorithms and Applications
作者: Cristiano da Costa Cunha, Wei Liu, Tim French, Ajmal Mian
分类: cs.AI
发布日期: 2025-12-19
备注: 26 pages, 14 figures, 5 algorithms
💡 一句话要点
综述因果强化学习:统一视角,分类算法与应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 因果强化学习 因果推理 强化学习 综述 反事实推理
📋 核心要点
- 传统强化学习在复杂环境中泛化能力弱,缺乏可解释性,难以应对分布偏移和混淆变量。
- 因果强化学习通过显式建模因果关系,利用因果推理原则,提升强化学习的鲁棒性和泛化能力。
- 该综述对因果强化学习方法进行分类总结,分析了现有方法的挑战,并展望了未来研究方向。
📝 摘要(中文)
本综述系统性地回顾了因果推理(CI)与强化学习(RL)交叉领域的最新进展。传统强化学习依赖于相关性驱动的决策,在面对分布偏移、混淆变量和动态环境时表现不佳。因果强化学习(CRL)利用因果推理的基本原则,通过显式建模因果关系,为解决这些挑战提供了有希望的方案。我们将现有方法分为因果表示学习、反事实策略优化、离线因果强化学习、因果迁移学习和因果可解释性。通过结构化分析,我们识别了主要挑战,强调了实际应用中的经验性成功,并讨论了开放性问题。最后,我们提出了未来的研究方向,强调了CRL在开发鲁棒、通用和可解释的人工智能系统方面的潜力。
🔬 方法详解
问题定义:传统强化学习方法主要依赖于数据中的相关性进行决策,这使得它们在面对环境变化、存在混淆因素或需要进行策略迁移时表现不佳。这些方法缺乏对因果关系的理解,导致策略脆弱且难以解释。因此,如何将因果推理融入强化学习,以提升策略的鲁棒性、泛化性和可解释性,是该领域的核心问题。
核心思路:该综述的核心思路是将现有的因果强化学习方法进行系统性的分类和总结,从而帮助研究人员更好地理解该领域的发展现状和未来趋势。通过对不同方法的优缺点进行分析,可以为未来的研究提供指导,并促进该领域的发展。
技术框架:该综述将因果强化学习方法分为五个主要类别:因果表示学习、反事实策略优化、离线因果强化学习、因果迁移学习和因果可解释性。每个类别都代表了将因果推理融入强化学习的不同方式。综述对每个类别下的代表性方法进行了详细的介绍和分析。
关键创新:该综述的关键创新在于其对因果强化学习方法的系统性分类和总结。通过将现有方法划分为不同的类别,可以更清晰地了解该领域的研究方向和进展。此外,该综述还对每个类别下的方法进行了优缺点的分析,并提出了未来的研究方向。
关键设计:该综述并没有提出新的算法或模型,而是对现有方法进行总结和分类。因此,没有具体的参数设置、损失函数或网络结构等技术细节需要描述。综述的重点在于对不同方法的思想和原理进行阐述,并分析其在不同应用场景下的表现。
🖼️ 关键图片
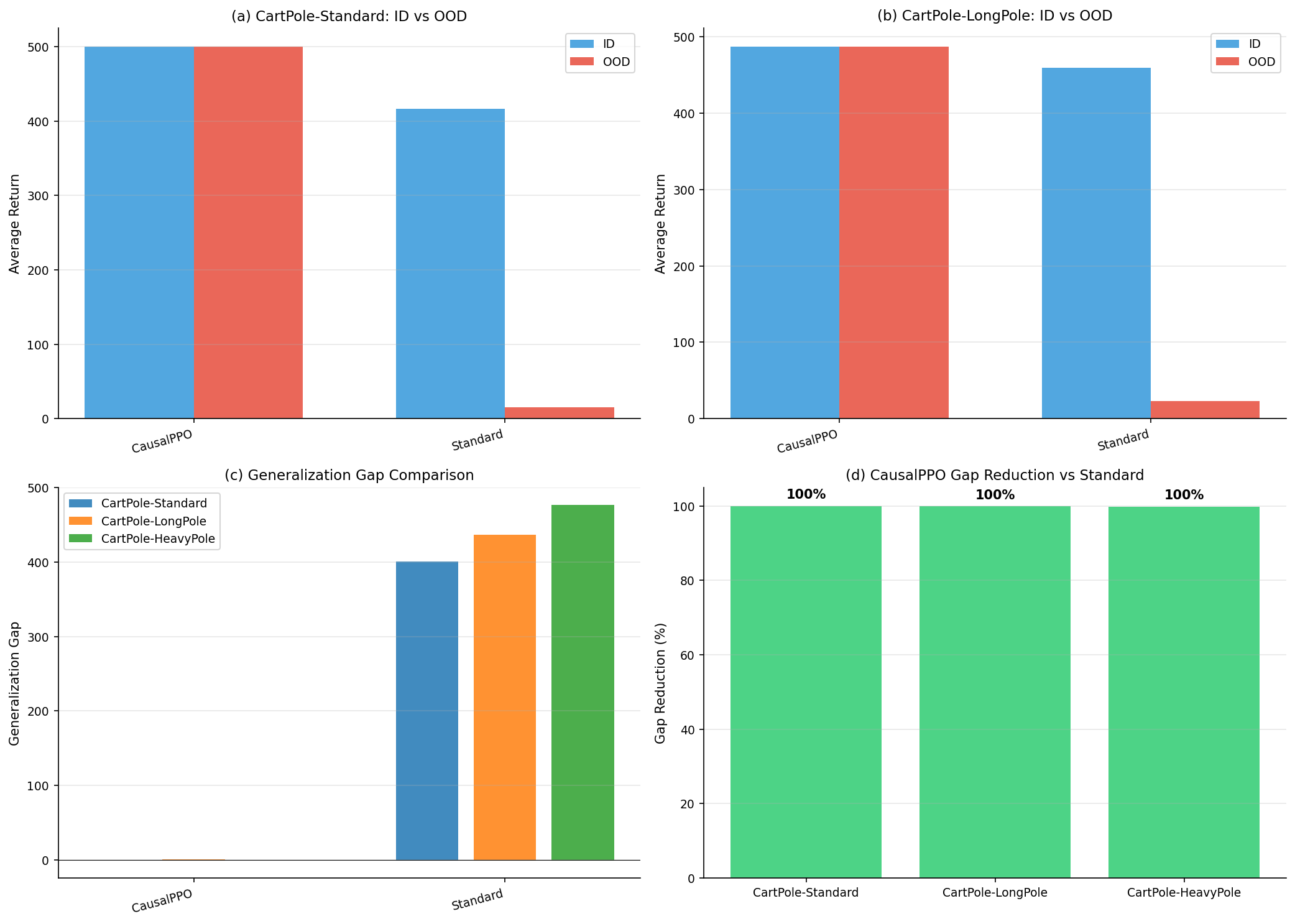
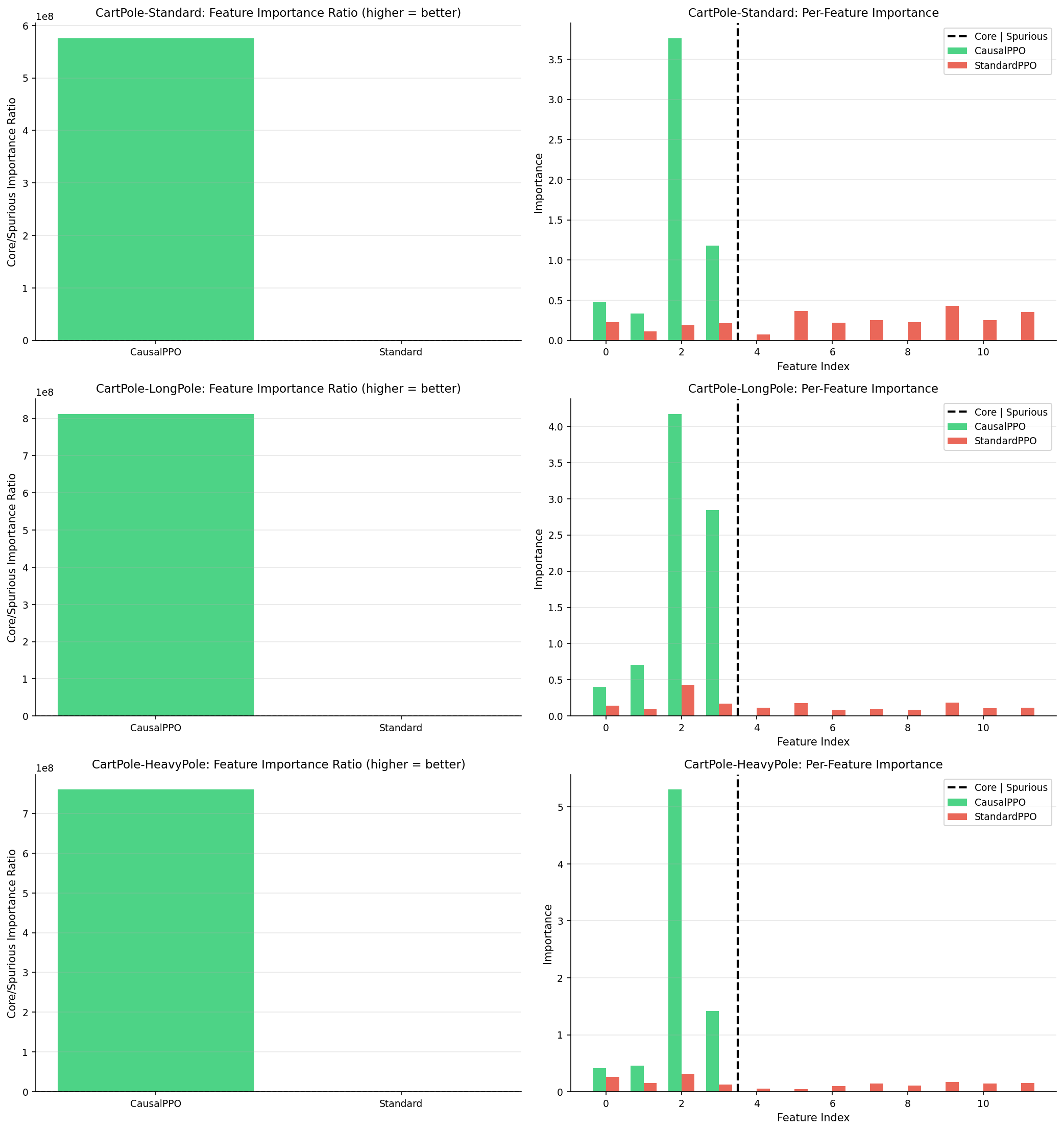
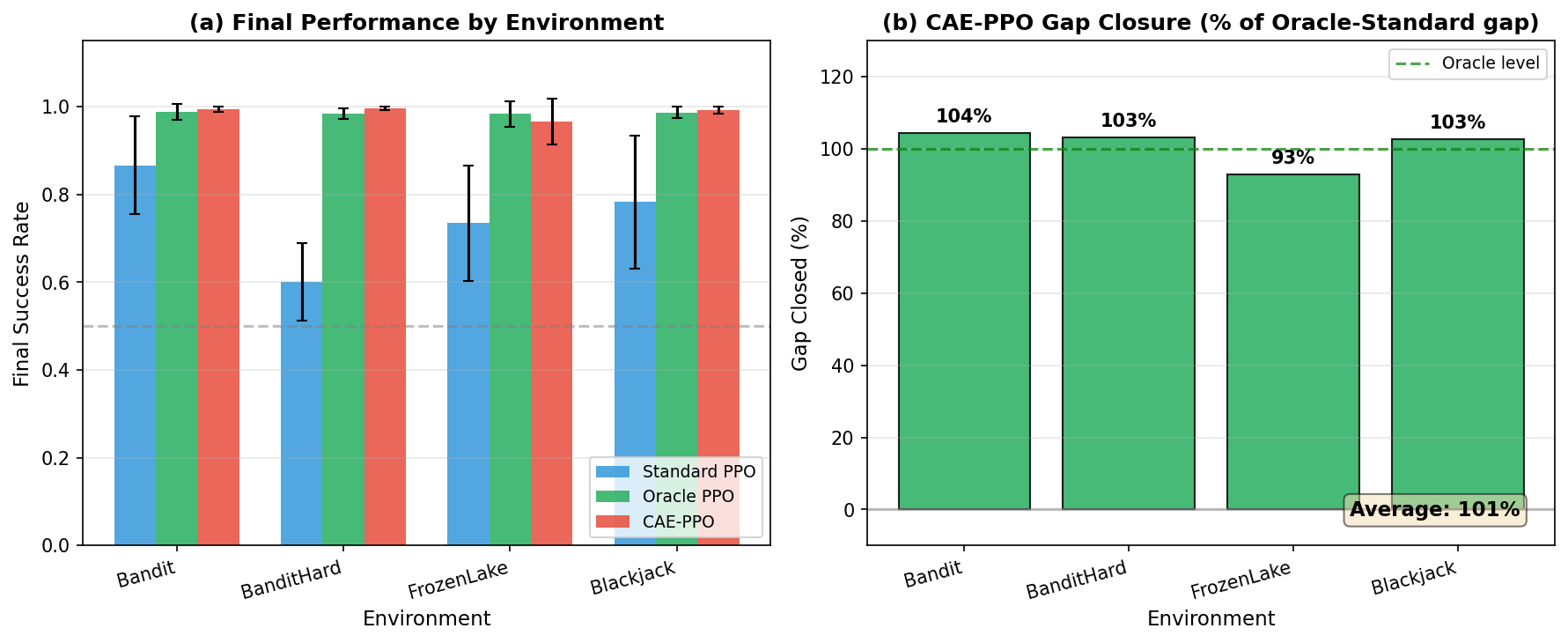
📊 实验亮点
该综述系统地回顾了因果强化学习领域的最新进展,并将其划分为五个主要类别。通过对每个类别下的代表性方法进行分析,揭示了该领域的研究现状和未来趋势。该综述还强调了因果强化学习在实际应用中的成功案例,并指出了该领域面临的挑战和开放性问题。
🎯 应用场景
因果强化学习在许多领域具有广泛的应用前景,例如机器人控制、医疗决策、金融交易和推荐系统。通过利用因果关系,可以开发出更加鲁棒、通用和可解释的智能系统,从而在复杂和动态的环境中做出更好的决策。未来的研究可能会集中在开发更有效的因果推理方法,以及将这些方法应用于更广泛的实际问题。
📄 摘要(原文)
Integrating causal inference (CI) with reinforcement learning (RL) has emerged as a powerful paradigm to address critical limitations in classical RL, including low explainability, lack of robustness and generalization failures. Traditional RL techniques, which typically rely on correlation-driven decision-making, struggle when faced with distribution shifts, confounding variables, and dynamic environments. Causal reinforcement learning (CRL), leveraging the foundational principles of causal inference, offers promising solutions to these challenges by explicitly modeling cause-and-effect relationships. In this survey, we systematically review recent advancements at the intersection of causal inference and RL. We categorize existing approaches into causal representation learning, counterfactual policy optimization, offline causal RL, causal transfer learning, and causal explainability. Through this structured analysis, we identify prevailing challenges, highlight empirical successes in practical applications, and discuss open problems. Finally, we provide future research directions, underscoring the potential of CRL for developing robust, generalizable, and interpretable artificial intelligence systems.