Holistic Evaluation of State-of-the-Art LLMs for Code Generation
作者: Le Zhang, Suresh Kothari
分类: cs.SE, cs.AI
发布日期: 2025-12-19
备注: 13 pages, 9 figures, 6 tables
💡 一句话要点
全面评估大型语言模型在代码生成任务中的性能表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 LLM 性能评估 LeetCode 软件开发 提示工程
📋 核心要点
- 现有代码生成模型在实际应用中仍面临挑战,例如生成的代码可能存在编译错误、运行时错误或逻辑缺陷。
- 该研究通过全面评估多种LLM在代码生成任务中的表现,旨在为开发者提供模型选择和使用方面的指导。
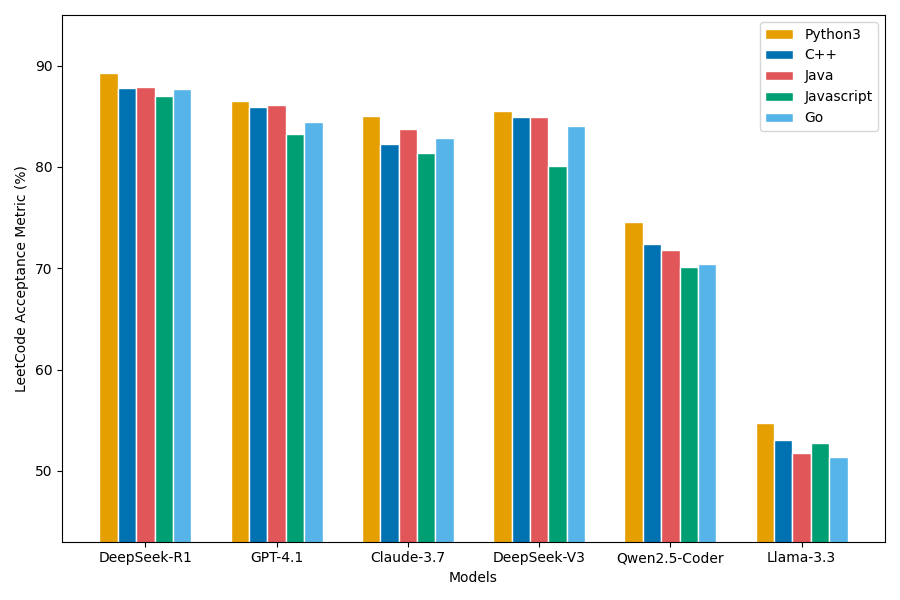
- 实验结果表明,DeepSeek-R1和GPT-4.1在代码生成任务中表现突出,但在不同编程语言和问题类型上仍存在差异。
📝 摘要(中文)
本研究对六个最先进的大型语言模型(LLM)在代码生成方面的性能进行了全面的实证评估,包括通用模型和代码专用模型。我们使用包含五种编程语言的944个真实LeetCode问题的数据库,通过严格的指标评估模型性能:编译时错误、运行时错误、功能性失败和算法次优性。结果表明,不同模型之间存在显著的性能差异,其中DeepSeek-R1和GPT-4.1在正确性、效率和鲁棒性方面始终优于其他模型。通过详细的案例研究,我们识别了常见的失败场景,如语法错误、逻辑缺陷和次优算法,突出了提示工程和人工监督在提高结果中的关键作用。基于这些发现,我们为开发人员和从业者提供了可操作的建议,强调成功部署LLM取决于仔细的模型选择、有效的提示设计和上下文感知的使用,以确保在实际软件开发任务中生成可靠的代码。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估当前最先进的LLM在代码生成任务中的性能问题。现有方法缺乏对多种编程语言和真实场景的全面评估,难以指导开发者选择合适的模型并有效利用LLM进行代码生成。现有方法难以区分不同类型错误,例如编译错误、运行时错误和逻辑错误,无法深入分析模型失败的原因。
核心思路:论文的核心思路是通过构建一个包含多种编程语言和真实LeetCode问题的评测数据集,并设计一套全面的评估指标,来系统性地评估LLM在代码生成任务中的性能。通过案例分析,深入了解模型失败的原因,并为开发者提供可操作的建议。
技术框架:该研究的技术框架主要包括以下几个部分:1) 构建包含944个LeetCode问题的评测数据集,覆盖五种编程语言。2) 选择六个最先进的LLM进行评估,包括通用模型和代码专用模型。3) 设计一套全面的评估指标,包括编译时错误、运行时错误、功能性失败和算法次优性。4) 进行详细的案例研究,分析模型失败的原因。
关键创新:该研究的关键创新在于:1) 构建了一个包含多种编程语言和真实LeetCode问题的评测数据集,更贴近实际应用场景。2) 设计了一套全面的评估指标,能够更细粒度地评估LLM在代码生成任务中的性能。3) 通过案例分析,深入了解模型失败的原因,并为开发者提供可操作的建议。
关键设计:论文的关键设计包括:1) LeetCode问题的选择,确保问题具有代表性和挑战性。2) 评估指标的设计,确保能够全面评估LLM在代码生成任务中的性能。3) 案例研究的选择,确保能够深入了解模型失败的原因。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DeepSeek-R1和GPT-4.1在代码生成任务中表现突出,在正确性、效率和鲁棒性方面优于其他模型。例如,在解决LeetCode问题时,DeepSeek-R1和GPT-4.1的成功率显著高于其他模型。案例研究表明,语法错误、逻辑缺陷和次优算法是LLM代码生成中常见的失败原因。
🎯 应用场景
该研究成果可应用于软件开发、自动化测试、教育等领域。开发者可以根据评估结果选择合适的LLM,并结合提示工程和人工监督,提高代码生成的效率和质量。该研究还可以为LLM的进一步研究和开发提供参考,促进代码生成技术的进步。
📄 摘要(原文)
This study presents a comprehensive empirical evaluation of six state-of-the-art large language models (LLMs) for code generation, including both general-purpose and code-specialized models. Using a dataset of 944 real-world LeetCode problems across five programming languages, we assess model performance using rigorous metrics: compile-time errors, runtime errors, functional failures, and algorithmic suboptimalities. The results reveal significant performance variations, with DeepSeek-R1 and GPT-4.1 consistently outperform others in terms of correctness, efficiency, and robustness. Through detailed case studies, we identify common failure scenarios such as syntax errors, logical flaws, and suboptimal algorithms, highlighting the critical role of prompt engineering and human oversight in improving results. Based on these findings, we provide actionable recommendations for developers and practitioners, emphasizing that successful LLM deployment depends on careful model selection, effective prompt design, and context-aware usage to ensure reliable code generation in real-world software development tasks.