HybridQuestion: Human-AI Collaboration for Identifying High-Impact Research Questions
作者: Keyu Zhao, Fengli Xu, Yong Li, Tie-Yan Liu
分类: cs.HC, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-18
备注: 16 pages, 6 figures, 4 tables
💡 一句话要点
提出HybridQuestion框架,结合人机协作识别高影响力研究问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 高影响力研究问题 大型语言模型 科学发现 AI科学家
📋 核心要点
- 现有方法难以进行战略性、长期评估,无法有效识别高影响力研究问题。
- 提出人机混合框架HybridQuestion,结合AI的数据处理能力与人类专家的价值判断。
- 实验表明,AI在识别已确立的突破方面与人类专家高度一致,但在预测未来问题方面存在差异。
📝 摘要(中文)
“AI科学家”范式通过自动化研究过程的关键阶段(从想法生成到学术写作)正在改变科学研究。这种转变有望加速发现并扩大科学探究的范围。然而,一个关键问题仍然不清楚:AI科学家能否识别出有意义的研究问题?虽然大型语言模型(LLM)已成功应用于特定任务的构思,但它们对过去突破和未来问题进行战略性、长期评估的潜力在很大程度上仍未被探索。为了解决这一差距,我们探索了一种人机混合解决方案,该方案将AI的可扩展数据处理能力与人类专家的价值判断相结合。我们的方法分为三个阶段。第一阶段,AI加速信息收集,利用AI在处理大量文献方面的优势来生成混合信息库。第二阶段,候选问题提出,利用这些综合数据提示六个不同的LLM集成来提出初始候选池,并通过跨模型投票机制进行过滤。第三阶段,混合问题选择,通过逐步增加人工监督的多阶段过滤过程来完善此池。为了验证该系统,我们进行了一项实验,旨在确定2025年的十大科学突破和2026年的十大科学问题,涵盖五个主要学科。我们的分析表明,虽然AI智能体在识别已确立的突破方面与人类专家表现出高度一致性,但在预测未来问题方面,它们表现出更大的差异,这表明人类判断对于评估主观的、前瞻性的挑战仍然至关重要。
🔬 方法详解
问题定义:论文旨在解决AI科学家能否有效识别高影响力研究问题的问题。现有方法,特别是纯粹依赖大型语言模型的方法,在战略性、长期评估以及价值判断方面存在不足,难以准确预测未来的科学突破和重要研究方向。现有方法的痛点在于缺乏人类专家的指导,导致AI在主观性和前瞻性问题上的表现不佳。
核心思路:论文的核心思路是构建一个人机协作的框架,将AI强大的数据处理能力与人类专家的价值判断相结合。通过AI加速信息收集和初步的问题生成,然后通过人类专家的多阶段过滤和选择,最终确定高影响力的研究问题。这种混合方法旨在弥补纯AI方法的不足,提高问题识别的准确性和可靠性。
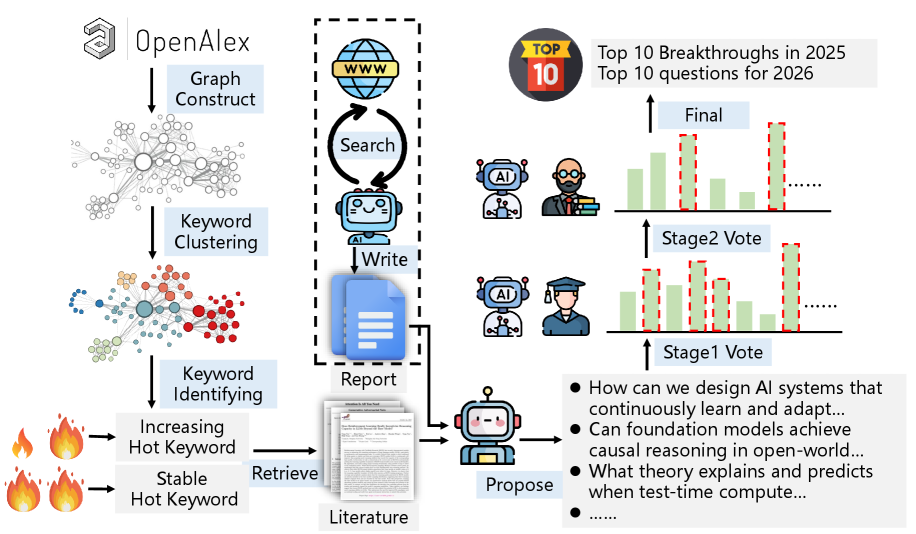
技术框架:HybridQuestion框架包含三个主要阶段:1) AI加速信息收集:利用AI处理大量文献,构建混合信息库。2) 候选问题提出:使用信息库提示多个LLM生成候选问题,并通过跨模型投票进行初步筛选。3) 混合问题选择:通过多阶段过滤,逐步增加人工监督,最终确定高影响力问题。整体流程是从AI主导到人机协作,再到人类主导的转变。
关键创新:该论文的关键创新在于提出了一种人机混合的框架,用于识别高影响力研究问题。与以往纯粹依赖AI或人类专家的方法不同,HybridQuestion框架充分利用了AI和人类的优势,实现了优势互补。此外,该框架还采用了跨模型投票机制,提高了候选问题生成的鲁棒性。
关键设计:在AI加速信息收集阶段,使用了特定的信息检索和抽取技术,以确保信息库的质量和完整性。在候选问题提出阶段,使用了六个不同的LLM,并设计了特定的提示语,以引导LLM生成高质量的候选问题。在混合问题选择阶段,设计了多阶段过滤流程,并制定了明确的评估标准,以确保最终选择的问题具有高影响力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AI在识别已确立的科学突破方面与人类专家具有高度一致性。然而,在预测未来科学问题方面,AI与人类专家的差异较大,表明人类判断在评估主观性和前瞻性问题方面仍然至关重要。该研究验证了人机混合方法在识别高影响力研究问题方面的有效性。
🎯 应用场景
该研究成果可应用于科学研究规划、技术趋势预测、投资决策等领域。通过人机协作,可以更有效地识别具有高影响力的研究方向,加速科学发现和技术创新。该方法还可以用于辅助政府部门制定科技政策,引导科研资源投入。
📄 摘要(原文)
The "AI Scientist" paradigm is transforming scientific research by automating key stages of the research process, from idea generation to scholarly writing. This shift is expected to accelerate discovery and expand the scope of scientific inquiry. However, a key question remains unclear: can AI scientists identify meaningful research questions? While Large Language Models (LLMs) have been applied successfully to task-specific ideation, their potential to conduct strategic, long-term assessments of past breakthroughs and future questions remains largely unexplored. To address this gap, we explore a human-AI hybrid solution that integrates the scalable data processing capabilities of AI with the value judgment of human experts. Our methodology is structured in three phases. The first phase, AI-Accelerated Information Gathering, leverages AI's advantage in processing vast amounts of literature to generate a hybrid information base. The second phase, Candidate Question Proposing, utilizes this synthesized data to prompt an ensemble of six diverse LLMs to propose an initial candidate pool, filtered via a cross-model voting mechanism. The third phase, Hybrid Question Selection, refines this pool through a multi-stage filtering process that progressively increases human oversight. To validate this system, we conducted an experiment aiming to identify the Top 10 Scientific Breakthroughs of 2025 and the Top 10 Scientific Questions for 2026 across five major disciplines. Our analysis reveals that while AI agents demonstrate high alignment with human experts in recognizing established breakthroughs, they exhibit greater divergence in forecasting prospective questions, suggesting that human judgment remains crucial for evaluating subjective, forward-looking challenges.