Reinforcement Learning for Self-Improving Agent with Skill Library
作者: Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, Lin Lee Cheong
分类: cs.AI
发布日期: 2025-12-18
💡 一句话要点
提出基于强化学习的SAGE框架,提升LLM智能体在技能库应用中的自进化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 技能库 大型语言模型 智能体 自进化 GRPO AppWorld
📋 核心要点
- 现有基于LLM的智能体在技能库应用中,依赖LLM提示,难以持续改进和适应新环境。
- 提出SAGE框架,利用强化学习系统性地将技能融入学习,实现智能体的自进化。
- 实验表明,SAGE在AppWorld中显著提升了场景目标完成率,并降低了交互成本。
📝 摘要(中文)
基于大型语言模型(LLM)的智能体在复杂推理和多轮交互方面表现出色,但在新环境中部署时,持续改进和适应能力不足。一种有前景的方法是实施技能库,使智能体能够学习、验证和应用新技能。然而,当前的技能库方法主要依赖于LLM提示,使得技能库的实现具有挑战性。为了克服这些挑战,我们提出了一种基于强化学习(RL)的方法,以增强智能体利用技能库进行自我改进的能力。具体来说,我们引入了用于自我进化的技能增强GRPO(SAGE),这是一种新颖的RL框架,可系统地将技能纳入学习中。该框架的关键组件是顺序展开,它在每次展开中,于一系列相似任务中迭代部署智能体。当智能体在任务链中导航时,从先前任务生成的技能会累积在库中,并可用于后续任务。此外,该框架通过技能集成奖励来增强技能的生成和利用,该奖励补充了基于结果的原始奖励。在AppWorld上的实验结果表明,SAGE应用于经过监督微调并具有专家经验的模型时,场景目标完成率提高了8.9%,同时交互步骤减少了26%,生成的token减少了59%,在准确性和效率方面均大大优于现有方法。
🔬 方法详解
问题定义:论文旨在解决LLM智能体在技能库应用中,难以持续改进和适应新环境的问题。现有方法主要依赖LLM提示,缺乏有效的技能学习和利用机制,导致性能不稳定且效率低下。
核心思路:论文的核心思路是利用强化学习(RL)来增强智能体的自进化能力,通过技能库的构建和有效利用,使智能体能够在新环境中学习、验证和应用新技能。通过RL,智能体可以根据环境反馈不断优化技能,从而实现持续改进。
技术框架:SAGE框架包含以下主要模块:1) 顺序展开(Sequential Rollout):智能体在一系列相似任务中迭代部署,技能在任务链中累积。2) 技能库(Skill Library):存储从先前任务生成的技能,供后续任务使用。3) 技能集成奖励(Skill-integrated Reward):补充原始的基于结果的奖励,鼓励技能的生成和利用。整体流程是,智能体在任务链中执行任务,生成技能并存储到技能库中,同时根据环境反馈和技能集成奖励进行学习,优化策略。
关键创新:SAGE的关键创新在于将强化学习与技能库相结合,提出了一种系统性的技能学习和利用框架。与现有方法相比,SAGE不依赖于LLM提示,而是通过RL自主学习技能,从而提高了智能体的适应性和泛化能力。此外,技能集成奖励的设计也有效地促进了技能的生成和利用。
关键设计:SAGE使用GRPO(Generalized Policy Optimization)作为基础的RL算法。技能集成奖励的设计是关键,它结合了任务完成的奖励和技能使用的奖励,具体形式未知。顺序展开的实现细节,例如任务链的构建方式和任务之间的相似度度量,也对最终性能有重要影响。具体的网络结构和参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片

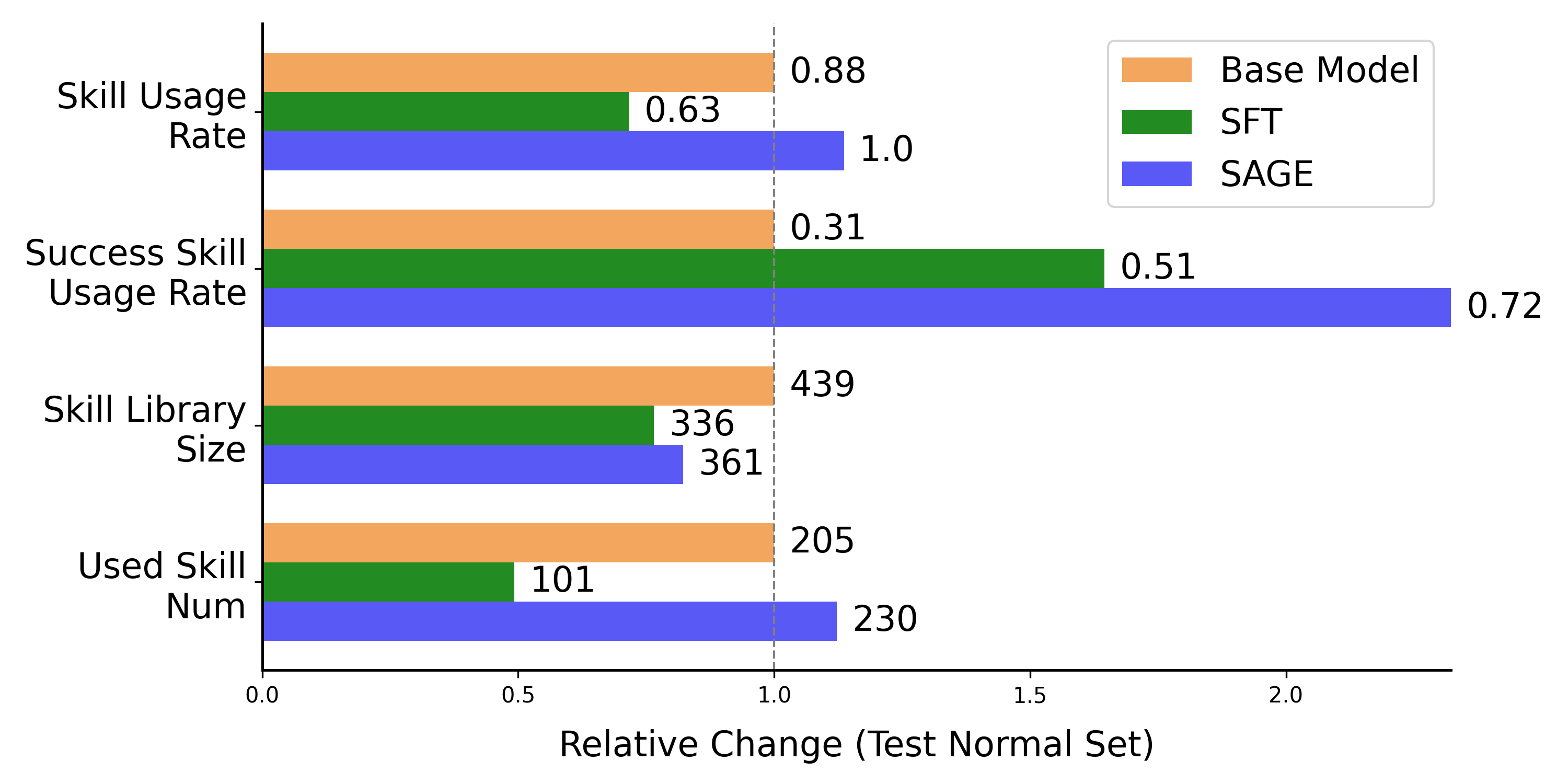

📊 实验亮点
SAGE框架在AppWorld上的实验结果表明,与现有方法相比,场景目标完成率提高了8.9%,同时交互步骤减少了26%,生成的token减少了59%。这些数据表明,SAGE在准确性和效率方面均取得了显著提升,验证了其有效性。
🎯 应用场景
该研究成果可应用于各种需要智能体具备持续学习和适应能力的场景,例如智能客服、自动化任务处理、游戏AI等。通过技能库的构建和强化学习的优化,智能体可以不断提升自身能力,更好地完成复杂任务,提高工作效率,降低人工成本。未来,该技术有望在更多领域得到应用,推动人工智能的发展。
📄 摘要(原文)
Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.