A Solver-in-the-Loop Framework for Improving LLMs on Answer Set Programming for Logic Puzzle Solving
作者: Timo Pierre Schrader, Lukas Lange, Tobias Kaminski, Simon Razniewski, Annemarie Friedrich
分类: cs.AI, cs.CL
发布日期: 2025-12-18
备注: 15 pages, 7 figures, accepted at AAAI'26
💡 一句话要点
提出ASP求解器在环框架,提升LLM在解答集编程逻辑谜题中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 解答集编程 大型语言模型 求解器在环 指令调优 逻辑谜题
📋 核心要点
- LLM在通用编程语言上表现出色,但在领域特定语言(如ASP)的代码生成方面仍面临挑战,主要原因是训练数据不足。
- 论文提出一种ASP求解器在环的方法,通过求解器的反馈指导LLM进行指令调优,从而提升LLM生成ASP代码的能力。
- 实验结果表明,该方法在两种不同的提示设置和两个数据集上均取得了持续的性能提升,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)的兴起激发了人们对编码助手的兴趣。虽然通用编程语言得到了很好的支持,但为领域特定语言生成代码对LLM来说仍然是一个具有挑战性的问题。本文重点研究基于LLM的解答集编程(ASP)代码生成,这是一种特别有效的方法,用于寻找组合搜索问题的解决方案。LLM在ASP代码生成方面的有效性目前受到其初始预训练阶段所见示例数量有限的阻碍。本文介绍了一种新颖的ASP求解器在环方法,用于对LLM进行求解器引导的指令调优,以解决ASP代码生成中固有的高度复杂的语义解析任务。我们的方法只需要自然语言的问题规范及其解决方案。具体来说,我们从LLM中抽取ASP语句用于程序延续,以解开逻辑谜题。利用声明式ASP编程的特殊属性,即部分编码逐渐缩小解决方案空间,我们根据求解器的反馈将它们分为选择和拒绝的实例。然后,我们应用监督微调来训练LLM在整理的数据上,并使用包括best-of-N抽样的求解器引导搜索进一步提高鲁棒性。我们的实验证明了在两个数据集上的两种不同提示设置中,性能均得到了持续的提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成解答集编程(ASP)代码以解决逻辑谜题时遇到的困难。现有的LLM在ASP代码生成方面的性能受限于预训练阶段接触到的ASP代码示例数量不足,导致其难以理解ASP的语义并生成正确的代码。
核心思路:论文的核心思路是利用ASP求解器作为反馈机制,指导LLM生成更有效的ASP代码。通过将求解器集成到训练循环中,可以根据求解器的结果(成功或失败)来判断LLM生成的代码片段的质量,并以此来调整LLM的参数。这种“求解器在环”的方法能够有效地利用有限的训练数据,提升LLM在ASP代码生成方面的性能。
技术框架:该框架包含以下主要步骤:1) 使用LLM生成ASP代码片段,用于延续已有的程序;2) 使用ASP求解器对生成的代码片段进行评估,判断其是否能够导致正确的解决方案;3) 根据求解器的反馈,将生成的代码片段分为“选择”和“拒绝”两类;4) 使用这些分类后的数据对LLM进行监督微调,提升其生成高质量ASP代码的能力;5) 使用求解器引导的搜索(包括best-of-N采样)进一步提高模型的鲁棒性。
关键创新:该方法最重要的创新点在于将ASP求解器集成到LLM的训练循环中,形成一个“求解器在环”的框架。这种方法能够有效地利用求解器的反馈来指导LLM的学习,使其能够更好地理解ASP的语义并生成更有效的代码。与传统的监督学习方法相比,该方法能够更有效地利用有限的训练数据,并取得更好的性能。
关键设计:该方法的关键设计包括:1) 使用best-of-N采样来生成多个候选代码片段,并选择其中一个;2) 使用求解器的反馈(成功或失败)作为监督信号,对LLM进行微调;3) 利用ASP编程的特性,即部分编码可以逐渐缩小解决方案空间,从而更有效地利用求解器的反馈。
🖼️ 关键图片

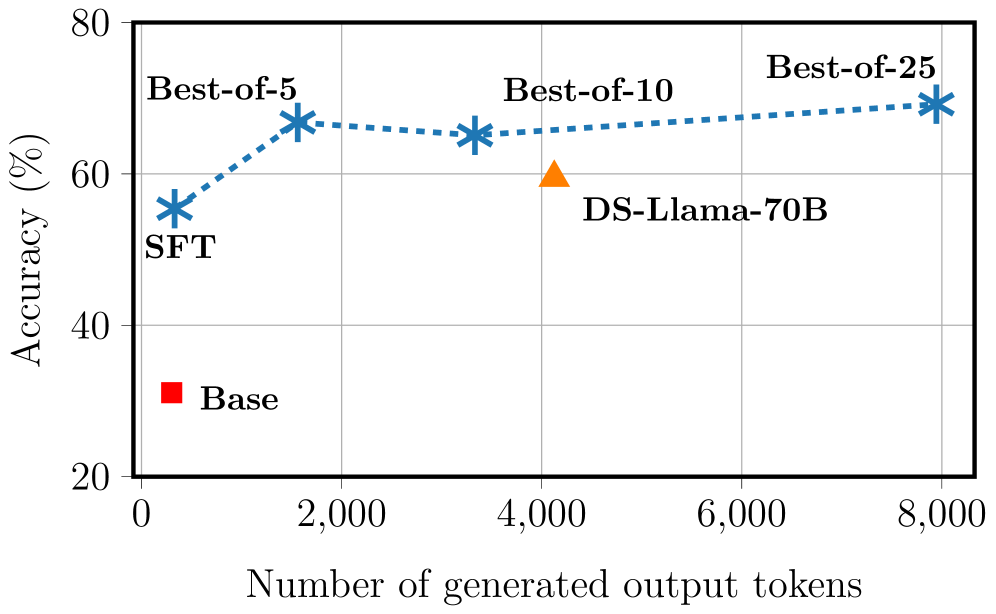

📊 实验亮点
实验结果表明,该方法在两种不同的提示设置和两个数据集上均取得了持续的性能提升。具体来说,该方法能够显著提高LLM生成正确ASP代码的概率,从而提升其解决逻辑谜题的能力。与没有使用求解器在环的方法相比,该方法能够取得明显的性能优势。
🎯 应用场景
该研究成果可应用于自动化程序生成、逻辑推理、问题求解等领域。通过提升LLM在领域特定语言代码生成方面的能力,可以降低开发成本,提高开发效率。未来,该方法有望扩展到其他领域特定语言,并应用于更复杂的实际问题。
📄 摘要(原文)
The rise of large language models (LLMs) has sparked interest in coding assistants. While general-purpose programming languages are well supported, generating code for domain-specific languages remains a challenging problem for LLMs. In this paper, we focus on the LLM-based generation of code for Answer Set Programming (ASP), a particularly effective approach for finding solutions to combinatorial search problems. The effectiveness of LLMs in ASP code generation is currently hindered by the limited number of examples seen during their initial pre-training phase. In this paper, we introduce a novel ASP-solver-in-the-loop approach for solver-guided instruction-tuning of LLMs to addressing the highly complex semantic parsing task inherent in ASP code generation. Our method only requires problem specifications in natural language and their solutions. Specifically, we sample ASP statements for program continuations from LLMs for unriddling logic puzzles. Leveraging the special property of declarative ASP programming that partial encodings increasingly narrow down the solution space, we categorize them into chosen and rejected instances based on solver feedback. We then apply supervised fine-tuning to train LLMs on the curated data and further improve robustness using a solver-guided search that includes best-of-N sampling. Our experiments demonstrate consistent improvements in two distinct prompting settings on two datasets.