Generative Adversarial Reasoner: Enhancing LLM Reasoning with Adversarial Reinforcement Learning
作者: Qihao Liu, Luoxin Ye, Wufei Ma, Yu-Cheng Chou, Alan Yuille
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-12-18 (更新: 2025-12-26)
备注: V2: Added links to the code-generation results and additional details in the appendix
💡 一句话要点
提出生成对抗推理器,通过对抗强化学习提升LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 对抗学习 数学推理 推理器 判别器 奖励塑造
📋 核心要点
- 现有LLM在数学推理方面表现出色,但仍存在计算错误、逻辑脆弱和表面合理但无效的步骤等问题。
- 提出生成对抗推理器,通过对抗强化学习协同训练LLM推理器和判别器,利用判别器提供的细粒度反馈提升推理能力。
- 实验表明,该方法在多个数学基准测试中优于现有强化学习方法,并在AIME24数据集上取得了显著提升。
📝 摘要(中文)
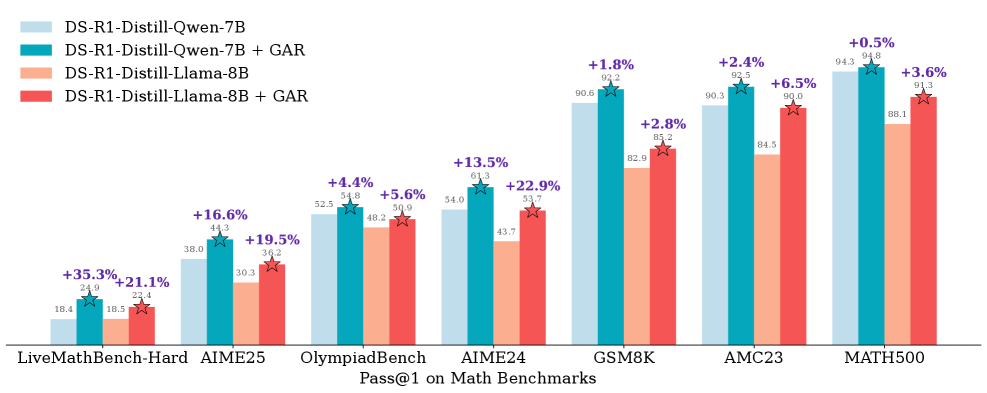
本文提出了一种名为生成对抗推理器(Generative Adversarial Reasoner)的在线联合训练框架,旨在通过对抗强化学习协同进化LLM推理器和基于LLM的判别器,从而增强LLM的推理能力。该框架采用计算高效的审查机制,将每个推理链划分为逻辑完整的、长度相当的片段,判别器使用简洁、结构化的理由评估每个片段的合理性。学习过程耦合了互补信号:LLM推理器因产生逻辑一致且能得出正确答案的步骤而获得奖励,而判别器因正确检测到推理过程中的错误或区分推理轨迹而获得奖励。这产生了密集的、良好校准的、在线的步骤级别奖励,补充了稀疏的精确匹配信号,改善了信用分配,提高了样本效率,并增强了LLM的整体推理质量。在各种数学基准测试中,该方法相对于使用标准RL后训练的强大基线,实现了持续的收益。具体而言,在AIME24上,我们将DeepSeek-R1-Distill-Qwen-7B从54.0提高到61.3(+7.3),将DeepSeek-R1-Distill-Llama-8B从43.7提高到53.7(+10.0)。模块化判别器还能够灵活地进行奖励塑造,以实现诸如教师知识蒸馏、偏好对齐和基于数学证明的推理等目标。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在数学推理过程中出现的逻辑错误、计算错误以及推理步骤无效等问题。现有方法,尤其是依赖稀疏奖励的强化学习方法,在信用分配和样本效率方面存在不足,难以有效提升LLM的推理能力。
核心思路:论文的核心思路是通过对抗强化学习,同时训练一个LLM推理器和一个LLM判别器。推理器负责生成推理步骤,判别器负责评估推理步骤的合理性并提供反馈。这种对抗机制能够提供更密集、更细粒度的奖励信号,从而改善信用分配,提高样本效率,并最终提升LLM的推理质量。
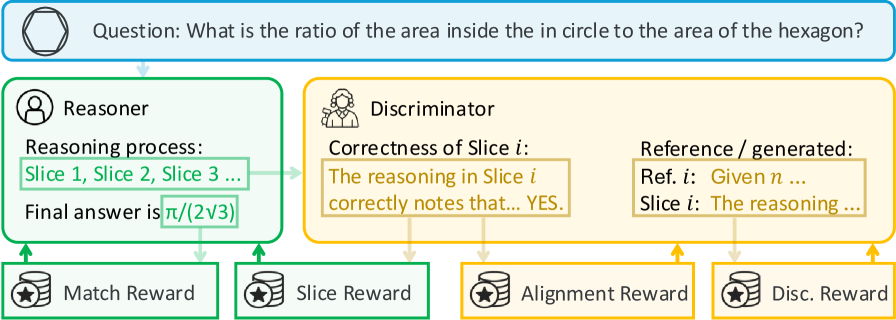
技术框架:整体框架包含两个主要模块:LLM推理器和LLM判别器。推理器负责生成推理链,推理链被分割成多个逻辑完整的片段。判别器对每个片段进行评估,并给出结构化的理由。推理器根据判别器的反馈获得奖励,判别器根据正确识别错误推理步骤获得奖励。整个训练过程采用在线策略(on-policy)强化学习。
关键创新:最重要的技术创新点是引入了对抗学习机制,利用判别器提供细粒度的奖励信号。与传统的依赖稀疏奖励的强化学习方法相比,该方法能够更有效地指导推理器的学习,并提高样本效率。此外,模块化的判别器设计使得可以灵活地进行奖励塑造,以适应不同的目标,例如教师知识蒸馏和偏好对齐。
关键设计:论文设计了一个计算高效的审查机制,将推理链分割成逻辑完整的片段,以便判别器能够更准确地评估每个片段的合理性。判别器输出结构化的理由,为推理器提供更丰富的反馈信息。奖励函数的设计考虑了推理器生成正确答案和判别器正确识别错误推理步骤的情况,从而鼓励推理器生成更合理的推理链,并鼓励判别器更准确地评估推理步骤。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数学基准测试中取得了显著提升。在AIME24数据集上,DeepSeek-R1-Distill-Qwen-7B模型的准确率从54.0%提高到61.3%(+7.3%),DeepSeek-R1-Distill-Llama-8B模型的准确率从43.7%提高到53.7%(+10.0%)。这些结果表明,该方法能够有效地提升LLM的推理能力。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如数学问题求解、科学研究、金融分析等。通过提升LLM的推理能力,可以提高自动化决策的准确性和可靠性,并为人类提供更智能的辅助工具。未来,该方法可以扩展到其他类型的推理任务,例如常识推理和逻辑推理。
📄 摘要(原文)
Large language models (LLMs) with explicit reasoning capabilities excel at mathematical reasoning yet still commit process errors, such as incorrect calculations, brittle logic, and superficially plausible but invalid steps. In this paper, we introduce Generative Adversarial Reasoner, an on-policy joint training framework designed to enhance reasoning by co-evolving an LLM reasoner and an LLM-based discriminator through adversarial reinforcement learning. A compute-efficient review schedule partitions each reasoning chain into logically complete slices of comparable length, and the discriminator evaluates each slice's soundness with concise, structured justifications. Learning couples complementary signals: the LLM reasoner is rewarded for logically consistent steps that yield correct answers, while the discriminator earns rewards for correctly detecting errors or distinguishing traces in the reasoning process. This produces dense, well-calibrated, on-policy step-level rewards that supplement sparse exact-match signals, improving credit assignment, increasing sample efficiency, and enhancing overall reasoning quality of LLMs. Across various mathematical benchmarks, the method delivers consistent gains over strong baselines with standard RL post-training. Specifically, on AIME24, we improve DeepSeek-R1-Distill-Qwen-7B from 54.0 to 61.3 (+7.3) and DeepSeek-R1-Distill-Llama-8B from 43.7 to 53.7 (+10.0). The modular discriminator also enables flexible reward shaping for objectives such as teacher distillation, preference alignment, and mathematical proof-based reasoning.