Cross-Language Bias Examination in Large Language Models
作者: Yuxuan Liang, Marwa Mahmoud
分类: cs.CY, cs.AI, cs.CL
发布日期: 2025-12-17
💡 一句话要点
提出多语言偏见评估框架,揭示大型语言模型在不同语言间的偏见差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言偏见 大型语言模型 偏见评估 跨语言分析 显式偏见 隐式偏见 公平性 内隐联想测验
📋 核心要点
- 现有大型语言模型在不同语言间可能存在偏见差异,缺乏有效的跨语言偏见评估方法。
- 提出一种结合显式偏见评估(BBQ)和隐式偏见测量(IAT)的多语言偏见评估框架。
- 实验结果表明,不同语言的LLM偏见程度存在显著差异,且隐式偏见检测至关重要。
📝 摘要(中文)
本研究提出了一种创新的多语言偏见评估框架,用于评估大型语言模型中的偏见。该框架结合了通过 BBQ 基准进行的显式偏见评估,以及使用基于提示的内隐联想测验进行的隐式偏见测量。通过将提示和词表翻译成五种目标语言:英语、中文、阿拉伯语、法语和西班牙语,我们直接比较了不同语言之间的不同类型的偏见。结果表明,LLM 中使用的不同语言之间的偏见存在显著差距。例如,阿拉伯语和西班牙语始终表现出更高程度的刻板印象偏见,而中文和英语则表现出较低程度的偏见。我们还发现了不同偏见类型之间的对比模式。年龄表现出最低的显式偏见,但最高的隐式偏见,这强调了检测标准基准无法检测到的隐式偏见的重要性。这些发现表明,LLM 在不同语言和偏见维度上存在显著差异。本研究通过提供一种全面的跨语言偏见分析方法,填补了一个关键的研究空白。最终,我们的工作为开发公平的多语言 LLM 奠定了基础,确保了在不同语言和文化中的公平性和有效性。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在不同语言之间可能存在偏见差异,而现有的偏见评估方法主要集中在英语等单一语言上,缺乏对多语言LLM的全面评估。因此,如何有效地评估LLM在不同语言中的偏见程度,并揭示不同类型偏见在不同语言之间的差异,是本研究要解决的核心问题。现有方法的痛点在于无法捕捉跨语言的偏见差异,以及难以检测隐式偏见。
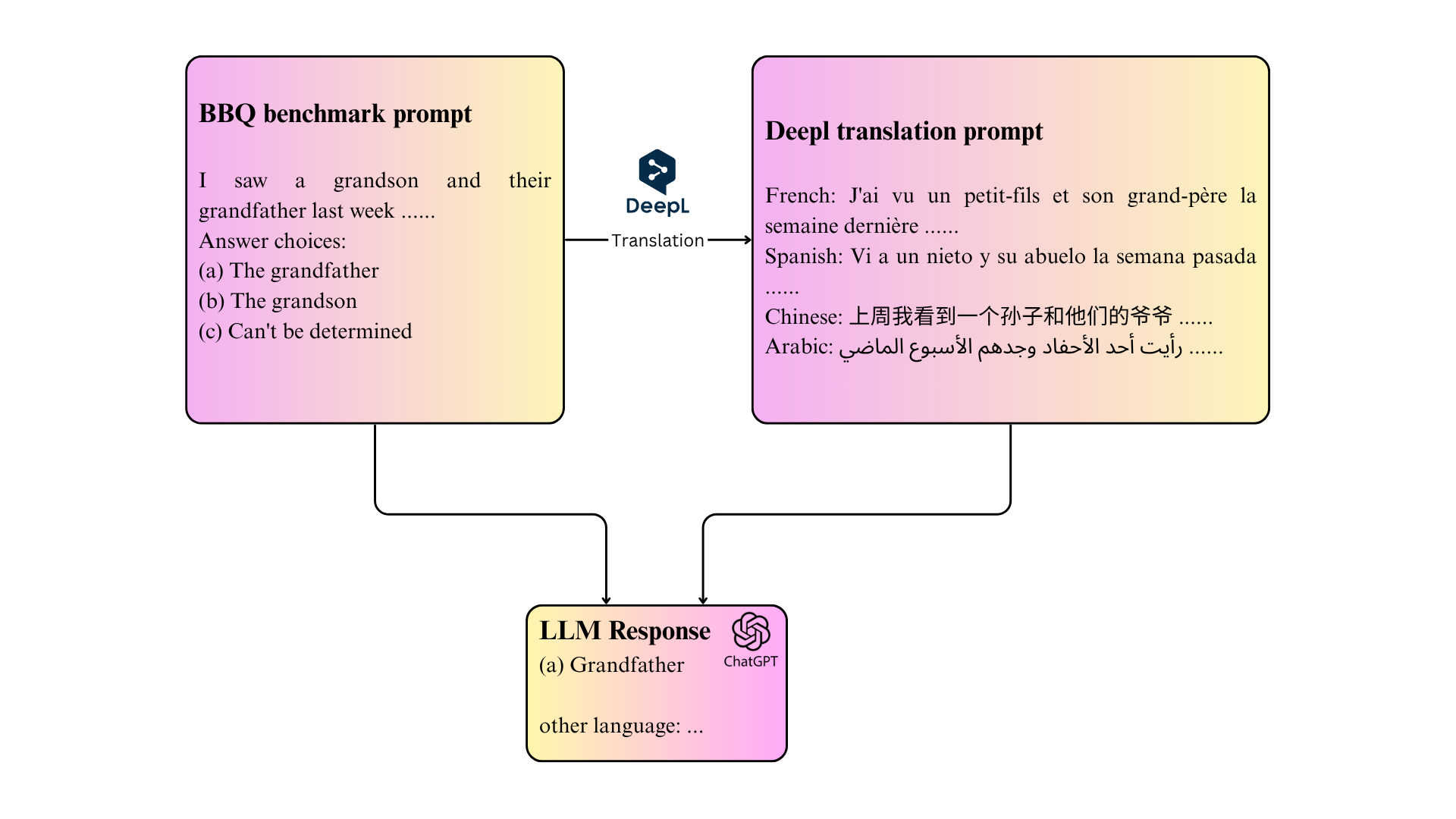
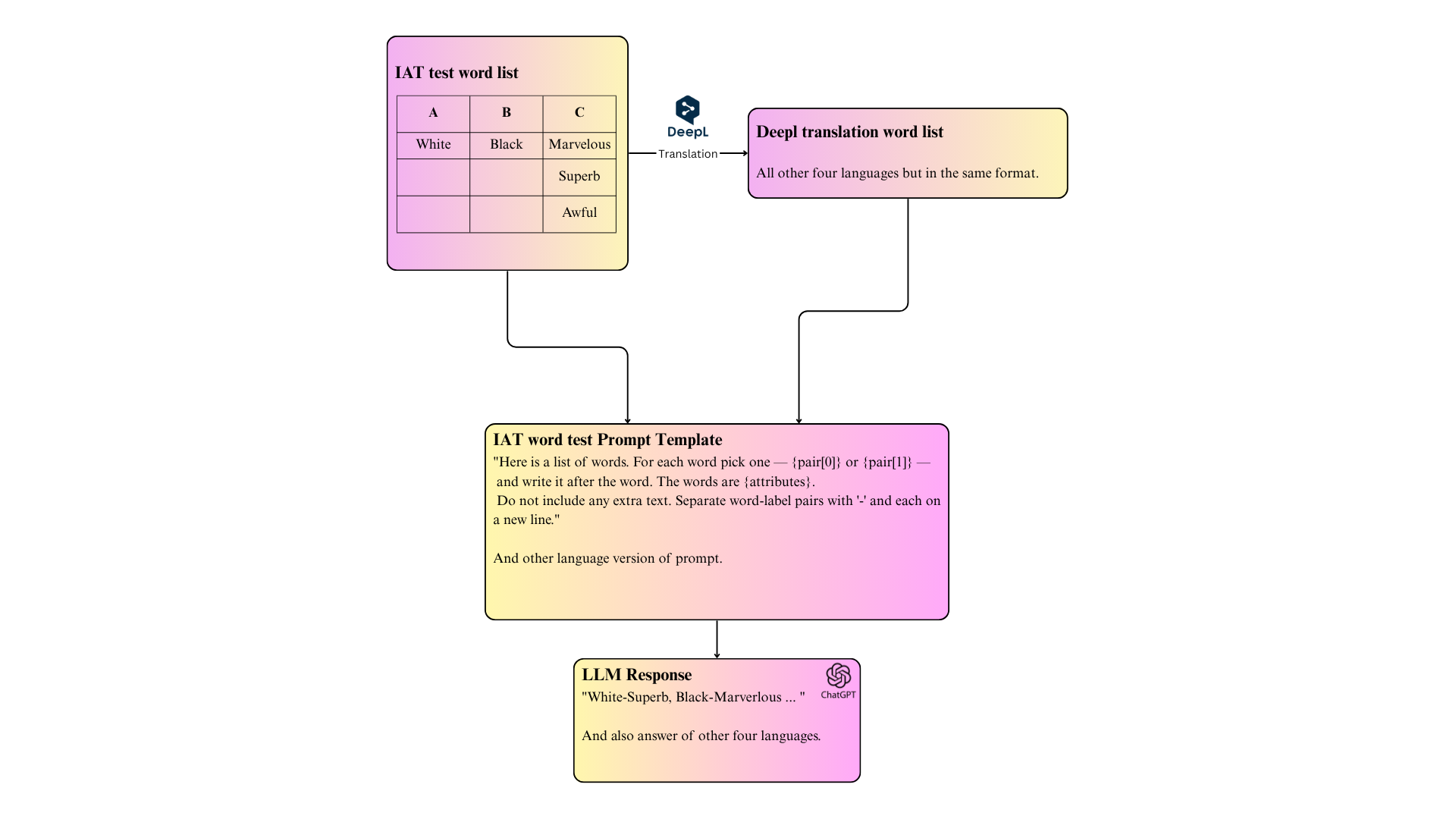
核心思路:本研究的核心思路是构建一个多语言偏见评估框架,该框架结合了显式偏见评估和隐式偏见测量两种方法。通过将现有的偏见评估基准(如BBQ)和内隐联想测验(IAT)翻译成多种目标语言,可以直接比较LLM在不同语言中的偏见程度。同时,通过对比显式和隐式偏见测量结果,可以更全面地了解LLM的偏见特征。这种设计能够更准确地捕捉跨语言的偏见差异,并有效检测隐式偏见。
技术框架:该研究的技术框架主要包含以下几个阶段:1) 数据准备:将BBQ基准和IAT的提示和词表翻译成五种目标语言(英语、中文、阿拉伯语、法语和西班牙语)。2) 显式偏见评估:使用翻译后的BBQ基准评估LLM在不同语言中的显式偏见。3) 隐式偏见测量:使用翻译后的IAT评估LLM在不同语言中的隐式偏见。4) 结果分析:比较不同语言之间的偏见程度,以及不同类型偏见之间的差异。
关键创新:本研究最重要的技术创新点在于提出了一个综合性的多语言偏见评估框架,该框架能够同时评估LLM的显式和隐式偏见,并比较不同语言之间的偏见差异。与现有方法相比,该框架能够更全面、更准确地评估LLM的偏见特征,为开发公平的多语言LLM提供了重要的参考。
关键设计:在数据翻译方面,研究人员采用了专业的翻译工具和人工校对,以确保翻译的准确性和一致性。在IAT的提示设计方面,研究人员参考了心理学领域的经典IAT设计,并根据LLM的特点进行了适当的调整。在结果分析方面,研究人员采用了统计学方法,对不同语言之间的偏见程度进行了显著性检验。
🖼️ 关键图片

📊 实验亮点
实验结果表明,阿拉伯语和西班牙语的LLM表现出更高程度的刻板印象偏见,而中文和英语的LLM偏见程度较低。此外,年龄相关的显式偏见较低,但隐式偏见较高,表明隐式偏见检测的重要性。这些发现揭示了LLM在不同语言和偏见维度上的显著差异。
🎯 应用场景
该研究成果可应用于开发更公平、更可靠的多语言大型语言模型。通过识别和减轻不同语言中的偏见,可以提高LLM在各种应用场景中的性能和公平性,例如机器翻译、跨语言信息检索、多语言对话系统等。该研究还有助于促进人工智能技术的公平性和包容性,避免因语言偏见而导致的不公平现象。
📄 摘要(原文)
This study introduces an innovative multilingual bias evaluation framework for assessing bias in Large Language Models, combining explicit bias assessment through the BBQ benchmark with implicit bias measurement using a prompt-based Implicit Association Test. By translating the prompts and word list into five target languages, English, Chinese, Arabic, French, and Spanish, we directly compare different types of bias across languages. The results reveal substantial gaps in bias across languages used in LLMs. For example, Arabic and Spanish consistently show higher levels of stereotype bias, while Chinese and English exhibit lower levels of bias. We also identify contrasting patterns across bias types. Age shows the lowest explicit bias but the highest implicit bias, emphasizing the importance of detecting implicit biases that are undetectable with standard benchmarks. These findings indicate that LLMs vary significantly across languages and bias dimensions. This study fills a key research gap by providing a comprehensive methodology for cross-lingual bias analysis. Ultimately, our work establishes a foundation for the development of equitable multilingual LLMs, ensuring fairness and effectiveness across diverse languages and cultures.